
4.8 可靠性指标 - 数据结构 - 机器学习
数据结构 - 机器学习
深度学习

当前位置:首页 » 区块链精品文章 » 正文
4.8 可靠性指标
1185 人参与 2018年09月30日 10:23 分类 : 区块链精品文章 评论
可靠性(availability),或者说可用性,是描述系统可以提供服务能力的重要指标。高可靠的分布式系统往往需要各种复杂的机制来进行保障。
通常情况下,服务的可用性可以用服务承诺(Service Level Agreement,SLA SLA)、服务指标(Service Level Indicator,SLI)、服务目标(Service Level Objective,SLO)等方面进行衡量。
4.8.1 几个9的指标
很多领域里谈到服务的高可靠性,都喜欢用几个9的指标来进行衡量。几个9,其实是概率意义上粗略反映了系统能提供服务的可靠性指标,最初是电信领域提出的概念。
表4-1给出同指标下每年允许服务出现不可用时间的参考值。
表4-1 同指标下,每年允许服务出现不可用时间的参考值
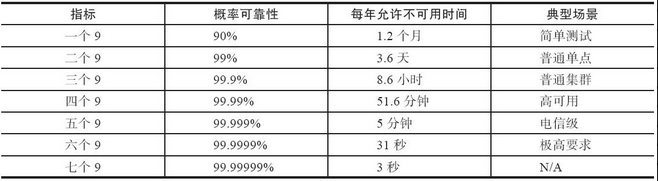
一般来说,单点的服务器系统至少应能满足两个9;普通企业信息系统三个9就肯定足够了(大家可以统计下自己企业内因系统 维护每年要停多少时间),系统能达到四个9已经是领先水平了(参考AWS等云计算平台)。电信级的应用一般需要能达到五个9,这已经很厉害了,一年里面最 多允许出现五分钟左右的服务不可用。六个9以及以上的系统,就更加少见了,要实现往往意味着极高的代价。
4.8.2 两个核心时间
一般地,描述系统出现故障的可能性和故障出现后的恢复能力,有两个基础的指标:MTBF和MTTR:
·MTBF(Mean Time Between Failures):平均故障间隔时间,即系统可以无故障运行的预期时间;
·MTTR(Mean Time to Repair):平均修复时间,即发生故障后,系统可以恢复到正常运行的预期时间。
MTBF衡量了系统发生故障的频率,如果一个系统的MTBF很短,则往往意味着该系统可用性低;而MTTR则反映了系统碰到故障后服务的恢复能力,如果系统的MTTR过长,则说明系统一旦发生故障,需要较长时间才能恢复服务。
一个高可用的系统应该是具有尽量长的MTBF和尽量短的MTTR。
4.8.3 提高可靠性
如何提升系统的可靠性呢?有两个基本思路:一是让系统中的单个组件都变得更可靠;二是干脆消灭单点。
IT从业人员大都有类似的经验,普通笔记本电脑,基本上是过一阵可能就要重启一下;而运行Linux/Unix系统的专 用服务器,则可能连续运行几个月甚至几年时间都不出问题。另外,普通的家用路由器,跟生产级别路由器相比,更容易出现运行故障。这些都是单个组件可靠性不 同导致的例子,可以通过简单升级单点的软硬件来改善可靠性。
然而,依靠单点实现的可靠性毕竟是有限的。要想进一步地提升,那就只好消灭单点,通过主从、多活等模式让多个节点集体完成原先单点的工作。这可以从概率意义上改善服务对外的整体可靠性,这也是分布式系统的一个重要用途。
分布式系统是计算机科学中十分重要的一个研究领域。随着现代计算机集群规模的不断增长,所处理的数据量越来越大,同时对于性能、可靠性的要求越来越高,分布式系统相关技术已经变得越来越重要,起到的作用也越来越关键。
分布式系统中如何保证共识是个经典的技术问题,无论在学术上还是工程上都存在很高的研究价值。令人遗憾地是,理想的(各 项指标均最优)解决方案并不存在。在现实各种约束条件下,往往需要通过牺牲掉某些需求,来设计出满足特定场景的协议。通过本章的学习,读者可以体会到在工 程应用中的类似设计技巧。
实际上,工程领域中不少问题都不存在一劳永逸的通用解法;而实用的解决思路是,合理地在实际需求和条件限制之间进行灵活的取舍。
来源:我是码农,转载请保留出处和链接!
本文链接:http://www.54manong.com/?id=966
微信号:qq444848023 QQ号:444848023
加入【我是码农】QQ群:864689844(加群验证:我是码农)
- 1.4 公钥即身份2018-09-12 15:08
- 6.2 如何对比特币去匿名化2018-09-12 14:01
- 9.2 什么是权威证明共识2018-09-15 10:01
- 第5章 创建钱包服务2018-09-15 15:18
网站分类
- 数据结构
- 数据结构视频教程
- 数据结构练习题
- 数据结构试卷
- 数据结构习题解析
- 数据结构电子书
- 数据结构精品文章
- 区块链
- 区块链精品文章
- 区块链电子书
- 大数据
- 大数据精品文章
- 大数据电子书
- 机器学习
- 机器学习精品文章
- 机器学习电子书
- 面试笔试
- 物联网/云计算
标签列表
- 数据结构 (39)
- 数据结构电子书 (20)
- 数据结构习题解析 (8)
- 数据结构试卷 (10)
- 区块链是什么 (261)
- 数据结构视频教程 (31)
- 大数据技术与应用 (12)
- 百面机器学习 (14)
- 机器学电子书 (29)
- 大数据电子书 (37)
- 程序员面试 (10)
- RFID (21)
最近发表
- 找出数组中有3个出现一次的数字
- 《百面机器学习》电子书下载
- 区块链精品电子书《深度探索区块链:Hyperledger技术与应用_区块链技术丛书》张增骏
- 区块链精品电子书《比特币:一个虚幻而真实的金融世界》
- 区块链精品电子书《图说区块链》-徐明星 & 田颖 & 李霁月
- 区块链精品电子书《是非区块链:技术、投机与泡沫》-英国《金融时报》
- 区块链精品电子书《商业区块链:开启加密经济新时代》-威廉·穆贾雅
- 区块链精品电子书《人工智能时代,一本书读懂区块链金融 (互联网_时代企业管理实战系列)》-马兆林
-
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https'){
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else{
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
全站首页 | 数据结构 | 区块链| 大数据 | 机器学习 | 物联网和云计算 | 面试笔试
var cnzz_protocol = (("https:" == document.location.protocol) ? "https://" : "http://");document.write(unescape("%3Cspan id='cnzz_stat_icon_1276413723'%3E%3C/span%3E%3Cscript src='" + cnzz_protocol + "s23.cnzz.com/z_stat.php%3Fid%3D1276413723%26show%3Dpic1' type='text/javascript'%3E%3C/script%3E"));本站资源大部分来自互联网,版权归原作者所有!






评论专区