
4.1 大数据时代 - 数据结构 - 机器学习
数据结构 - 机器学习
深度学习

当前位置:首页 » 区块链精品文章 » 正文
4.1 大数据时代
1112 人参与 2018年09月28日 16:53 分类 : 区块链精品文章 评论
2011年6月,美国数据研究中心IDC发布了年度数字研究报告Extracting Value from Chaos(《从混沌中提取价值》),在文中对于数据的预测提到了三点:
全球数据量大约每两年翻一番。
预计2011年全球数据总量将达到1.8ZB(1)。
未来全球数据量增速将会维持,到2015年全球数据量将达到近8ZB,预计到2020年全球数据量将达到令人恐怖的35ZB。
而同年10月,市场调研机构Gartner高德纳公司在分析2012年十大战略技术中就包括了“大数据”。
我 们今天所处的互联网时代是Web 2.0时代,和之前的互联网最大的不同点就在于UGC(User-generated Content,由用户自主产生内容)。每个互联网用户不仅仅是一个信息的被动接受者,同时还是一个信息的创造者。除接受大量的信息外,我们每天还通过微 博和微信产生大量的数据。
价值,大数据的第四个“V”
那么,究竟什么是大数据呢?
IBM 提出了“大数据”的“三V”特征,即大量化(Volume)、多样化(Variety)和快速化(Velocity),这些特征正在给现在的IT企业带来 巨大的挑战。所谓“三V”是因为这三个英文词Volume、Variety和Velocity的首字母都是“V”。
大数据的“大”指的不仅仅是数据量本身庞大,数据样式变化多和增量速度快也是“大”的一个体现。

价值(Value)是大数据的“四V”中最重要的一项
从 2013年开始,大家意识到了大数据不只是一个理论上的概念,着眼于数据商业应用的专家们提出了大数据的“四V”概念。“四V”概念其实就是在原有的“三 V”基础上增加了第四个首字母为“V”的英文词,价值——Value,其指的是企业要实现的是大数据的价值,也就是数据运营和应用的重要性。
在“大数据”时代,数据已经成为企业的核心资产,如何充分利用历史产生的和每天产生的海量数据,如何从海量数据中提取有价值(Value)的信息,如何把信息转化成商业智能的知识和规则,对企业生成竞争力乃至成败起到至关重要的作用。
从当年的《New Internet:大数据挖掘》开始笔者的观点就是:
数据是否“大”并不重要,重要的是能否从数据中挖掘出有价值的信息。原始的数据越丰富,能够挖掘出的信息就越有价值。
数据挖掘过程和应用
什么是数据挖掘呢?
古人云:“物以类聚”。这句话其实描述的就是数据挖掘中的一种算法——聚类算法。要看一个人是怎样的,只需要看他周围都有什么样的朋友。而从数据挖掘的角度来说,聚类算法要预测一个对象的特征,只需要看它周围对象的数据特征。
简而言之,数据挖掘(Data Mining)是有组织、有目的地收集数据,通过分析数据使之成为信息,从而从大量的数据中寻找潜在规律以形成规则或知识的技术。
本节简单介绍一下数据挖掘的过程和应用场景。
数据挖掘过程
一个数据挖掘项目的生命周期在不同的场景下并不是完全一样的。CRISP-DM是官方标准之一,也是对数据挖掘过程的一个全面评述。
如下图所示,CRISP-DM认为一个数据挖掘项目的生命周期包含6个阶段。这6个阶段的顺序是不固定的,我们经常需要调整这些阶段。这依赖每个阶段或是某个阶段中特定任务的产出物是否是下一个阶段必需的输入。
在下图中,最外面这一圈表示数据挖掘自身的循环本质,每一个解决方案发布之后代表另一个数据挖掘的过程已经开始了。在这个过程中得到的知识可以触发新的商业问题,而后续的过程可以从前一个过程得到益处。
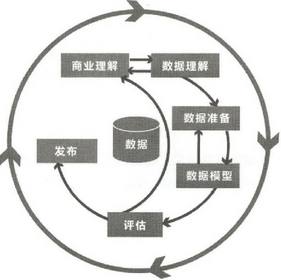
CRISP-DM数据挖掘过程示意图
CRISP-DM的数据挖掘生命周期中的6个阶段,也就是上图中的概念解释如下:
·商业理解
最初的阶段集中在理解项目目标和从业务的角度理解需求,同时将这些转化为数据挖掘问题的定义和完成目标的初步计划。
·数据理解
数据理解阶段是从初始的数据收集开始的,目的是熟悉数据,识别数据的质量问题,首次发现数据的内部属性,或是探测引起我们产生兴趣的子集从而形成隐含信息的假设。
·数据准备
在数据准备阶段包括从未处理的数据中构造最终数据集的所有活动。这些数据将是模型工具的输入值。这个阶段的任务有的能执行多次,没有任何规定的顺序。任务包括选择表、记录和属性,以及为模型工具转换和清洗数据。
·数据模型
在这个阶段,可以选择和应用不同的模型技术,模型参数被调整到最佳的数值。一般,有些技术可以解决一类相同的数据挖掘问题。有些技术在数据形成上有特殊的要求,因此需要经常跳回到数据准备阶段。
·评估
到 了这个阶段,你已经从数据分析的角度建立了一个高质量显示的模型。在开始部署模型之前,重要的事情是彻底地评估模型,检查构造模型的步骤,确保模型可以完 成业务目标。这个阶段的关键目的是确定是否有重要的业务问题没有被充分考虑。在这个阶段结束后,对于一个数据挖掘结果使用的决定必须达成。
·发布
通 常,模型的创建不是项目的结束。模型的作用是从数据中找到知识,并且所获得的知识要以便于用户使用的方式重新组织和展现。根据需求,在这个阶段可以产生简 单的报告,或是实现一个比较复杂、可重复的数据挖掘过程。在很多案例中,这个阶段是由客户而不是数据分析人员承担部署的工作。
下面看两个在数据挖掘中常见的两个应用。
估 测(Estimation)和预测(Prediction)是数据分析和数据挖掘过程中比较常用的应用。估测应用是用来猜测现在的某一个未知值,而预测应 用是用来预测未来的某一个未知值。估测和预测在很多时候都可以使用同样的算法。估测通常用来为一个存在但是未知的数值填空,而预测的数值对象发生在未来, 往往目前并不存在。
举例来说,如果我们不知道某人的具体收入,则可以通过与其收入密切相关的其他信息来 估测,然后找到具有类似特征的其他人,利用他们的收入来估测未知者的收入和信用值。同样以某人的未来收入为例来谈预测,我们可以根据历史数据来分析收入和 各种变量的关系以及时间序列的变化,从而预测他在未来某个时间点的具体收入会是多少。
估测和预测在很多时候也可以连起来应用。例如我们可以根据购买模式来估测一个家庭的孩子个数和家庭人口结构;或者根据购买模式,估测一个家庭的收入,然后预测这个家庭将来最需要的产品和数量,以及需要这些产品的时间点。这里的产品可以是实体产品和服务,也可以是金融产品。
估测和预测所做的数据分析可以被称作预测分析(Predictive Analysis),现在预测分析被不少商业客户和数据挖掘行业的从业人员当作数据挖掘的同义词。这两项技术也是金融领域中的用户最常使用的。
来源:我是码农,转载请保留出处和链接!
本文链接:http://www.54manong.com/?id=852
微信号:qq444848023 QQ号:444848023
加入【我是码农】QQ群:864689844(加群验证:我是码农)
- 9.4 比特币作为一个公共的随机源2018-09-12 11:19
- 9.7 网络拥堵:大量交易的确认延迟2018-08-22 23:18
- 数字票据2018-09-25 16:08
- 第8章 超级账本项目2018-09-30 14:20
网站分类
- 数据结构
- 数据结构视频教程
- 数据结构练习题
- 数据结构试卷
- 数据结构习题解析
- 数据结构电子书
- 数据结构精品文章
- 区块链
- 区块链精品文章
- 区块链电子书
- 大数据
- 大数据精品文章
- 大数据电子书
- 机器学习
- 机器学习精品文章
- 机器学习电子书
- 面试笔试
- 物联网/云计算
标签列表
- 数据结构 (39)
- 数据结构电子书 (20)
- 数据结构习题解析 (8)
- 数据结构试卷 (10)
- 区块链是什么 (261)
- 数据结构视频教程 (31)
- 大数据技术与应用 (12)
- 百面机器学习 (14)
- 机器学电子书 (29)
- 大数据电子书 (37)
- 程序员面试 (10)
- RFID (21)
最近发表
- 找出数组中有3个出现一次的数字
- 《百面机器学习》电子书下载
- 区块链精品电子书《深度探索区块链:Hyperledger技术与应用_区块链技术丛书》张增骏
- 区块链精品电子书《比特币:一个虚幻而真实的金融世界》
- 区块链精品电子书《图说区块链》-徐明星 & 田颖 & 李霁月
- 区块链精品电子书《是非区块链:技术、投机与泡沫》-英国《金融时报》
- 区块链精品电子书《商业区块链:开启加密经济新时代》-威廉·穆贾雅
- 区块链精品电子书《人工智能时代,一本书读懂区块链金融 (互联网_时代企业管理实战系列)》-马兆林
-
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https'){
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else{
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
全站首页 | 数据结构 | 区块链| 大数据 | 机器学习 | 物联网和云计算 | 面试笔试
var cnzz_protocol = (("https:" == document.location.protocol) ? "https://" : "http://");document.write(unescape("%3Cspan id='cnzz_stat_icon_1276413723'%3E%3C/span%3E%3Cscript src='" + cnzz_protocol + "s23.cnzz.com/z_stat.php%3Fid%3D1276413723%26show%3Dpic1' type='text/javascript'%3E%3C/script%3E"));本站资源大部分来自互联网,版权归原作者所有!






评论专区