
LightGBM是个什么东东?好像很耳熟啊,怎么玩啊?如何调参?一文搞定!
前几天分享了几篇梯度提升算法,随机森林相关的文章,大家很喜欢,反馈也很好,那么今天再接再厉,给大家带来一篇LightGBM的文章,既有梯度提升,又有随机森林,这可是个神器,号称Kaggle必备!不过大家去看官方文档的话,估计会被几百个参数吓尿。其实没那么复杂,看完你就明白了!
机器学习是世界上发展最快的领域。每天都会出现大量的新算法,有些不怎么样,有些非常成功。我正在接触一个非常成功的机器学习算法,LightGBM。
写这篇博客的初衷是什么?
当我在做Kaggle比赛的时候,我用过很多的强大的算法,LightGBM是其中之一。LightGBM算法相等的新,网上也没有什么相关的资源。对于初学者来说,很难从文档中长长的列表中选择合适的参数。为了帮助新人,我来写这个博客。
我尽量让这个博客简短,太多的信息会把你绕晕的。
LightGBM是什么?
LightGBM是一个梯度提升框架,使用基于树的学习算法。
和其他的基于树的算法有什么不同?
LightGBM树的生长方式是垂直方向的,其他的算法都是水平方向的,也就是说Light GBM生长的是树的叶子,其他的算法生长的是树的层次。LightGBM选择具有最大误差的树叶进行生长,当生长同样的树叶,生长叶子的算法可以比基于层的算法减少更多的loss。
下面的图解释了LightGBM和其他的提升算法的实现。
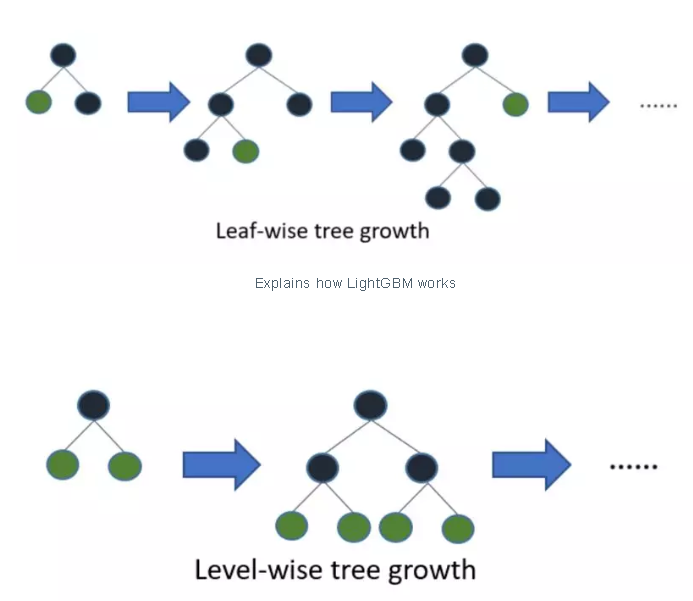
为什么LightGBM这么受欢迎?
数据的数量每天都在增加,对于传统的数据科学算法来说,很难快速的给出结果。LightGBM的前缀‘Light’表示速度很快。LightGBM可以处理大量的数据,运行时占用很少的内存。另外一个理由,LightGBM为什么这么受欢迎是因为它把重点放在结果的准确率上。LightGBM还支持GPU学习,因此,数据科学家广泛的使用LightGBM来进行数据科学应用的部署。
我们可以不管什么地方都用LightGBM吗?
不可以!不建议在小数据集上使用LightGBM。LightGBM对过拟合很敏感,对于小数据集非常容易过拟合。对于多小属于小数据集,并没有什么阈值,但是从我的经验,我建议对于10000+以上的数据的时候,再使用LightGBM。
我们简单的讨论了一下LightGBM的概念,现在,如何实现?
实现LightGBM非常简单,复杂的是参数的调试。LightGBM有超过100个参数,但是不用担心,你不需要所有的都学。
对于实现的人来说,知道一些基本的参数是非常重要的。如果仔细的过一遍LightGBM的参数,你会发现这个强大的算法就是小菜一碟。
我们开始讨论参数。
参数
控制参数
maxdepth: 描述了树的最大深度。这个参数用来处理过拟合问题。一旦你发现你的模型过拟合了,首先就是减小maxdepth。
mindatain_leaf: 一个树叶上可以有的数据的最小数量。默认是20,最优值。也是用来处理过拟合。
feature_fraction: 在你的提升方法是随机森林的时候用。0.8 feature fraction表示每个迭代,LightGBM会随机选择80%的参数来构建树。
bagging_fraction: 指定每个迭代用的数据的比例,通常用来加速训练,防止过拟合。
earlystoppinground: 这个参数帮助你加速分析。如果一个验证集上的一个评估方法在earlystoppinground数量的几轮中没有提升,就会减掉过多的迭代。
lambda: 正则化的参数,从0~1。
mingainto_split: 这个参数表示进行树的分裂时,最小的增长,可以用来控制树中有用的分裂的数量。
maxcatgroup: 当类别的数量很大,找到分裂点非常容易过拟合。所以,LightGBM将它们合并成 ‘maxcatgroup’ 组,找到组的分裂点进行分裂,默认:64。
核心参数
Task: 指定了需要在数据上做的任务,训练或者是预测。
application: 这是最重要的参数,指定了你的模型的应用,回归或者是分类。LightGBM默认是回归模型。
regression: 回归
binary: 二元分类
multiclass: 多类分类
boosting: 定义了你想要运行的算法的类型,默认是gdbt
gbdt: 传统的梯度提升树
rf: 随机森林
dart: 使用dropout的多重回归树相加
goss: 基于梯度的单边采样
numboostround: 提升的迭代数量,一般100+
learning_rate: 这个影响每棵树的最终的结果。GBM 的利用每一棵树的输出得到初始预测,然后开始迭代,学习率控制了预测的变化的大小程度,典型值:0.1, 0.001, 0.003…
num_leaves: 完整数的叶子的数量,默认:31
device: 默认:cpu,也可以传入gpu
度量参数
metric: 也是一个非常重要的参数,指定了模型的损失函数。下面是几种常用的回归和分类的损失函数。
mae: 绝对值平均误差
mse: 均方误差
binary_logloss: 二元分类对数损失
multi_logloss:多分类对数损失
输入输出参数
max_bin: 表示特征被分箱的最大数量。
categoricalfeature: 表示类别特征的索引。如果categoricalfeatures=0,1,2 ,那么第0列,第1列,第2列都是类别变量。
ignorecolumn: 和categoricalfeatures一样,不过不是认为是类别变量,而是完全忽略。
save_binary: 如果你的数据量对于你的内存来说太大了,将这个参数设为‘True’。这样可以将你的数据集存为二进制文件,这个二进制文件下次读的时候,会节省很多时间。
了解和使用上面的参数一定会有助于与你实现这个模型。记住我说的,实现LightGBM很容易,调试很难。所以,第一步先实现它,然后我会教你如何调试参数。
实现
安装LGBM:
安装LightGBM很重要。我发现这里是教你如何安装的最好的资源。
我使用Anaconda安装LightGBM,只要运行下面的命令就可以了。
conda install -c conda-forge lightgbm
数据集:
这个数据集很小,只有400行,5列(专门是学习用的)。这是个分类问题,我们预测用户是否会购买网站上给的广告中的商品。我就不解释这个数据集了,非常简单。你可以从这里下载数据集。
注意:这个数据集是清洗过的,没有确实数据。选这个小数据集的主要的目的是让事情简单明了。
我假设你有基础的python知识。过一遍数据预处理阶段,非常的简单。
数据预处理:
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd# Importing the datasetdataset = pd.read_csv('...input\\Social_Network_Ads.csv')X = dataset.iloc[:, [2, 3]].valuesy = dataset.iloc[:, 4].values# Splitting the dataset into the Training set and Test setfrom sklearn.cross_validation import train_test_splitx_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()x_train = sc.fit_transform(x_train)x_test = sc.transform(x_test)模型构建和训练:
我们需要将我们的训练数据转换成LightGBM的数据集格式,这是强制的要求。
数据集转换完成之后,我用参数和对应的值创建一个python字典。你的模型的准确率依赖于你提供的这些参数。
在代码最后,我简单的训练100个迭代。
import lightgbm as lgbd_train = lgb.Dataset(x_train, label=y_train)params = {}params['learning_rate'] = 0.003params['boosting_type'] = 'gbdt'params['objective'] = 'binary'params['metric'] = 'binary_logloss'params['sub_feature'] = 0.5params['num_leaves'] = 10params['min_data'] = 50params['max_depth'] = 10clf = lgb.train(params, d_train, 100)几个参数中需要注意的事情:
使用‘binary’ 作为目标(这是个二分类问题)
使用 ‘binary_logloss’ 作为度量(这是个二分类问题)
‘num_leaves’=10 (这是个小数据集)
‘boosting type’ 是gbdt, 我们实现的是梯度提升算法(你也可以试试随机森林)
模型预测:
我们一行代码就可以进行预测。
输出的是一个概率的列表。我使用threshold=0.5将概率转换为二分类预测。
#Predictiony_pred=clf.predict(x_test)#convert into binary valuesfor i in range(0,99): if y_pred[i]>=.5: # setting threshold to .5 y_pred[i]=1 else: y_pred[i]=0
结果:
我可以使用混淆矩阵或者直接计算准确率来查看结果。
代码:
#Confusion matrixfrom sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)#Accuracyfrom sklearn.metrics import accuracy_scoreaccuracy=accuracy_score(y_pred,y_test)
结果截图:
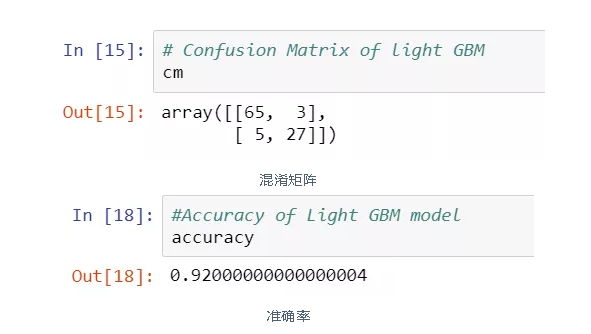
你们许多人可能会想,我用这么小的数据集,准确率还有92%,为什么没有过拟合?原因很简单,我调试了模型参数。
现在,我们开始进入调参。
调参:
数据科学家在使用参数的时候,总是很挣扎。理想的参数应该长什么样呢?
下面的一组练习可以用来提升你的模型效率。
num_leaves: 这个是控制树的复杂度的主要的参数。理想情况下,叶子的数量的值应该小于等于 $2^{max_depth}$,大于这个值会导致过拟合。
mindatain_leaf: 设置成一个比较大的值可以避免树生长太深,但是可能会导致过拟合。实际使用中,对于大数据集设置成几百到几千就足够了。
maxdepth: 你可以使用maxdepth来显式的限制深度。
追求速度:
通过设置
bagging_fraction和bagging_freq来使用bagging通过设置
feature_fraction来使用特征下采样使用小的
max_bin使用
save_binary来加速加载数据使用并行学习,参考parallel learning guide
追求更高的准确率:
使用大的
max_bin(可能速度会慢)使用小
learning_rate大的num_iterations使用大的
num_leaves(可能会过拟合)使用大训练数据集
试试
dart尝试直接使用类别特征
处理过拟合:
使用小的
max_bin使用小的
num_leaves使用
min_data_in_leaf和min_sum_hessian_in_leaf通过设置
bagging_fraction和bagging_freq来使用bagging通过设置
feature_fraction来使用特征下采样`使用大训练数据集
尝试使用
lambda_l1,lambda_l2和min_gain_to_split来进行正则化尝试使用
max_depth来避免生成的树太深
结论:
我在好几个数据集上都用过LightGBM,发现它的准确率相比其他的提升算法还是比较好的。从我的经验来看,我建议你至少试一次这个算法。


评论专区