
5.3 用区块链改变征信体系 - 数据结构 - 机器学习
数据结构 - 机器学习
深度学习

当前位置:首页 » 区块链精品文章 » 正文
5.3 用区块链改变征信体系
1101 人参与 2018年09月28日 16:40 分类 : 区块链精品文章 评论
在一个征信体系中,对金融机构有价值的客户大略可以划分为三个部分:
优质客户(白名单)
中间地带的客户
风险客户(黑名单)
对金融机构来说,白名单是主要服务对象,意味着收益。对任何一家机构来说,白名单都是其生命线。而黑名单刚好相反,每家机构都需要仔细做风险控制,不赔钱即为赚钱,能有效地防范一个风险强于成功做成十单生意。
同时,对于中间地带的客户资源,我们都希望能把他们尽量转化为白名单成员,那么这就需要从多个维度、各种琐碎的日常行为中筛选出有用的数据点加以提炼,变成可供金融机构参考的具有含金量的数据。
在国务院印发的《社会信用体系建设纲要》中,关于金融领域是这样描述的:
“加强金融信用信息基础设施建设,进一步扩大信用记录的覆盖面,强化金融业对守信者的激励作用和对失信者的约束作用。”
这其中的描述就是对黑名单和白名单的一个应对指示。其中,“加强金融信用信息基础设施建设”这一句已经将目标锁定在大数据的终端采集上了。
目前的信用数据都是一个个独立的信息孤岛,互相之间并不打通。而在中国,最大的一个孤岛就是央行征信系统中的数据。
在研究了区块链技术之后,我们认为区块链是解决方案中最适合的一种。
笔者认为,央行对于开放征信系统的主要顾虑有两点:
如果把一些虚假的数据上传到央行征信系统的系统里,则可能会造成整个系统的失效。目前有些网贷公司业务操作不够规范,一些业务甚至是编造出来的,相应的数据是虚假的。当这些数据加入到央行征信系统之后,会造成整个系统的可信度下降。
小额贷款公司可能会利用征信系统查询信息的便利转卖征信资料。例如,作为试点城市的重庆,由于不少小额贷款公司借查询征信信息之名转卖个人征信信息,导致对接工作被迫叫停。
但是数据的共享是市场的需求,是征信发展的大趋势。其实不仅是央行对于网贷公司的数据有顾虑,网贷公司对于把自己的数据接入央行的系统也有顾虑。网贷公司如果把自己的数据导入了央行的系统,则极易导致自己的核心业务信息泄露,例如泄露给他们最大的潜在竞争对手——银行。
不积跬步,无以至干里;不积小流,无以成江海。想要一下子改变或者优化整个征信体系,是不可能做到的,无论用什么技术都是不可能的。
下面我们来看一下如何利用区块链天然独有的特性做一个征信系统。
有数据交换、数据共享就需要数据定价。
这里就可以有不同的形式。那么数据定价应该是由政府主导,还是由行业协会协调,抑或是完全市场化地交换?
每个企业拥有的数据是不同的,例如工商银行的数据规模将近300TB,覆盖4.1亿的个人客户和460万的法人客户的直接金融数据,这样的数据如何估值?
我们来看基于区块链的黑名单案例和白名单案例。之前,笔者和区块链圈子里的咕噜同学深入探讨过如何用区块链系统来做征信体系的问题,他在这个领域也有一些很独到的见解,很期望看到他在这个领域的尝试。
案例:基于区块链的黑名单
愚公移山,障碍是一步步移除的。目前,贷款机构对数据分享最紧迫的需求是对黑名单的分享。目前网贷公司对于欠债不还的这些人,除加入黑名单进行曝光外,还没有更好的方法。
不过,如果数据不共享,即使某人上了一家公司的黑名单,那么他依然可以从另一家公司借到钱。
作为中国P2P第一豪门的“陆金所”,其联合拍拍贷等10家网络信贷服务业企业成立了“网络信贷服务业企业联盟”,而它们首先计划共享的就是黑名单。
如果是传统意义上的共享,那么大家一起共享的结果是一个巨大的数据中心系统,参与的这些机构都可以在这个系统上进行查询,但这里可能存在的问题有三个:
(1)数据是可被修改的。因为是中心化的,所以这里就是源头,存在数据被篡改与数据丟失的风险。
(2)数据汇总和更新速度不可控。
(3)存在数据访问权限的问题。
(4)如果要保证查询速度,则系统的构建存在复杂度的问题,否则系统的运行会慢到不可用的程度。
对应的解决方法是:
(1)将中心化的存储变为去中心化的分布式存储。
(2)使用区块链技术,使得每个节点的数据是完全同步的。
(3)区块链技术使得数据是不可被篡改的。如果出现虚假数据,则可以迅速找到源头。
(4)设置数据汇总和更新规则。
(5)变统一中心节点查询为P2P的方式。
(6)设置权限访问机制,只有正确的密钥才能访问数据。

在本章的前两节中已经提到了个人与企业信息采集的几个维度,这是我们做数据分析的依据。各家机构将自身汇总的数据统一到一个平台下,同时能够按需求快速地获取数据。
需求
下面做一个简单的市场需求假设。对一家金融机构来说,其有以下几个需求。
需求1
系统能够给该公司提供信用调查和风控防范的数据支撑。需求2
该系统需要是真实有效的,不会有被人为篡改的可能,该公司要有参与监控的能力。需求3
该公司参与的方式不是被动地提供数据,而是主动地参与数据共享。需求4
如果别人查询了该公司的数据,则还能够分享一部分收益。需求5
该公司查询同行的数据速度越快越好。需求6
同行提供的数据越新越值钱,旧的数据相对廉价。需求7
信息并不对所有的用户开放,而是对相关的金融机构开放。参与的金融机构如果没有提供足够的数据,则需要付费查询或者限制查询。
针对上述问题,来看一下基于区块链的解决方案。
问题分析(基于区块链的黑名单征信系统)
对金融机构来说,对黑名单的数据存储和数据共享是迫在眉睫的事情。
黑名单是民间的叫法,官方称作信用不良记录。
在银行体系里,信用不良记录就是黑名单,也叫信用污点。而银行并不会一直关注消费者早期的信用不良记录,还贷逾期类的信用不良记录保存周期为5年,也就是说,只要你保持5年足额按时还款,即可回归清白之身。
我们也不提供无偿信息共享,毕竟“物美”而“价廉”的东西不是那么牢靠。我们需要有参与度,保持数据的多样性。
最后一点,我们需要尽量实时地分享数据,特别是信用不良记录数据。
我们可以借助区块链技术来实现这个系统:
(1)制定统一遵守的黑名单登记规则。
(2)有偿性提供各自的黑名单列表。
(3)以区块链公钥加密方式保证数据的可靠性。
(4)有偿性地进行数据查询。
(5)名单以分布式账本形式存储,确保数据不可被篡改。
这个系统有如下的特点:
公钥加密:通过密码学协议加密之后的加密数据统一提交拷贝数据,保证不会被篡改。
私钥解密:区块链中的ID按照权限设定,查询相关数据时验证身份ID,具备同等查询权限方可进行查询。
不可更改:一次查询也可被视为一次交易,并且为不可逆操作,确保查询源头可被追查。
等价交换:一家金融机构提供100万条数据,如果总计得分100万分,那么这就是它相应的查询份额,可查询同等价值的数据信息。
有偿服务:通过ID审核,具有查询权限的一个ID在查询金融机构A提供的这100万条可供查询的数据时,会增加金融机构A的查询份额。例如每被查询一次,金融机构A增加一次查询同等价值信息的机会。
获取积分:金融机构A提供了100万条数据,按照价值核定规则,其获得100万查询积分,每进行一次查询,扣除相应积分。当积分用完时,可以有两种途径进行积分获取:一是提供价值数据,二是付费购买积分。
解密查询:身份ID验证设定金融机构能查询哪一类信息,例如个人贷款信息、企业贷款信息、个人信用卡等,每一类信息价值不同,每次查询时扣除相对应的积分。
权限设定:当金融机构只想开放查询权限给具有相应查询权限的另一类ID时,数据对于不具有查询权限的其他成员是不可见的。

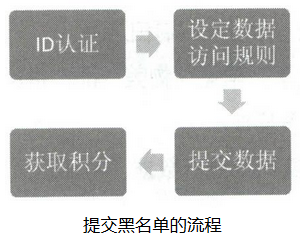
在这个黑名单系统上,我们需要设定一些规则。
时间规则
系统以存入的数据时间戳为标准,总的原则是时间越久远的数据,获取的分值越低,时间越近的数据,获取的分值越高。例如:
一个月之内的数据每条10分
三个月之内的数据每条9分
半年之内的数据每条8分
一年之内的数据每条6分
两年之内的数据每条3分
三年之内的数据每条2分
三年以上的数据每条1分
当然,究竟每条数据的分值应该分配多少还需要做一些具体的数据测算才能确定。
类别规则
系统区分个人、微型企业、小企业、中型企业、大型企业等类别,对应的类别数据价值的基准权重略有不同,例如按上述排序依次记为10、15、20、40、100等。在存入数据的时候,时间规则要和类别规则一起来确定存入数据的价值。
ID分配规则
每个区块链的成员有自己的ID,系统根据最开始约定的条件来规定每个ID的权限。例如有的成员只能查询个人数据,有的只能查询小微企业数据等。
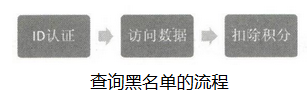
查询规则
成员根据相应ID身份验证查询数据信息时,会被扣除相应的积分。获取的数据量越大,需要扣除的积分就越多。不过我们可以对每一条查询所需要扣除的积分设定一个上限。
更新规则
系统根据时间戳,动态更新数据信息价值核算,即不同时间点提交的相同数据价值有所不同,获取积分不同,而查询花费的积分也不相同。
案例:基于区块链的白名单
对 于时下刚过热潮的P2P金融,其中乱象丛生,“跑路潮”在2015年集体爆发,究其原因,最大的问题可能是信息不对称。如果每个潜在的贷款机构不能确切地 知晓借款者从其他贷款机构已经或者即将获得的信贷额信息,则多银行借贷关系的成本会逐渐加大。在此前提下,在上文中提到的黑名单便成了解决手段之一。
然而重病还需猛药治,光有黑名单是不够的,我们更加需要白名单。
在 很多情况下,申请借款的个人或者企业都会同时向很多不同的贷款机构申请信贷,这种情况被称为多银行借贷关系。在英国和挪威等国家,可同时借贷的银行数量相 对较小,平均数量少于3家,在荷兰、瑞士和芬兰等国家,平均数量为3~4家。但在包括中国在内的许多国家中,可同时借贷的银行数量就没有限制了。
从单个贷款机构的角度看,一个借款者的风险大小在于债权到期时借款者的还款能力,而这取决于他们的负债总额。然而,如果贷款机构不知道其他贷款机构发放的总贷款金额,同时都发放了贷款,那么借款者就有可能会过度借贷!
贷款者的借贷信息被称为正面数据,其与被称为负面数据的黑名单相对。而正面数据中最精华的部分被称为白名单,也就是优质借贷企业、个人的名单。这是每家借贷机构的业务核心。
缺 乏正面数据的征信系统是不完整的。在2003年之前,中国香港是不共享正面数据的。在此之前据传发生过一个非常极端的案例,一个被称为“信贷之皇”的借贷 人,在两年间,总共申请了72个信贷账户,而第一次拖欠贷款是在其第72个账户审核通过之后才发生的。正因为正面数据没有被分享,每家银行都不知道其他 71个账户的存在,同时也没有看到他之前有拖欠贷款的情况,当然会基于他的个人信息批准他所申请的贷款。
商务部直属机构,国际贸易经济合作研究院正在酝酿制定《互联网金融机构信用评级与认证标准》,有望成为我国首个互联网金融机构信用评级和认证的国家标准,也就是所谓的P2P金融平台的“白名单”。
国际贸易经济合作研究院的调研数据显示,截止到2015年11月,跑路的P2P平台已经达到了1079家,这使得国家寄希望于“白名单”的出台能从根本上解决这一问题。
《互联网金融机构信用评级与认证标准》的立足点有三个:
其一:制定统一的信用评级与认证标准。
其二:建立统一的数据库。
其三:需要一个客观的第三方信息披露。
不 过我们所说的白名单不应该是死的规定,而应该是活的规则;我们并不需要大而全的统一,而是具体到每个数据点的细则。统一的数据库如果是一个中心化的数据 库,就会有在前面“黑名单”一节中描述的各种问题。而第三方的信息披露如果要保持完全中立,则只能通过利益完全不相关的律师事务所和会计事务所等,但这可 能会引发出更多的问题。
下面我们用类似于“黑名单”一节中介绍的方式来实现“白名单”。我们可以将白名 单一分为二:清白无前科与信用记录良好。无前科是戏谑的说法,说白了就是从来没有做过贷款申请之类活动的记录,没有记录当然也就没有不良记录。而信用记录 良好指的是有过类似贷款还款记录,但均按时足额还贷,没有不良信用记录。
第一类“小白客户”其实对金融机构来说并不是其特别关注的。它们更加需要的是金融活动信息第一时间的共享。
第二类客户是每家金融机构的核心资产。数据显示,此类客户的忠诚度相对较高,通常很少选择多个金融机构进行金融活动。
需求分析
下面简单做一个市场需求的假设。对一家金融机构来说:
问题1
该机构是否可以用它们的白名单交换行业中其他公司的同等优质数据?问题2
该机构是否可以用它们过去的历史记录来交换行业中其他公司的数据?问题3
该机构提供的数据能否没有不良影响?问题4
该机构可以怎样保护系统数据的安全性?问题5
该机构能否只和部分机构做数据交换?问题6
能否保证系统上的数据是不会被篡改的?
问题分析(基于区块链的白名单系统)
其实,金融公司之间进行某些信息交换已经成了常态,不过目前还没有一种方式能够很好解决我们在上面提出的这些问题。我们需要的是一种更好的信息共享方法,能够让金融公司提供一种有偿性的信息资源分享服务,同时能够获取有价值的信息。
每家金融机构不一定愿意共享它们最核心的用户数据,如果要分享,则它们需要能够换回一些等值的其他信息。
每家金融机构都会有一些沉积的历史数据是它们愿意分享的,如果分享这些数据还能够让它们获取一些等价的信息查询和利益,那么就完美了。
我们不提供无偿信息共享,毕竟“物美”而“价廉”的东西不是那么牢靠。
我们需要有较高的参与度,保持数据的多样性。
有些金融机构的数据共享要有权限设定,它们并不希望所有人都能够查询到它们提供的数据。
我们可以借助区块链技术来实现这个系统,下面梳理一下上面提出的需求和问题分析。
(1)采用无中心化的分布式信息存储与共享:公开透明的数据库保存了所有交易记录,记录中有交易的详细信息,并以密码学协议的方式杜绝了作假的可能。
(2)可以让系统中所有的成员都参与,提供信息的成员可以获得对应的积分奖励,查询信息的成员需要扣除对应的积分。
(3)有价值的信息可以帮助系统上的成员提供潜在客户。
(4)分布式账本提供了一种点对点查询方式。
(5)系统上是有权限设定的,每个数据提供方都可以限制哪些成员可以访问它们提供的数据。
这个白名单系统有如下的特点,大部分和之前的黑名单类似。
公钥加密:通过密码学协议加密之后的加密数据统一提交拷贝数据,保证不会被篡改。
私钥解密:区块链中的ID按照权限设定,查询相关数据时验证身份ID,具备同等查询权限方可进行查询。
不可更改:一次查询也可被视为一次交易,并且为不可逆操作,确保查询源头可被追查。
等价交换:一家金融机构提供100万条数据,如果总计得分100万分,则这就是它相应的查询份额,可查询同等价值的数据信息。
有偿服务:通过ID审核,具有查询权限的一个ID在查询金融机构A提供的这100万条可供查询的数据时,会增加金融机构A的查询份额。例如每被查询一次,金融机构A增加一次查询同等价值信息的机会。
获取积分:金融机构A提供了100万条数据,按照价值核定规则,获得100万查询积分,每进行一次查询,扣除相应积分。当积分用完时,可以有两种途径获取积分:一是提供价值数据,二是付费购买积分。
解密查询:身份ID验证设定金融机构能查询哪一类信息,例如个人贷款信息、企业贷款信息、个人信用卡等,每一类信息价值不同,每次查询时扣除相对应的积分。
权限设定:当金融机构只想开放查询权限给具有相应查询权限的另一类ID时,则数据对于不具有查询权限的其他成员是不可见的。
在这个白名单系统上,我们同样需要设定一些规则。它们与上一节基于区块链的黑名单系统上的规则基本上是一致的。在系统实施上的不同点在于,“黑名单”在更多时候是用于排查我们不能合作的对象,而“白名单”在更多时候是为了找寻潜在客户。
时间和金额规则
系统以存入的数据时间戳为标准,总的原则是时间越久远的数据,获取的分值越低,时间越近的数据,获取的分值越髙。例如:
一个月之内的数据每条10分
三个月之内的数据每条9分
半年之内的数据每条8分
一年之内的数据每条6分
两年之内的数据每条3分
三年之内的数据每条2分
三年以上的数据每条1分
不过,和黑名单中的时间规则不同之处在于,因为白名单中包含的是正向的借款信息,所以时间规则的重要性要和借款的金额数量作比对,时间规则的价值需要叠加借款的金额作为权重。一个月内借款100元和两年前借款100000元比起来,肯定还是后者的数据价值更大。
类别规则
系统区分个人、微型企业、小企业、中型企业、大型企业等类别,对应的类别数据价值的基准权重略有不同,例如按上述排序依次记为10、15、20、40、100等。在存入数据的时候,时间规则要和类别规则一起来确定存入数据的价值。
ID分配规则
每个区块链的成员有自己的ID,系统根据最开始约定的条件来规定每个ID的权限。例如有的成员只能查询个人信息,有的只能查询小微企业信息。
查询规则
成员根据相应的ID身份验证查询数据信息时,会被扣除相应的积分。获取的数据量越大,被扣除的积分就越多。不过我们可以对每一条查询所需要的积分设定一个上限。
更新规则
系统根据时间戳,动态地更新数据信息价值核算,即不同时间点提交的相同数据价值有所不同,获取积分也不同,而查询花费的积分也不相同。
————————————————————
(1) 我们尤其关注“差评”是因为在今天的互联网上,全五星的评论往往是不真实的。请见笔者翻译的《社交电商》一书。
来源:我是码农,转载请保留出处和链接!
本文链接:http://www.54manong.com/?id=845
微信号:qq444848023 QQ号:444848023
加入【我是码农】QQ群:864689844(加群验证:我是码农)
- 第四章 区块链的应用前景2018-09-21 10:38
- 1.3 区块链技术平台2018-10-15 11:24
- 众筹2018-09-25 11:18
- 4.6 Paxos算法与Raft算法2018-09-30 10:25
网站分类
- 数据结构
- 数据结构视频教程
- 数据结构练习题
- 数据结构试卷
- 数据结构习题解析
- 数据结构电子书
- 数据结构精品文章
- 区块链
- 区块链精品文章
- 区块链电子书
- 大数据
- 大数据精品文章
- 大数据电子书
- 机器学习
- 机器学习精品文章
- 机器学习电子书
- 面试笔试
- 物联网/云计算
标签列表
- 数据结构 (39)
- 数据结构电子书 (20)
- 数据结构习题解析 (8)
- 数据结构试卷 (10)
- 区块链是什么 (261)
- 数据结构视频教程 (31)
- 大数据技术与应用 (12)
- 百面机器学习 (14)
- 机器学电子书 (29)
- 大数据电子书 (37)
- 程序员面试 (10)
- RFID (21)
最近发表
- 找出数组中有3个出现一次的数字
- 《百面机器学习》电子书下载
- 区块链精品电子书《深度探索区块链:Hyperledger技术与应用_区块链技术丛书》张增骏
- 区块链精品电子书《比特币:一个虚幻而真实的金融世界》
- 区块链精品电子书《图说区块链》-徐明星 & 田颖 & 李霁月
- 区块链精品电子书《是非区块链:技术、投机与泡沫》-英国《金融时报》
- 区块链精品电子书《商业区块链:开启加密经济新时代》-威廉·穆贾雅
- 区块链精品电子书《人工智能时代,一本书读懂区块链金融 (互联网_时代企业管理实战系列)》-马兆林
-
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https'){
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else{
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
全站首页 | 数据结构 | 区块链| 大数据 | 机器学习 | 物联网和云计算 | 面试笔试
var cnzz_protocol = (("https:" == document.location.protocol) ? "https://" : "http://");document.write(unescape("%3Cspan id='cnzz_stat_icon_1276413723'%3E%3C/span%3E%3Cscript src='" + cnzz_protocol + "s23.cnzz.com/z_stat.php%3Fid%3D1276413723%26show%3Dpic1' type='text/javascript'%3E%3C/script%3E"));本站资源大部分来自互联网,版权归原作者所有!






评论专区