
经验之谈|别再在CNN中使用Dropout了
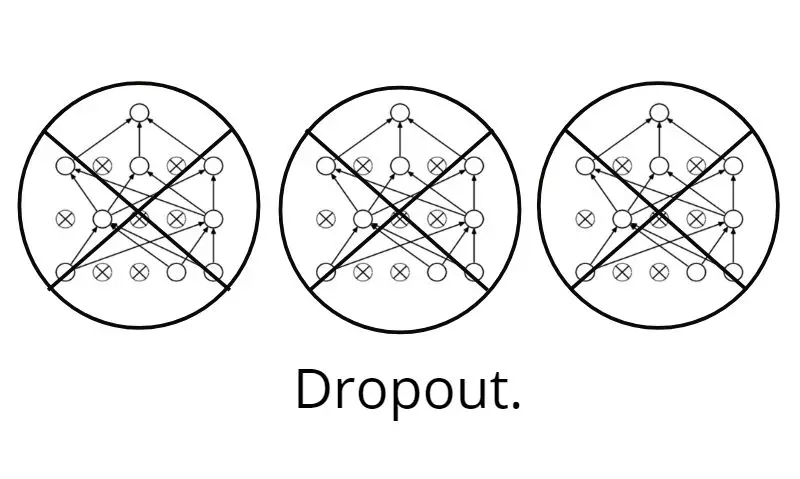
如果你在读这篇文章的话,我假设你有一些对dropout的基本理解,以及它在神经网络中扮演的正则化的角色。
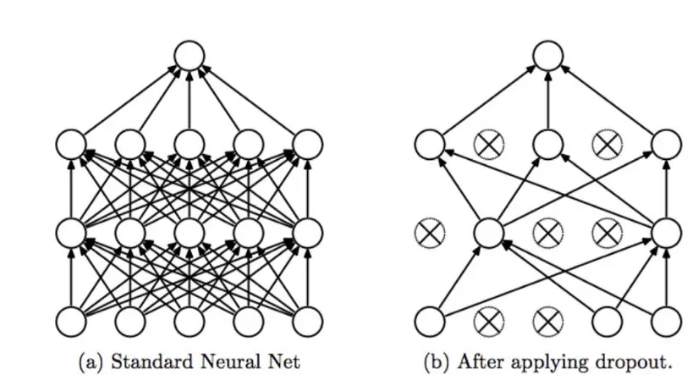
通常来说,只有当我们的网络有过拟合的风险的时候,才需要进行正则化。当网络非常大,训练时间非常长,也没有足够的数据的时候,才可能发生。
如果你的网络的最后有全连接层的话,使用dropout非常的容易。
python
model=keras.models.Sequential() model.add(keras.layers.Dense(150, activation="relu")) model.add(keras.layers.Dropout(0.5))
注意,这里只在CNN中的全连接层使用。对于其他的层则不用dropout。 作为替代,你应该在卷积中插入batch normalization,这个也会正则化你的模型,同时让训练更加的稳定。

Batch Normalization.
Batch normalization是另外一个队CNN进行正则化的方法。 除了正则化的作用外,batch normalization还避免了CNN训练中的梯度消失的问题。这个可以减小训练的时间,得到更好的结果。
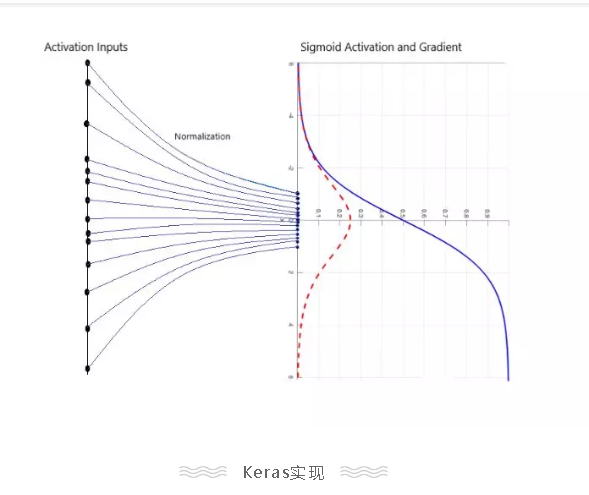
在Keras中实现 batch normalization,使用下面的方法:
例子:
model.add(Conv2D(60,3, padding = "same")) model.add(BatchNormalization()) model.add(Activation("relu")) 使用Batch normalization替换dropout. 如果你不用担心过拟合的话,那么使用batch normalization有很多的好处。由于有正则化的作用,batch normalization可以很大程度上替代CNN中的dropout。
“我们提出了一种算法,使用batch normalization用来构建,训练和进行推理。得到的网络训练时具有饱和的非线性性,对于大的学习率更加的鲁棒,往往不需要使用Dropout来进行正则化。”-Ioffe 和 Svegedy 至于为什么dropout渐渐失宠,有两个原因。 第一,dropout对卷积层的正则化的作用很小 原因呢?由于卷积层只有很少的参数,他们本身就不需要多少正则化。更进一步说,特征图编码的是空间的关系,特征图的激活是高度相关的,这也导致了dropout的失效。 第二,dropout所擅长的正则化慢慢的过时了 像VGG16这样的大型的网络后面有全连接层,对于这样的模型,需要考虑过拟合,所以在全连接之间使用dropout。
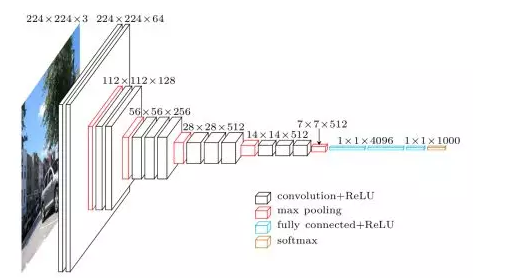
但是不幸的时,现在的结构中全连接层被移除了。
我们使用了global average pooling来代替了全连接层,这种卷积网络可以减小模型的size,同时提高模型的表现。
实验
我做了一个实验,试试看是否 batch normalization可以减少泛化误差。 我构建了5个完全相同的卷积网络结构,然后分别在卷积之间插入dropout,batch norm,或者什么也不插入(control)。

在Cifar100的数据集上训练每个模型,我得到了下面的结果。
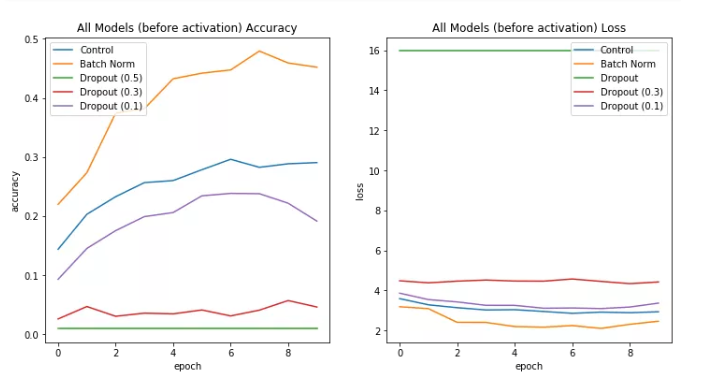
使用batch norm的表现最好,说明在卷积之间应该使用batch norm。
更进一步说,dropout不应该放在卷积之间,dropout越大,模型表现越差。
重点


评论专区