
TensorFlow用线性模型分类线性分类器
在本课中,我们将介绍使用TensorFlow进行机器学习。
我们将创建自己的线性分类器,并使用TensorFlow的内置优化算法来训练它。
首先,我们将查看数据以及我们要做的事情。对于那些刚接触机器学习的人来说,我们尝试执行的任务称为监督机器学习或分类。
任务是尝试计算一些输入数据和输出值之间的关系。实际上,输入数据可以是测量值,例如高度或重量,输出值可以是预期的预测值,例如“cat”或“dog”。
这里的教训扩展到我们的融合课程的工作,可以在这里找到。我建议你先完成这一课。
让我们创建并可视化一些数据:
from sklearn.datasets import make_blobs import numpy as np from sklearn.preprocessing import OneHotEncoder X_values, y_flat = make_blobs(n_features=2, n_samples=800, centers=3, random_state=500) y = OneHotEncoder().fit_transform(y_flat.reshape(-1, 1)).todense() y = np.array(y) %matplotlib inline from matplotlib import pyplot as plt # Optional line: Sets a default figure size to be a bit larger. plt.rcParams['figure.figsize'] = (24, 10) plt.scatter(X_values[:,0], X_values[:,1], c=y_flat, alpha=0.4, s=150)
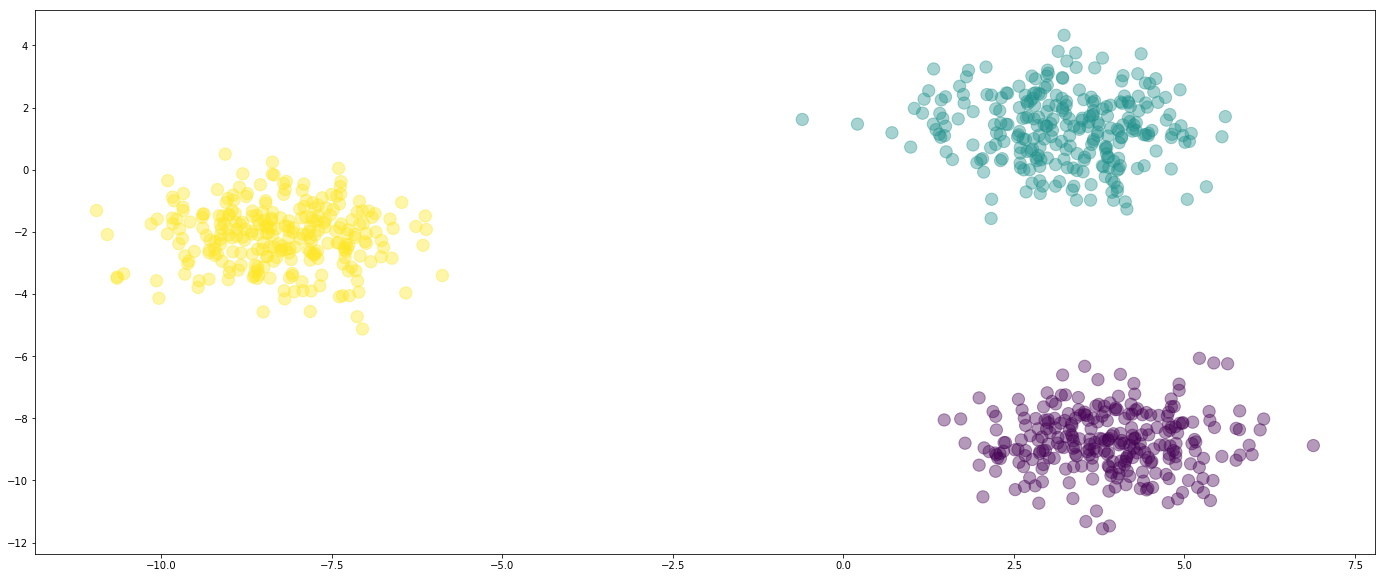
在这里,我们有三个数据,黄色,蓝色和紫色。它们在两个维度上绘制出来,我们称之为x0x0和x1x1。
这些值存储在X数组中。
当我们执行机器学习时,有必要将您的数据分成我们用于创建模型的训练集和我们用来评估它的测试集。如果我们不这样做,那么我们可以简单地创建一个“作弊分类器”,只记得我们的训练数据。通过分裂,我们的分类器必须学习输入(绘图上的位置)和输出之间的关系。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test, y_train_flat, y_test_flat = train_test_split(X_values, y, y_flat) X_test += np.random.randn(*X_test.shape) * 1.5
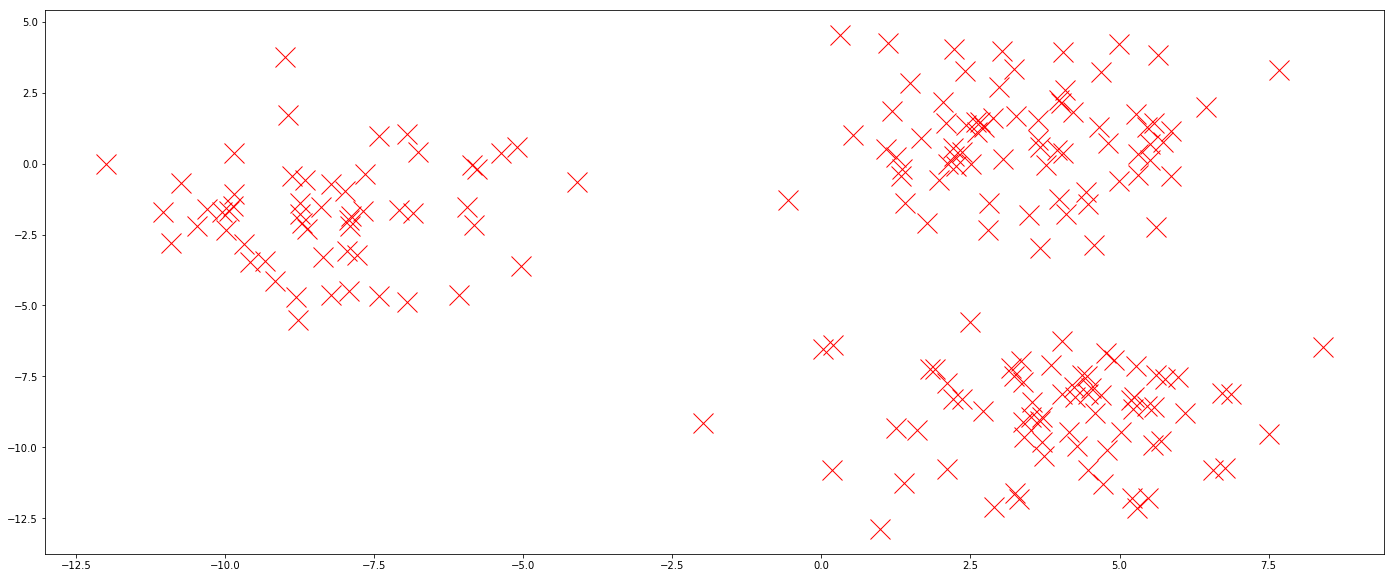
现在我们绘制测试数据。在从训练数据中学习位置和颜色之间的关系之后,将给予分类器以下几点,并且将评估它对点的颜色准确度。
#plt.scatter(X_train[:,0], X_train[:,1], c=y_train_flat, alpha=0.3, s=150) plt.plot(X_test[:,0], X_test[:,1], 'rx', markersize=20)
创建模型
我们的模型将是一个简单的线性分类器。这意味着它将在三种颜色之间绘制直线。一条线上方的点被赋予一种颜色,而一条线下方的点被赋予另一种颜色。我们将这些称为决策线,尽管它们通常被称为决策边界,因为其他模型可以学习比线更复杂的形状。
为了在数学上表示我们的模型,我们使用以下等式:
我们的权重W是(n_features,n_classes)矩阵,表示我们模型中的学习权重。它决定了决策线的位置。 X是(n_rows由n_features)矩阵,并且是位置数据 - 给定点位于图上。最后,b是(1乘n_classes)向量,并且是偏差。我们需要这样,以便我们的线不必经过点(0,0),使我们能够在图上的任何位置“绘制”线。
X中的点是固定的 - 这些是训练或测试数据,称为观察数据。W和b的值是我们模型中的参数,我们可以控制这些值。为这些值选择好的值可以为我们提供良好的决策线。
在我们的模型中为参数选择好的值的过程称为训练算法,并且是机器学习中的“学习”。
让我们从上面得到我们的数学模型,并将其转换为TensorFlow操作。
import tensorflow as tf n_features = X_values.shape[1] n_classes = len(set(y_flat)) weights_shape = (n_features, n_classes) W = tf.Variable(dtype=tf.float32, initial_value=tf.random_normal(weights_shape)) # Weights of the model X = tf.placeholder(dtype=tf.float32) Y_true = tf.placeholder(dtype=tf.float32) bias_shape = (1, n_classes) b = tf.Variable(dtype=tf.float32, initial_value=tf.random_normal(bias_shape)) Y_pred = tf.matmul(X, W) + b
该Y_pred张量表示从我们上面的数学模型。通过传入观测数据(X),我们可以得到预期值,在我们的例子中,是给定点的预期颜色。请注意使用广播在所有预测中应用偏差。
Y_pred中的实际值由“似然”组成,模型将为给定点选择每个类,制作(n_rows by n_classes)大小的矩阵。它们不是真正的可能性,但我们可以通过找到最大值来找出我们的模型认为最有可能的类。
接下来,我们需要定义一个函数来评估给定权重集的好坏程度。请注意,我们尚未学习权重,只是给出了随机值。TensorFlow具有内置的损失函数,可以接受预测的输出(即模型中出现的值)与实际值(我们首次创建测试集时创建的基本事实)。我们比较这些,并评估我们的模型表现如何。我们称之为损失函数,因为我们做得越差,价值越高 - 我们试图将损失降至最低。
loss_function = tf.losses.softmax_cross_entropy(Y_true, Y_pred)
最后一步是创建一个优化步骤,该步骤采用我们的损失函数,并找到给定变量的值,以最大限度地减少损失。请注意,损失函数引用Y_true,它依次引用W和b。TensorFlow选择此关系,并更改这些变量中的值以查找好的值。
learner = tf.train.GradientDescentOptimizer(0.1).minimize(loss_function)
现在为训练位!
我们在循环中传入学习者,以找到最佳权重。每次循环时,前一循环的学习权重会在下一个循环中略有改善。前一行代码中的0.1是学习率。如果增加该值,算法学得更快。但是,较小的值通常会收敛到更好的值。当您查看模型的其他方面时,值为0.1是一个很好的起点。
在每个循环中,我们通过占位符将我们的培训数据传递给学习者。每隔100个循环,我们通过将测试数据直接传递给损失函数来了解我们的模型是如何学习的。
with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(5000): result = sess.run(learner, {X: X_train, Y_true: y_train}) if i % 100 == 0: print("Iteration {}:\tLoss={:.6f}".format(i, sess.run(loss_function, {X: X_test, Y_true: y_test}))) y_pred = sess.run(Y_pred, {X: X_test}) W_final, b_final = sess.run([W, b])predicted_y_values = np.argmax(y_pred, axis=1) predicted_y_values
h = 1 x_min, x_max = X_values[:, 0].min() - 2 * h, X_values[:, 0].max() + 2 * h y_min, y_max = X_values[:, 1].min() - 2 * h, X_values[:, 1].max() + 2 * h x_0, x_1 = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) decision_points = np.c_[x_0.ravel(), x_1.ravel()]
有点复杂,但我们正在有效地创建一个二维网格,涵盖x0和x1的可能值。
# We recreate our model in NumPy Z = np.argmax(decision_points @ W_final[[0,1]] + b_final, axis=1) # Create a contour plot of the x_0 and x_1 values Z = Z.reshape(xx.shape) plt.contourf(x_0, x_1, Z, alpha=0.1) plt.scatter(X_train[:,0], X_train[:,1], c=y_train_flat, alpha=0.3) plt.scatter(X_test[:,0], X_test[:,1], c=predicted_y_values, marker='x', s=200) plt.xlim(x_0.min(), x_0.max()) plt.ylim(x_1.min(), x_1.max())

你有它!我们的模型会将黄色区域中的任何内容分类为黄色,依此类推。如果覆盖实际测试值(存储在y_test_flat中),则可以突出显示任何差异。
绘制迭代和丢失之间的关系。出现什么样的形状,您认为这将如何继续?
使用TensorBoard,将图形写入文件,并查看TensorBoard中变量的值。有关更多信息,请参阅我们的教
通过在传递到线性模型之前对X执行一些变换来创建非线性模型。这可以通过多种方式完成,您的模型的准确性将根据您的选择而改变。
使用以下代码加载64维(称为数字)的数据集,并将其传递给分类器。你得到了什么预测准确度?
from sklearn.datasets import load_digits digits = load_digits() X = digits.data y = digits.target






评论专区