
数据结构-线性表练习题 - 数据结构 - 机器学习
数据结构 - 机器学习
深度学习

当前位置:首页 » 数据结构练习题 » 正文
数据结构-线性表练习题
1778 人参与 2018年09月10日 21:37 分类 : 数据结构练习题 评论
1. 下述算法的功能是什么?
LinkNodeDemo(LinkListL)//L是无头结点的单链表
{ListNode*P,*Q;
If (L&&L->next)
{Q=L;L=L->next;P=L;
while ( P->next)P=P->next;
P->next=Q;Q->next=NULL;
}
returnL:
}
解:该算法的功能:将开始结点摘下链接到终端结点之后成为新的终端结点,而原来的第二个结点成为新的开始结点,返回新链表的头指针。
2. 有一个单链表(不同结点的数据域植可能相同),其头指针为head,编写一个函数计算数据域为x的结点个数。
解:本题是遍历通过该链表的每个结点,每遇到一个结点,结点个数加1,结点个数存储在变量n中。实现本题功能的函数如下:
int count(head,x)
node *head;
ElemType x;
{
node *p;
int n=0;
p=head;
while (p!=NULL)
{
if(p->data==x)n++;
p=p->next;
}
return(n);
}
3. 已知一个单链表如下图所示,编写一个函数将该单链表复制一个拷贝。

解:本题的算法思想是依次查找该单链表(其头指针head1)中的每个结点,对每个结点复制一个新结点并链接到新的单链表(其头指针为head2)中。实现本题功能的函数如下:
void copy(head1,head2)
{
node *head1,*head2;
node *p,*q,*s;
head2=(node *)malloc(sizeof(node));/*建立一个头结点*/
q=head2;p=head1;
while(p!= NULL)
{
s=(node *)malloc(sizeof(node));/*复制一个新结点*/
s->data=p->data;
q->next=s;/*把s链接到q之后*/
q=s;
p=p->next;
}
q->next=NULL;/*将最后一个结点的next域置为NULL*/
p=head2;/*删除头结点*/
head2=head2->next;
free(p);
}
4. 试比较顺序存储结构和链式存储结构的优缺点。在什么情况下用顺序表比链表好?
① 顺序存储时,相邻数据元素的存放地址也相邻(逻辑与物理统一);要求内存中可用存储单元的地址必须是连续的。
优点:存储密度大(=1),存储空间利用率高。缺点:插入或删除元素时不方便。
②链式存储时,相邻数据元素可随意存放,但所占存储空间分两部分,一部分存放结点值,另一部分存放表示结点间关系的指针
优点:插入或删除元素时很方便,使用灵活。缺点:存储密度小(<1),存储空间利用率低。
顺序表适宜于做查找这样的静态操作;链表宜于做插入、删除这样的动态操作。
若线性表的长度变化不大,且其主要操作是查找,则采用顺序表;
若线性表的长度变化较大,且其主要操作是插入、删除操作,则采用链表。
5. 描述以下三个概念的区别:头指针、头结点、首元结点(第一个元素结点)。在单链表中设置头结点的作用是什么?
首元结点是指链表中存储线性表中第一个数据元素a1的结点。
为了操作方便,通常在链表的首元结点之前附设一个结点,称为头结点,该结点的数据域中不存储线性表的数据元素,其作用是为了对链表进行操作时,可以对空表、非空表的情况以及对首元结点进行统一处理。
头指针是指向链表中第一个结点(或为头结点或为首元结点)的指针。
若链表中附设头结点,则不管线性表是否为空表,头指针均不为空。否则表示空表的链表的头指针为空。
这三个概念对单链表、双向链表和循环链表均适用。
是否设置头结点,是不同的存储结构表示同一逻辑结构的问题。
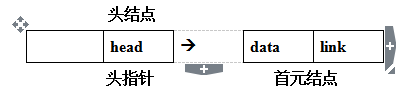
简而言之,
头指针是指向链表中第一个结点(或为头结点或为首元结点)的指针;
头结点是在链表的首元结点之前附设的一个结点;数据域内只放空表标志和表长等信息(内放头指针?那还得另配一个头指针!!!)
首元素结点是指链表中存储线性表中第一个数据元素a1的结点。
6. 为什么在单循环链表中设置尾指针比设置头指针更好?
尾指针是指向终端结点的指针,用它来表示单循环链表可以使得查找链表的开始结点和终端结点都很方便,
设一带头结点的单循环链表,其尾指针为rear,则开始结点和终端结点的位置分别是rear->next->next 和 rear, 查找时间都是O(1)。
若用头指针来表示该链表,则查找终端结点的时间为O(n)。
7. 在单链表、双链表和单循环链表中,若仅知道指针p指向某结点,不知道头指针,能否将结点*p从相应的链表中删去?若可以,其时间复杂度各为多少?
下面分别讨论三种链表的情况。
单链表。若指针p指向某结点时,能够根据该指针找到其直接后继,能够顺后继指针链找到*p结点后的结点。但是由于不知道其头指针,所以无法访问到p指针指向的结点的直接前趋。因此无法删去该结点。
双链表。由于这样的链表提供双向指针,根据*p结点的前趋指针和后继指针可以查找到其直接前趋和直接后继,从而可以删除该结点。其时间复杂度为O(1)。
单循环链表。根据已知结点位置,可以直接得到其后相邻的结点位置(直接后继),又因为是循环链表,所以我们可以通过查找,得到p结点的直接前趋。因此可以删去p所指结点。其时间复杂度应为O(n)。
8. 线性表的每个结点只能是一个简单类型,而链表的每个结点可以是一个复杂类型。
错,混淆了逻辑结构与物理结构,链表也是线性表!且即使是顺序表,也能存放记录型数据。
9. 顺序表结构适宜于进行顺序存取,而链表适宜于进行随机存取。
错,正好说反了。顺序表才适合随机存取,链表恰恰适于“顺藤摸瓜”。
来源:我是码农,转载请保留出处和链接!
本文链接:http://www.54manong.com/?id=351
微信号:qq444848023 QQ号:444848023
加入【我是码农】QQ群:864689844(加群验证:我是码农)
- 数据结构-栈和队列练习题2018-09-10 21:42
- 题目:广义表的存储结构2018-09-10 21:46
- 数据结构-绪论-练习题2018-09-10 21:51
- 题目:二叉树应用2018-09-10 21:48
网站分类
- 数据结构
- 数据结构视频教程
- 数据结构练习题
- 数据结构试卷
- 数据结构习题解析
- 数据结构电子书
- 数据结构精品文章
- 区块链
- 区块链精品文章
- 区块链电子书
- 大数据
- 大数据精品文章
- 大数据电子书
- 机器学习
- 机器学习精品文章
- 机器学习电子书
- 面试笔试
- 物联网/云计算
标签列表
- 数据结构 (39)
- 数据结构电子书 (20)
- 数据结构习题解析 (8)
- 数据结构试卷 (10)
- 区块链是什么 (261)
- 数据结构视频教程 (31)
- 大数据技术与应用 (12)
- 百面机器学习 (14)
- 机器学电子书 (29)
- 大数据电子书 (37)
- 程序员面试 (10)
- RFID (21)
最近发表
- 找出数组中有3个出现一次的数字
- 《百面机器学习》电子书下载
- 区块链精品电子书《深度探索区块链:Hyperledger技术与应用_区块链技术丛书》张增骏
- 区块链精品电子书《比特币:一个虚幻而真实的金融世界》
- 区块链精品电子书《图说区块链》-徐明星 & 田颖 & 李霁月
- 区块链精品电子书《是非区块链:技术、投机与泡沫》-英国《金融时报》
- 区块链精品电子书《商业区块链:开启加密经济新时代》-威廉·穆贾雅
- 区块链精品电子书《人工智能时代,一本书读懂区块链金融 (互联网_时代企业管理实战系列)》-马兆林
-
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https'){
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else{
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
全站首页 | 数据结构 | 区块链| 大数据 | 机器学习 | 物联网和云计算 | 面试笔试
var cnzz_protocol = (("https:" == document.location.protocol) ? "https://" : "http://");document.write(unescape("%3Cspan id='cnzz_stat_icon_1276413723'%3E%3C/span%3E%3Cscript src='" + cnzz_protocol + "s23.cnzz.com/z_stat.php%3Fid%3D1276413723%26show%3Dpic1' type='text/javascript'%3E%3C/script%3E"));本站资源大部分来自互联网,版权归原作者所有!






评论专区