
通过机器学习为机器学习项目创造新思路
使用预先训练的语言模型从2.5k句子的小型语料库生成特定于样式的文本。PyTorch中的代码
我们来做一个快速的图灵测试。下面,您将看到十个机器学习项目的想法。其中五个由人类生成,其中五个由神经网络生成。你的任务是分开他们。
准备?(不要过度思考。只要随心所欲)。
股票交易学习者
预测数据中频率的差异
机器学习专利分类
分类遥感图像的卷积特征
随机森林的人脸检测
机器学习预测职业成功
旋转不变稀疏编码
深度学习在公平中的应用
从3D点云识别物体
建筑学模型在加利福尼亚
看清单?记下你认为神经网络产生的五个想法,以及人类产生的五个想法。
* Cue drumroll *获取答案。

答:所有奇数编号的想法都是斯坦福大学CS229机器学习课程完成的最终项目的标题,所有偶数编号的想法都是由在该数据集上训练的神经网络生成的。
是的,向上滚动并再次查看列表,比较您的笔记,然后我们将深入了解如何生成这些想法的详细信息。你有多准确?(在评论中说出来!)
这个项目的动机是让我学习使用递归神经网络(RNN)来生成类似于我最喜欢的哲学家和思想家的报价。我见过许多其他人使用RNN 生成音乐,笑话甚至分子。为了哲学,我被抽出去做同样的事情。
从网上,我收集了大约5000个来自加缪,尼采,维特根斯坦,费曼,大卫休谟,斯蒂芬霍金和詹姆斯库斯等思想家的报价。
我完全忽略的是,我作为灵感的项目通常有一个数百万的数据集,而我自己拥有的数据是5000个句子。天真地,盲目地,我继续前进,并一再失败,让我的人工哲学家工作。最后,经过三次失败的实验后,我开始工作,随后我建立了一台机器学习创意发生器。
当训练语料库很小时,RNN的不合理固执性
这是我用RNN做的第一个失败的实验:
我认为语料库不够大,无法训练单词级语言模型,所以我选择了一个字符级语言模型
我在语料库上训练了一个非常简单的基于LSTM / GRU的单层复发网络,但效果并不好
它输出英语好看但最终乱码句子,如“ 我可以对我们和能对来此撕毁的contrange的somethe撕毁的conservati ”
我的第二次失败实验:
我想也许一层经常性单位是不够的,所以我试验了两层,并且还以更高的学习率进行了游戏。
没有任何效果。我仍然得到一些胡言乱语,例如:“ 我真实地发现,在你们面前,你们是为那些男人而做的更多的事情。 ”
我的第三次失败实验:
由于一个小的语料库,我认为也许一个生成的对抗框架会更好地工作
但这也没有用,我意识到LSTM的GAN很难,而且有关于它的论文,但培训很难,输出质量也不好。
经过多次训练,我的GAN更糟糕。它生成了绝对垃圾的文本:“ x11114111411141114111 ”
经过这么多失败的尝试,我非常沮丧,我的人工哲学家将永远是一个白日梦。

我从这些失败的尝试得出的结论是,罪魁祸首是小文本语料库。
也许5000个引号不足以产生类似的高质量报价?
因此,作为我的下一个实验,我想尝试预先存在的word嵌入,例如word2vec,而不是强迫网络从头开始学习嵌入。但是,在此之前,我决定就Reddit的机器学习subreddit提出建议。在我开始的帖子中,有人向我指出了2018年NeurIPS会议上接受的一张海报,题为“ 转移学习风格专用文本生成”。我从那篇论文中听到了他们的想法,他们就像一个魅力。
什么是转学?
转学是一个简单而有力的想法。这意味着使用在非常大的数据集上训练的现有模型作为起点,并调整它以适应特定于域的数据集。
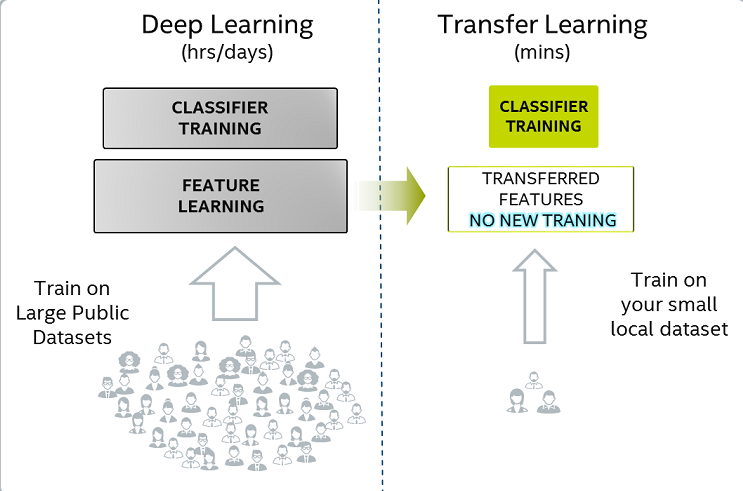
在计算机视觉社区,转学习已经使用了很长时间。我们的想法是使用VGG等公共可用模型,该模型在ImageNet数据集上进行了训练,在20,000个类别中拥有1400万个图像,并使用其最后一层的激活作为附加任务特定图层的输入。然后,附加层将专门针对您的小型特定于域的数据集进行培训,以进行预测,分类或任何其他任务。
使用预先训练的模型令人惊讶的美妙之处在于,您可以免费使用预训练模型在数百小时的培训中学习数百万张图像的所有概念。
预先训练的模型是压缩知识。
这些预先学习的概念和激活使您能够对您的小型特定于域的数据集进行预测和分类。由于所有“自然”数据集共享相似的特征,因此产生了这种魔力。大多数图像共享许多特征:从形状,线条和边缘的原始概念到高级概念,如纹理和光影效果。
如果没有经过预先训练的模型,您必须从头开始学习所有这些概念,而您的数据集可能没有足够的示例来执行此操作。通过预先训练的模型,您可以直接了解您的领域/问题中的重要和不同之处,而不必担心数据集中发现的常见问题。
使用预先训练的语言模型在文本和NLP中转移学习
最近,转学习已经开始在NLP中出现,并且开辟了激动人心的可能性。这是Google庞大的BERT模型,然后是ULMFit。
这些语言模型在公共可用的文本语料库(例如议会记录,维基百科等)上进行训练,并隐含地编码英语知识。因此,即使您的数据集非常小,它们也可以启用机器学习任务,例如对文本进行分类和预测。
这正是我想要的!我的引号数据集很小(~5k),我的目标是生成一个类似于我最喜欢的思想家的风格的新引号。
从小型数据集生成文本的代码
为了从我的小语料库中生成特定于样式的文本,我按照Reddit线程链接的文件,这使我得到FastAI的课程,使用预先训练的模型对IMDB评论进行分类。课程是关于分类的,但是当我浏览FastAI库的文档时,我发现由于库中的辅助函数,即使生成文本也很简单。
我的代码和数据集存在于此存储库中。你需要PyTorch v1,FastAI v1和Pandas。请注意,我的代码实际上是来自F astAI文本模块文档的复制粘贴。他们使用易于使用的预训练模型。
我们使用什么预先训练的模型?这是由Salesforce的研究团队开发的3层AWD-LSTM模型,该团队使用维基百科的文章训练了1亿个令牌。我鼓励您阅读有关此特定型号的更多详细信息,但使用预先训练的模型的一个主要好处是您可以通过不了解底层细节来逃避。就像你很可能不关心Pytorch和Numpy如何在引擎盖下工作一样,你也可以不关心AWD-LSTM如何工作。
由预先训练的模型提供的这种抽象水平确实是革命性的。
现在,任何人都可以在各自的领域中组装最先进的深度学习模型,而无需数月和数年的努力。(但是当你没有得到结果时知道细节是值得的)
Aritifical Philosopher:由我的神经网络产生的新的哲学见解

当我运行我的模型时,我完全不相信它的结果。兴奋之情,我发了推文:
我的网络说:“ 在世界上没有一个人不是奴隶 ”,这听起来太好了,我首先检查了它是否只是简单地重复数据集中的记忆引用。当我没有找到它时,我搜索了确切的短语,看看之前是否已表达过这个想法。瞧不起,我也没在Google上找到它。
这是由神经网络生成的100个引号的运行。我不会以任何方式修改这些内容。我从笔记本上直接复制粘贴了这些内容。(我正在加粗那些有趣且可能是独一无二的)。
'por las vida de los mundo de los mundo en el chi',
' 事实是,我们无法确定我们不知道的东西。',
'根据标准,人是真正的动物。',
“它是我的事,我认为这就是我不知道的事情。“,
经过一次冒险之后,直到那时才开始制定旧观念。',
'必须避免有限玩家的生命',
' 人类也是一种动物。',
'我不得不转向',
“我希望人们快乐,但我不想成为自己。”,
“哲学家有更大的自由并为哲学家。',
'暂时不仅仅是一种思想,而是一种悲剧。',
“在这个阶段,它是真正的艺术。”,
“我是桥梁,桥梁和桥梁桥梁。”,
“这是世界尚未见到的智慧。”,
“ 未来是伟大的,因为我们喜欢一切。”,
“对人的权利的信念是什么?”,
“自然是一个完美的视野。”,
“t”,
“ 学会画画是强加法律关于物理定律。',
' 荒谬的感觉:就像我们看到为什么我们在这里一样。',
' 与怪物打架的人都知道他是什么。',
'不再文化是自我掌控的标志。',
“当宇宙在旋转时,我将做出一个非常重大的决定。”,
“今天这可能是最神秘的科学之谜。”,
“这不是事实,是一种让爱情感到羞耻的理由。',
'我周围的世界,我相信,这是世界本身。',
'主题必须始终是一个并不孤单的人。',
'有些人不想愚蠢。“,
' 好梦是你必须为好的和坏的而奋斗。',
'没有强大的社区,没有人可以生活'',
'我不是那个我自己的男人。'
'' 我觉得当我被触摸时我必须完全不复存在。
“无限玩家的上述原则是非常好的。”,
“ 星星小而孤独,虽然它们既不大也不坏。”,
“所有的灵魂都是无知的。”,
“ 我语言的极限总是你的极限。 ',
' 世界是一个没有任何真正目的的世界。',
'超越时代的曲线成为他的最爱。',
'我继续相信这种生活状态',
'这是所有事物的起源。' ,
' 我们必须生活,让生活才能创造一个宇宙。',
' 一个人是最肥沃的人。',
'这个世界无处不在',
'生活就是快乐。',
' 现在的男人有理由能够生出一个舞蹈明星。',
“令人惊讶地说,现实世界有一个开端:”,
“第一件事就是在心脏不行了。”,
“我如何学会走路和跳舞,我一定要唱。”,
“ 只要心灵是由它的法律限制,不能被理解。”,
“ 在猿猴的弱点不是无限的,但令我们惊讶的是,
“在谈话结束时,有一个无敌的夏天。”,
'les de la vida pour la vie a es se non het la vida。',
'我说最后,最后一件事就是死。',
“人类理解的是,真正的男人是一个不公正的孩子。',
'灵魂是一个死的原因。',
“似乎只有一个孩子的爱。”,
“这就是为什么世界是受物理定律支配。',
'国王是一个天才,上学是一个公共关系是的。',
' 孩子是出生于这个孤独。',
' 我是树林中的树。',
'我们从未得到过最少的想法和想法。',
'中世纪的每个时代都源于和平的圣灵。',
'但没有人愿意为和平,正义或理性而奋斗。',
“但是N”如果什么呼吸是坏的,时间将会发生。“,
“所有美丽的核心都是滔天,充满了东西。”,
“真的,我的心永远不会。”,
“是的,这就是说人类事务的发展非常迅速。”,
“一切都在世界就像一个死世界。',
'好人是一个想要发挥自己的人。',
'没有真正的真理,但这是永恒的真理。',
'你想象他生活中
的问题不是普遍存在,而是人类的未来。',
'没有人可以在生命之河上建立一座桥梁。',
' 激情是渴望成为一个人的未来。强大。然而,有必要爱弱者。',
最终,一个人必须有嫉妒的经验。',
'从我未来的黑暗视野中,永远不会看到未来。',
'不知道的人有意义,他有理由去做。',
' 不一个人知道青少年......一定是学会了如何走路。',
'英格索是一个非常糟糕的土壤。',
'这是我们所看到的地方,也是我们所看到的地方。 ,
'一种',
'在物理极限之间没有界限。',
'男人是有被克服的优势',
'女人是女人。她是一个tahu。',
' 活着就是独自生活 ',
一个人的命运必须和人的等级一样伟大。',
'二十世纪的所有艺术家都可以自由地独自生活!',
'国家没有理由让世界感到惊讶。',
“有证据表明,在每个人中,一个人必须赢得这场比赛。”,
“ 世界是值得生活的。”,
“这个愚蠢的人不是一个坏的良心而是一个坏的骗子”,
因为我们必须在我们有一个朋友和爱之间
做出选择。','儿童尊严的母亲是母亲或母亲。',
' 这是我们不理解的有价值艺术。',
'一位作家写了一篇关于他宇宙中究竟是什么的明确想法,
“他们相信罕见的东西是罕见的。”,
“世界前进的每一步都排除了未来,并且有一定的未来。”,
“并继续这是原始保护的恐怖。”,
“ 孤独往往是一种活动。',
' 一个人担心我永远不会忘记事情。',
' 我爱的人没有幸福,但不会感到他们变得坚强。
您必须在其他文章中看到同样令人印象深刻的生成文本 但是我认为这里令人印象深刻的是生成文本的质量,因为我的训练集非常小(5k句子)。这只能使用预先训练的模型。
这看起来似乎并不多,但我认为像“ 我的语言的极限总是你的极限 ”这样的想法似乎是语言哲学家Ludwig Wittgenstein所说的。事实上,当你使用谷歌这句话时,你发现没有确切的结果,但谷歌建议查看关于维特根斯坦的维基百科文章。
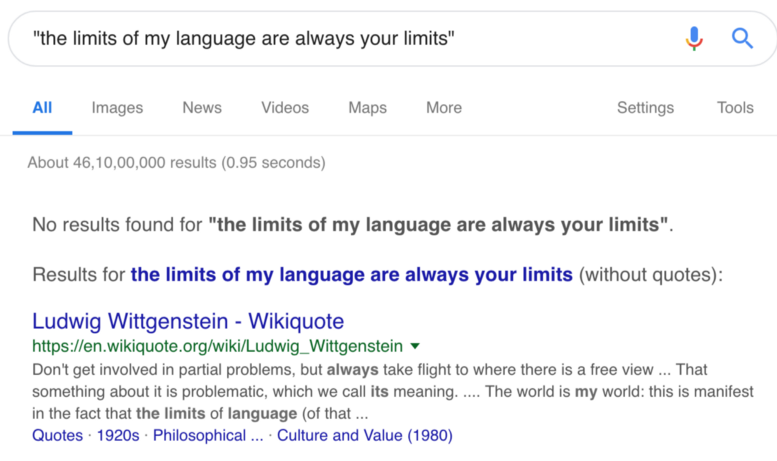
实际上,维特根斯坦说过:“我语言的极限意味着我的世界的极限”,而我们的模型巧妙地(并且以语法准确的方式)将其改变为新的东西。
同样地,所产生的引语“ 现在的人有理由能够生出一个舞蹈明星 ”让人想起尼采,因为他在书中提到了“ 舞蹈明星 ”,但他从未在现在的人的背景下说过。我可能正在阅读太多内容,但对我来说,生成的引用代表了我们已经变得如此技术先进以至于我们可以产生非常复杂的机器(如舞蹈明星)并且我们变得如此具有竞争力的想法。我们有理由这样做。(我的神经网络是否警告我们人工智能的潜在危险及其不可避免性?)
让我们产生一个舞蹈明星:产生新的机器学习理念
请记住,我的哲学语录是大约5000个句子。我想知道如果我给它一个更小的语料库,这种方法将如何表现。
我决定生成机器学习的想法会很有趣。据我所知,迄今为止没有其他人尝试过这样做。因此,我收集了斯坦福大学CS229班级学生从2004年到2017年提交的所有机器学习项目的标题。该数据集包括2500个想法,每个包含5到7个单词。我的存储库中提供了数据集和相应的笔记本。(注意:我不拥有创意的版权。它仅用于研究和探索)
该项目似乎令人兴奋,但我主要担心的是,机器学习项目思想的领域非常狭窄,包含利基和技术术语。我认为该模型将主要吐出记忆的想法,与数据集中的想法相同。
然而,令我惊讶的是,它产生了一些非常新颖的想法(粗体,然后是我的评论):
“ 通过数码相机行为的不同类型的社交视频游戏 ”。数据集中没有“社交视频游戏”短语,因此必须是新的。
“ 学习识别学术主题事件的机器学习方法 ”。数据集中没有“学术主题”短语。
“ 预测数据中频率的差异 ”< - 数据集中没有“数据中的频率”短语。
“ 利用学习来预测识别基因表达的特征 ”< - 实际上是一个新颖的想法!
“ 在光学图像中对人类基因表达进行分类 ”< - 没有关于人类基因表达分类的项目想法。
“ 塑造世界形象 ”。我认为这是一个有趣的项目建议,你必须想出一个代表整个世界的图像/图形。
“ 预测人类行为的维度 ”。可能是对人类行为的所有不同方式进行无监督分类的建议?
“ 加强学习,以改善专业学习”。训练数据集没有“专业学习”这个短语。如何通过强化学习的思路提高专业课程的学习能力?我对此印象非常深刻,因为它看起来既有价值又可行。
“ 单一表达企业市场上的内容?”。您如何结合股票市场的所有指标来提出一个信息量最大的指标?
“ 心脏过程的类型 ”。无监督学习聚类相似的心脏过程模式,以帮助预测和分析可能导致心脏骤停的模式。
“ 在人类互动的自然历史中 ”。使用人类迁移数据集,您如何对历史人类交互进行分类。您是否可以对历史学家和人类学家错过的人类互动产生新的见解?
“ 对遥感图像的卷积特征进行分类 ”。数据集没有短语“卷积特征”。对于那些对CNN背后的理论感兴趣的人来说,这个项目听起来像是一个有趣的研究项目。
“ 分类和预测事件评论 ”< - 哇,数据集没有短语“事件评论”。就像IMDB评论一样,我们是否可以收集(戏剧或摇滚音乐会)的事件评论,并预测未来哪些事件会成功哪些事件将会失败?
如果您想要从模型中获得未过滤的输出,那么这里有100个想法。我没有修改过任何东西(仅仅是我认为有趣且新颖的那些)。
“问题是正确的:掌握和提取姿势的面孔”,
“将机器学习应用于文本处理”,
“通过机器学习学习机器学习技术”,
“ 从单个对象预测职业成功的机器学习方法 ”,
“ 使用机器学习来预测机器学习方法的结果 ”,
“基于股票价格”,
“ 识别机器学习技术的股票价格模型 ”,
“对音乐特征的时间旅行时间序列分析研究”,
“向量中的'亚马逊影响网络',
'在facebook '中分类网页文章,
“后中学订单数据中的动态信号处理”,
“机器学习技术的复制选择”,
“用户分类的解释”,
“ 使用语义框架进行公平的深度学习 ”,
“创建不同的实体”投资组合“,
'使用监督学习盲数据',
'用于驱动自动车辆设计的系统分类和基因表达分类',
'基于文本表达的公共文档',
' 用于音乐的语义学习 ',
' 用于癌症预测的机器学习 ',
'学习静态变化,深入学习学习选项',
'svm的图像分类',
' 卫星图像分类 ',
'从单个对象做出决策选择',
'使用产品偏好进行对象检测',
' 深度学习的语音检测 ',
' 基于股票交易的基因组数据 ',
' 学习预测手写方式 ',
' 从作曲家数据分类音乐特征 ',
'语义社交网络和智能手机功能',
'机器学习技术',
' 使用实时信息预测市场的普及 ',
' 视频游戏分类',
'时间序列玩家的学习任务',
'使用单一机器学习方法学习识别其他环境的单一学习方法',
'欺诈的多种类型分类\ n对大众神经网络的预测',
' 从文本分析中学习人类活动识别,
“通过视频游戏心电图学习nba播放器的学习和角色预测方法”,
“在当地mri学习中播放声乐乐器”,
“实时音乐录音”,
“ 发现音乐录影带中的新艺术和艺术特征 ',
' 对音乐类型的分析 ',
'预测单一图像特定的音乐风格',
“犯罪预测的成本方法”,
“自动用户预测和自动审核识别”,
“ 通过机器学习进行食品加工 ”,
“使用多标签幻想进行人类活动识别”,
“预测击键扑克中的匹配”,
“估计“游戏类型”,
“使用神经网络进行运动监测的深度学习识别”,
“实时播放的协同注意力投射的价值”,
“海平面和低速:两波”,
“学习预测”啤酒和个人基因组的价格,
“ 从文本中交换和删除新图像 ”,
'谷歌手势上的实时新闻用户识别',
“去除和重新学习玩游戏和歌词”,
“快速 - 声学图像动态”,
“实时音乐指导”,
“你的权利是什么?”,
“探索事件和音乐”,
“人类活动”使用机器学习预测',
' 加利福尼亚建筑模型 ',
'轻度犯罪',
' 自适应学习图像识别 ',
'使用机器学习预测人类活动的方法',
'获胜轨迹',
' 一台机器学习在线设计的方法 ',
'基于大规模的多层特征无监督的多智能音乐方法,
“你能用单手学习”,
“与媒体反应”,
“随着时间的推移测量时间”,
“人们如何停止:学习血液和血液的对象”,
“自动驾驶汽车的机器学习”,
“ 神经网络中的车辆类型 ”,
“为其存储的内容构建模型”,
“用于增强机器学习技术的识别”,
“ 通过机器学习探索纽约市的公众形象 ”,
“一种新颖的职业方法图像识别',
'一般游戏',
'结构分类适应文本',
'语音识别的方差学习方法',
“非优化-对等时间层”,
“一首歌的特点的法律表达”,
‘学习声音英语:学习用单词学习’,学习
‘信息与自适应神经网络共享’,
'玩多点触摸神经网络游戏,
“动态和静态图像的递归估计”,
“预测网络中网络质量的结果”,
“海蛇机器人的特征”,
“预测股票” “机器学习的市场价格”,
“使用反向核苷酸数据来预测卷积蛋白质模型的价格”,
“ 搜索引擎 ”,
'使用Twitter数据预测高成本交易中的价格',
“机器学习方法”,
“创建一种构建深度学习方法的新方法”,
“指纹学习组件”,
“用于建立纽约市大学足球网络的功能变革学习的机器学习技术”,
“预测癌症风险乳腺癌风险',
'癌症诊断和预测',
'股市分类',
' 确定新闻媒体的结果 '
我没有彻底检查,但随机检查告诉我,大多数生成的想法都是独一无二的。我认为生成的文本没有从训练语料库中记忆的原因是因为我们使用的是预训练模型。预训练的语言模型在维基百科上进行了训练,因此即使在查看训练数据之前,它对概念和单词的相关性也有很强的意见。
对于随机初始化的模型,减少训练数据的最简单方法是记住训练语料库。这导致过度拟合。然而,对于预训练的模型,如果网络试图学习训练语料库,则只有在它首先忘记先前学习的权重时才能这样做。由于这会导致更高的错误,更简单的方法是在早期学习的权重的上下文中容纳训练语料库。因此,网络被迫概括并生成语法正确的句子(感谢维基百科上的预训练),但使用特定领域的概念和单词(感谢您的数据集)。
你会用这种方法训练什么?
在预先训练好的模型可用之前,您需要一个巨大的文本语料库来做任何意义。现在,即使是一个小数据集也足以做有趣的事情。请在评论中告诉我您可以使用小文本语料库和预训练模型的项目构思。
让你的神经元射击的一些想法:
使用您的推文,训练一个像您一样的推文模型
使用WhatsApp的数据转储,制作一个像你一样聊天的机器人
对于您的公司,将支持票证分类为BUG或FEATURE REQUEST
制作一个生成类似于您最喜欢的作者的引号的机器人
为Gmail制作自己的自定义AUTO-REPLY草稿
提供照片和Instagram帐户,生成帐户以前字幕样式的标题
为您的博客生成新的博客帖子想法(基于之前的博客文章标题)
此外,如果您最终实现由我的模型(或本文中包含的那个)生成的机器学习项目构思,那将是非常酷的。您将成为世界上第一个机器已经考虑过人类实现的项目的一部分!
感谢您的阅读。请在评论中告诉我您的想法和问题。
PS:查看我之前关于贝叶斯神经网络的动手教程
感谢Nirant Kasliwal审阅本文的草稿并提供了有用的建议。
原文英文链接:https://towardsdatascience.com/generating-new-ideas-for-machine-learning-projects-through-machine-learning-ce3fee50ec2


评论专区