
第23章 案例研究 - 数据结构 - 机器学习
数据结构 - 机器学习
深度学习

当前位置:首页 » 大数据电子书 » 正文
第23章 案例研究
1531 人参与 2018年12月18日 22:57 分类 : 大数据电子书 评论
全球有很多公司和组织使用Hive。本章提供的案例将详细介绍有趣的和独特的使用场景和我们面临过的问题,以及如何使用Hive这个独特的PB级别数据数据仓库来解决这些问题。
23.1 m6d.com(Media6Degrees)
23.1.1 M 6D的数据科学,使用Hive和R
——Ori Stitelman
在本案例研究中,我们考察了m6d的数据科学团队使用Hive对综合的海量数据提取信息的众多方法中的一种。m6d是一家面向展示广告的公司。我们所扮演的角色就是通过创建定制的机器学习算法来为广告宣传活动寻找最好的新前景。这些算法是用于一个交付引擎之上的,其被绑定到无数个实时竞价交易,从而提供基于用户客户端行为的和按照网络地理位置提供广告条展示的方式。m5d广告展示引擎每天都涉及到数十亿的竞价次数和进行数千万次的广告展示。自然,这样的一个系统会产生大量的数据。由本公司的广告展示交付系统产生的大部分的记录是存储在m6d公司的Hadoop集群中的,也因此,Hive是我们的科学家对这些日志进行数据分析的主要工具。
Hive为我们的科学家团队提供了提取和处理大量数据的一种方式。事实上,其允许我们分析在使用Hive之前无法进行有效分析的海量数据,并对其进行样本抽取和数据聚合。尽管事实上Hive允许我们以比之前快很多倍的速度来访问海量数据,但其并不能改变这样一个事实,那就是,以前我们所熟悉的数据科学家并不能以所产生的所有数据作为样本数据进行样本分析,也就是对全局数据进行分析而不是抽样分析。总之,Hive为我们提供了一个提取海量数据的很好的工具。不过,数据科学家在数据科学领域使用的方法工具箱、或在统计学习领域所使用的方法如果不经过实质性的改变的话,则是无法轻易适用于海量数据集分析的。
目前已经有了或者正在开发各种各样的软件包,来对海量数据集进行启发式的和非启发式的知识学习。这些软件中有一些是独立的软件实现,例如Vowpal Wabbit 和BBR,而其他一些是基于像HadoopMahout这样的大型基础架构或其他众多的针对R的“海量数据”处理包进行实现的。这些算法一部分是利用并行编程方法实现的,而其他则是依赖于不同的方法来实现可伸缩性的。
我们团队的几个数据科学家对于统计学习使用的主要工具是R。R提供了众多的包来支持众多的统计算法。更重要的是,我们对于R具有很多的经验,我们知道其是如何执行的,并了解它们的特性,而且非常熟悉其技术文档。不过,R的一个主要缺点是,默认情况下其需要将所有的数据集载入到内存中。这是一个主要的限制。还有就是,一旦R中的数据比可以载入内存的数据要大时,系统就会出现内存交换,导致系统抖动并显著降低处理速度[1]。
我们并不倡导不使用可以使用的新工具。很明显,利用好这些可伸缩技术是非常重要的,但是我们只能有那么多的时间对新技术进行调查和测试。所以现在我们只剩下一个选择,要么对数据进行采样来适应我们更熟悉的工具,要么使用可以用于海量数据分析的新工具。如果我们决定使用新工具的话,那么我们就可以分析更多的数据,因此也就可以降低我们的估算误差。这是非常有吸引力的。对于那些要求结果精确的情况来说这种方式是非常吸引人的。不过,学习使用新工具需要时间成本,也因需要时间学习新工具而不能够去解决其他对公司有价值的问题。
一种替代方式就是我们可以对数据进行向下抽样,以便可以使用我们手头上的旧工具进行分析。不过这样我们需要处理一定的精度损失,会增加我们的估算误差。不过,这样我们就能以我们熟悉的工具来进行数据处理了。因此也就能保持使用我们当前的工具箱,不过会丢失一些精准度。然而,并非只有这两种可行的方法。在本案例研究中,我们推荐一种既能够保持现有工具箱的功能,同时又能在使用更大的样本数据集或整个数据集时保证计算精度或减小误差的方式。
图23-1展示了为某个广告排名设计的算法得出的值的分布情况。更高的分数表示具有更高概率的转换。本图清楚地表明,较高分数的转化率要比较低分数段的转化率低。也就是,分数在1以上的比分数在0.5和1之间的转化率要低。考虑到某些活动只有目标比例非常小的用户群,因此具有最好前景的是最顶端的得分者

图23-1 转换率和得分的概率
图23-1中这条表示分数和转换率之间关系的曲线是使用统计编程包R中的广义相加模型(GAM)[2]生成的。这里就不对GAM进行详细的介绍了。这个案例研究的目的可以认为是一个黑盒,其可以预测出每个分数的转换率。浏览器则可以根据预测的转换率重新进行排名,这样,预测的转换率就变成了新的分数。
可以通过下面的方式来产生新的排名。首先,需要为每个浏览器提取分数,然后在设定的一段时间内跟踪它们,例如5天,并记录下它们所需的动作,然后进行转换。假设Hive中有张名为scoretable的表,其具有表23-1所示的信息,并按照date和offer进行分区。
表23-1 样例表scoretable中的字段信息

下面这个查询语句可以用于从表scoretable中抽取一组数据,用于在R中生成GAM曲线,来预测前面所述表中不同级别分数的预测转换率:
SELECT score,convert
FROM scoretable
WHERE date >= (…) AND date <= (…)
AND offer = (…);
1.2347 0
3.2322 1
0.0013 0
0.3441 0
然后通过如下代码将这些数据加载到R中,再使用前面所提的表的数据生成预测转换率曲线:
library(mgcv)
g1=gam(convert~s(score),family=binomial,data=[data frame name])
这种方式存在一个问题,那就是只能使用有限几天的数据来进行分析。因为一旦使用的数据集太大,甚至只要取稍微大于3天的数据就会导致R无法稳定工作。此外,如果要处理3天的数据量,每次执行都需要10分钟的时间进行初始化。因此,对于一个的计分算法,3天的数据对于大约300个竞价分析来说大约需要消耗50个小时。
使用一个稍微不同的方式,通过简单地从Hive中提取数据,并利用mgcv中提供的gam函数的允许频率权重的功能,同样的分析可以使用更多的数据,获取更多的信息,而执行速度可以更快。通过在Hive中获取分数的最近近似值,并为每个最近近似值估算一个频率权重,通过GROUP BY语句进行转换组合。这是处理大数据集的通用方式,而且这里面并不会因为四舍五入近似关系导致结果信息的不准确,因为没有理由认为,个体分数间相差0.001会有任何的不同。如下这个查询语句将产生这样一个数据集:
SELECT round(score,2) as score,convert,count(1) AS freq
FROM scoretable
WHERE date >= [start.date] and date <= [end.date] and offer = [chosen.offer]
GROUP BY round(score,2),convert;
1.23 0 500
3.23 1 22
0.00 0 127
0.34 0 36
这种方式产生的结果数据集比之前那种没有使用频率权重的方式产生的数据集要小得多。事实上 ,每个提供的初始数据集都含有数百万条记录,而这个新数据集相对每个提供的数据集缩小到了6 500条。这样可以通过如下的命令将新数据集载入到R中并产生新的GAM结果:
library(mgcv)
g2=gam(convert~s(score),family=binomial,weights=freq,
data=[frequency weight data frame name])
前面对于仅仅3天的数据每份提供的数据集创建GAM就需要10分钟的时间,而后者使用频率权重的方式可以在10秒钟左右处理基于7天的数据的GAM计算。因此,通过使用频率权重,对于300个估价,使用之前的方式需要50小时,而使用新的方法后只需要50秒。同时增加的速度也允许使用超过两倍的数据获得更加精确的预测转换概率。总之,频率权重方式可以在很少的时间内获得更精确的GAM预测估算值。
在当前的案例研究中,我们展示了如何通过对连续变量取近似值和使用频率权重进行分组,我们既可以通过使用更多的数据获得更精确的估值,又能消耗更少的计算资源,最终可以最快地进行估算。这个例子只展示了只有单一功能,按照分数计算的模型。一般来说,这种方式适用于低数据特性或者较大数据量的稀疏特性。上述的方法可以扩展到到高维问题,但需要使用其他一些小技巧。处理高维问题的一个方法就是对变量或者特性进行分桶,转换成二进制变量后,再使用GROUP BY进行查询,并对这些特性计算频率权重。然而,随着功能数量的增长,这些功能特性并不稀疏,再使用这种方式几乎就没有什么价值了,这时就需要寻找其他的解决办法,或者是可以处理这种大数据集的工具。
23.1.2 M6D UDF伪随机
——David Ha 和 Rumit Patel
对数据进行排序然后获取最大的N个值,这种需求很直截了当。用户对整个数据集基于某些标准进行排序,然后限制结果集为N条。但有些时候需要对元素进行分组,然后保留每个分组中的排序后的前N条记录。例如,计算每名歌词艺术家的排名前10的歌曲,或者按照商品类别和国家得到最畅销的前100种商品。很多的数据库平台都提供了一个名为rank()的函数,其适用于这些使用场景。在Hive中我们可以通过实现用户自定义函数来达到同样的目的。我们将这个函数命名为p_rank(),这样可以和Hive中使用的rank()有所区别。
假设我们有如表23-2所示的商品销售数据,我们希望查看按照类别和国家的前3名畅销的商品:
表23-2 样例表p_rank_demo中的数据内容
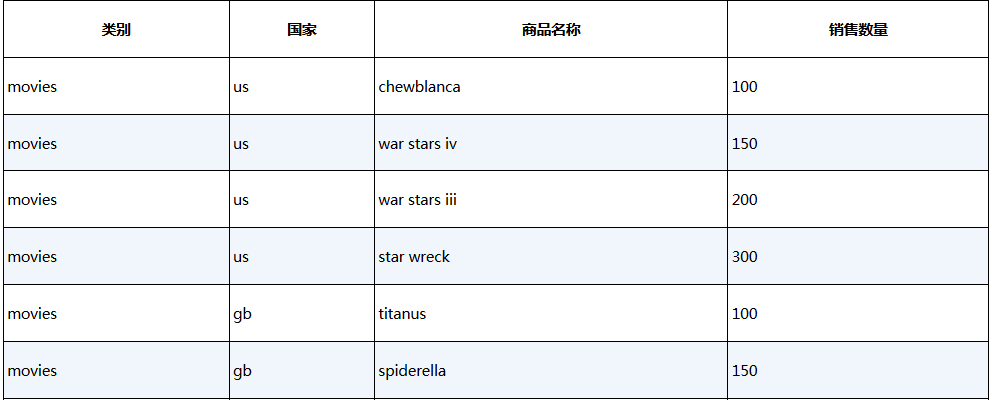
在大多数系统中,如下SQL都是可以执行的:
SELECT
category,country,product,sales,rank
FROM (
SELECT
category,country,product, sales,
rank() over (PARTITION BY category, country ORDER BY sales DESC) rank
FROM p_rank_demo) t
WHERE rank <= 3
如果想通过HiveQL获得相同的结果,那么第一步就需要将数据分成组。我们可以使用DISTRIBUTE BY语句进行分组。我们需要保证具有相同类别和国家的记录都发送到同一个reducer上:
DISTRIBUTE BY
category,
country
下一步就是使用SORT BY语句对每组数据按照销量降序排列。因为ORDER BY会触发全局数据排序,所以SORT BY所涉及的数据会在同一个特定的reducer中进行排序。这里需要重新写上DISTRIBUTE BY语句中的划分列名:
SORT BY
category,
country,
sales DESC
将所有内容都放在一起,就是如下这个样子:
ADD JAR p-rank-demo.jar;
CREATE TEMPORARY FUNCTION p_rank AS 'demo.PsuedoRank';
SELECT
category,country,product,sales,rank
FROM (
SELECT
category,country,product,sales,
p_rank(category, country) rank
FROM (
SELECT
category,country,product,
sales
FROM p_rank_demo
DISTRIBUTE BY
category,country
SORT BY
category,country,sales desc) t1) t2
WHERE rank <= 3
子查询t1重新组织数据,以保证相同的商品类别和国家下的数据按照销售数量降序排列。第2个查询t2会使用到p_rank()函数,并将其命名为rank,其对于每组中的行都会增加一个排名。最外层的查询会限制只保留排名前三的值。经排序后的结果如表23-3所示。
表23-3 对样例表p_rank_demo进行RANK排序后的数据内容
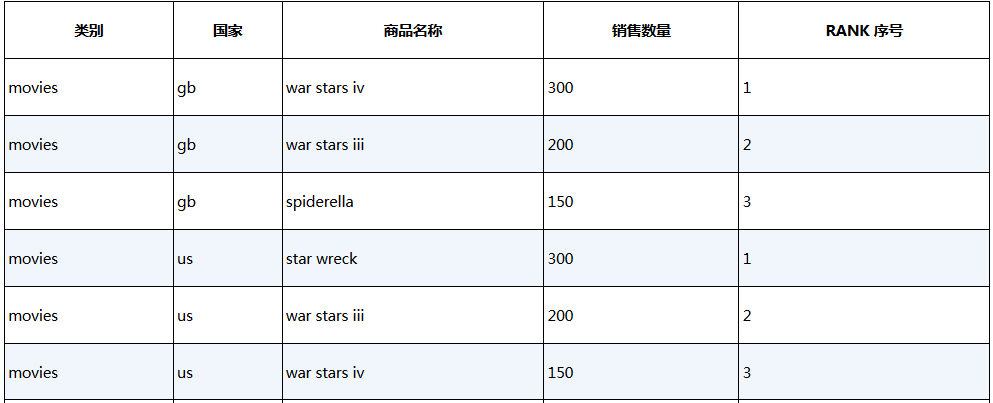
这里是以原生UDF的方式实现p_rank()函数的,其参数都是确定的组属性,在本例中,就是类别和国家。这个函数可以记住上一次的参数值,因此只要成功和参数匹配,就会一直增加数值并返回排列值。一旦和参数不匹配,这个函数就会重置排列值为1,然后重新开始计算。
这仅是个说明如何使用p_rank()函数的简单的例子。用户当然也可以按照类别和国家获取最畅销的第10位到第15位的商品。或者,用户已经计算好了每个商品类别和国家下的商品的个数,那么用户也可以结合JOIN使用p_rank()计算百分比。例如,假设在“movies(电影)”和“us(美国)”组下面有1000种产品,那么第50名、第70名和第95名的RANK值就分别对应于500、700和950。这里需要明确的是,p_rank()并非是rank()函数的替代函数,因为两者在某些情形下是有差异的。例如,对于相同的值,rank()函数返回的值是相同的,但是p_rank()函数仍然会进行累加计算,因此具体使用需要按照期望选择并在数据上进行测试。
下面展示的是具体的代码实现。这份代码是属于公共领域的,所以用户可以随意使用、改进和修改它,以满足个人的需求:
package demo;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.
PrimitiveObjectInspectorFactory;
public class PsuedoRank extends GenericUDF {
/**
* The rank within the group. Resets whenever the group changes.
*/
private long rank;
/**
* Key of the group that we are ranking. Use the string form
* of the objects since deferred object and equals do not work
* as expected even for equivalent values.
*/
private String[] groupKey;
@Override
public ObjectInspector initialize(ObjectInspector[] oi)
throws UDFArgumentException {
return PrimitiveObjectInspectorFactory.javaLongObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] currentKey) throws HiveException {
if (!sameAsPreviousKey(currentKey)) {
rank = 1;
}
return new Long(rank++);
}
/**
* Returns true if the current key and the previous keys are the same.
* If the keys are not the same, then sets {@link #groupKey} to the
* current key.
*/
private boolean sameAsPreviousKey(DeferredObject[] currentKey)
throws HiveException {
if (null == currentKey && null == groupKey) {
return true;
}
String[] previousKey = groupKey;
copy(currentKey);
if (null == groupKey && null != previousKey) {
return false;
}
if (null != groupKey && null == previousKey) {
return false;
}
if (groupKey.length != previousKey.length) {
return false;
}
for (int index = 0; index < previousKey.length; index++) {
if (!groupKey[index].equals(previousKey[index])) {
return false;
}
}
return true;
}
/**
* Copies the given key to {@link #groupKey} for future
* comparisons.
*/
private void copy(DeferredObject[] currentKey)
throws HiveException {
if (null == currentKey) {
groupKey = null;
} else {
groupKey = new String[currentKey.length];
for (int index = 0; index < currentKey.length; index++) {
groupKey[index] = String.valueOf(currentKey[index].get());
}
}
}
@Override
public String getDisplayString(String[] children) {
StringBuilder sb = new StringBuilder();
sb.append("PsuedoRank (");
for (int i = 0; i < children.length; i++) {
if (i > 0) {
sb.append(", ");
}
sb.append(children[i]);
}
sb.append(")");
return sb.toString();
}
}
23.1.3 M6D如何管理多MapReduce集群间的Hive数据访问
尽管Hadoop集群规模可以设计成10到10 000个节点,但是有时特定的部署需求会涉及要在不止一个文件系统或者JobTracker上运行任务。在M6D中,我们有这样的需求,例如我们有一些需要Hadoop和Hive在每小时或每天都可以按时完成的关键业务报告。不过我们的系统也支持数据科学家和销售工程师定期执行的一些特定报告。尽管使用公平调度器和能力调度器已经满足了我们的大部分需求,我们仍需要更高的调度隔离。同时,因为HDFS没有快照或者增量备份功能特性,我们因此需要一个对应的解决方案来防止意外的数据删除或者意外的删除表操作近而避免数据丢失。
我们的解决方案就是运行2个独立的Hadoop集群。在主集群上,数据可以被设置为2份或者3份数据冗余,而且同时会被复制到第2个集群上。这种方式可以保证我们对于时效性强的需求还可以有足够的资源同时提供给临时用户进行使用。此外,我们可以防止任何意外删除表或数据的情况。这种方式确实会增加部署和管理2个集群的开销,而这种开销在我们的使用场景下是合理的。
我们的2个集群分别被称为生产环境和研究环境。其都具有各自的专有数据节点(DataNode)和任务节点(TaskTracker)。每个NameNode和JobTracker节点都是DRBD和Linux-HA的故障恢复方案。这2个集群都是部署在同一个交换网络的(见表23-4和表23-5)。
表23-4 生产环境配置

表23-5 探索环境

1.使用Hive执行跨集群查询
生产集群上存在一张名为zz_mid_set的表,但是我们期望不使用distcp命令就可以在研究集群上查询这张表。通常来说,我们会尽量避免这样的操作,因为其破坏了我们的隔离设计,但是很高兴地是,这样的操作是可以做到的。
通过describe extended命令除了可以查看表具有的字段信息外还可以查看其实际存储的HDFS路径:
hive> set fs.default.name;
fs.default.name=hdfs://hdfs.hadoop.pvt:54310
hive> set mapred.job.tracker;
mapred.job.tracker=jt.hadoop.pvt:54311
hive> describe extended zz_mid_set;
OK
adv_spend_id int
transaction_id bigint
time string
client_id bigint
visit_info string
event_type tinyint
level int
location:hdfs://hdfs.hadoop.pvt:54310/user/hive/warehouse/zz_mid_set
Time taken: 0.063 seconds
hive> select count(1) from zz_mid_set;
1795928
在第2个集群上,使用CREATE TABLE语句创建相同的表,表的类型需要是外部表(EXTERNAL),这样即使在第2个集群上执行了删除表操作,也不会真实地删除第1个表中的数据。需要注意的是,这里我们需要指定完整的URL路径。事实上,当用户通过相对路径来指定表存储路径时,Hive实际会在元数据库中存储完整的URL路径:
hive> set fs.default.name;
fs.default.name=hdfs://rs01.hadoop.pvt:34310
hive> set mapred.job.tracker;
mapred.job.tracker=rjt.hadoop.pvt:34311
hive> CREATE TABLE EXTERNAL table_in_another_cluster
( adv_spend_id int, transaction_id bigint, time string, client_id bigint,
visit_info string, event_type tinyint, level int)
LOCATION 'hdfs://hdfs.hadoop.pvt:54310/user/hive/warehouse/zz_mid_set';
hive> select count(*) FROM table_in_another_cluster;
1795928
需要注意的是,之所以这样的跨集群操作可以工作,是因为两个集群的网络是相通的。我们所提交的任务所在的TaskTracker节点需要能够访问另一个集群的NameNode节点和所有的DataNode节点。Hadoop的设计理念中有一项就是转移计算而不转移数据,就是将计算尽量地转移到数据所在的位置。通过调度将计算任务转移到数据所在的节点上。在这种情况下,TaskTracker会连接另一个集群的DataNode。这就意味着会造成通用性能下降和网络占用增加。
2.不同集群间的Hive数据冗余
对于Hadoop和Hive而言保持数据冗余要比传统关系型数据库容易得多。和传统数据库在执行多事务时会频繁改变底层数据不同,Hadoop和Hive中的数据通常是“一次写入的”。增加新分区不会影响到已经存在的其他分区,而且通常来说,是按照时间日期来增加新分区的。
我们早期所使用的备份系统是一个独立的系统,也就是使用distcp命令进行操作,然后按照一定的时间间隔使用生成的Hive语句来增加分区。当我们想备份一张新表时,我们就会先拷贝来一份已有的代码,然后修改下这个脚本的配置来处理新的表和分区。经过一段时间,我们制定了一个可以更加自动化对表和分区进行备份的系统。
这个处理过程在创建分区的同时会创建一个空的HDFS文件,名为:
/replication/default.fracture_act/hit_date=20110304,mid=3000
备份进程会不断地扫描需要备份的目录结构。如果其发现一个新的文件,那么就会在Hive元数据库中查找其对应的表和分区,然后使用查找结果来备份这个分区。成功备份后这个文件就会被删除掉。
如下的代码片段就是这个程序的主循环处理部分。首先,我们会做一些检查来确保表是存在于目标元数据存储中:
public void run(){
while (goOn){
Path base = new Path(pathToConsume);
FileStatus [] children = srcFs.listStatus(base);
for (FileStatus child: children){
try {
openHiveService();
String db = child.getPath().getName().split("\\.")[0];
String hiveTable = child.getPath().getName().split("\\.")[1];
Table table = srcHive.client.get_table(db, hiveTable);
if (table == null){
throw new RuntimeException(db+" "+hiveTable+
" not found in source metastore");
}
Table tableR = destHive.client.get_table(db,hiveTable);
if (tableR == null){
throw new RuntimeException(db+" "+hiveTable+
" not found in dest metastore");
}
通过数据库名和表名我们就可以在元数据存储中找到其对应的存储路径信息。之后,我们会做一个检查来保证这个信息并非已经存在:
URI localTable = new URI(tableR.getSd().getLocation());
FileStatus [] partitions = srcFs.listStatus(child.getPath());
for (FileStatus partition : partitions){
try {
String replaced = partition.getPath().getName()
.replace(",", "/").replace("'","");
Partition p = srcHive.client.get_partition_by_name(
db, hiveTable, replaced);
URI partUri = new URI(p.getSd().getLocation());
String path = partUri.getPath();
DistCp distCp = new DistCp(destConf.conf);
String thdfile = "/tmp/replicator_distcp";
Path tmpPath = new Path(thdfile);
destFs.delete(tmpPath,true);
if (destFs.exists( new Path(localTable.getScheme()+
"://"+localTable.getHost()+":"+localTable.getPort()+
path) ) ){
throw new RuntimeException("Target path already exists "
+localTable.getScheme()+"://"+localTable.getHost()+
":"+localTable.getPort()+path );
}
Hadoop的DistCP并不适合通过编程的方式来运行。不过,我们可以传递一组字符串数据给其主函数。然后通过其返回值是否是0来判断是否成功执行:
String [] dargs = new String [4];
dargs[0]="-log";
dargs[1]=localTable.getScheme()+"://"+localTable.getHost()+":"+
localTable.getPort()+thdfile;
dargs[2]=p.getSd().getLocation();
dargs[3]=localTable.getScheme()+"://"+localTable.getHost()+":"+
localTable.getPort()+path;
int result =ToolRunner.run(distCp,dargs);
if (result != 0){
throw new RuntimeException("DistCP failed "+ dargs[2] +" "+dargs[3]);
}
最后,我们拼接好ALTER TABLE语句来增加分区:
String HQL = "ALTER TABLE "+hiveTable+
" ADD PARTITION ("+partition.getPath().getName()
+") LOCATION '"+path+"'";
destHive.client.execute("SET hive.support.concurrency =false");
destHive.client.execute("USE "+db);
destHive.client.execute(HQL);
String [] results=destHive.client.fetchAll();
srcFs.delete(partition.getPath(),true);
} catch (Exception ex){
ex.printStackTrace();
}
} // for each partition
} catch (Exception ex) {
//error(ex);
ex.printStackTrace();
}
} // for each table
closeHiveService();
Thread.sleep(60L*1000L);
} // end run loop
} // end run
23.2 Outbrain
——David Funk
Outbrain是领先的内容发现平台。
23.2.1 站内线上身份识别
有时,当用户想查看网站的流量情况时,很难弄清楚这些流量实际来源于哪里,特别是来源于用户网站之外的流量情况。如果用户的网站具有很多结构不同的URL的话,那么就无法简单地将所有的链接URL和用户登录页面进行匹配。
1.对URL进行清洗
我们期望达到的目的就是可以将链入的链接分成站内的、直接链入的或其他3个分组。如果所属组类型是其他的话,那么我们将仅仅保存原始的URL链接。这样,就可以将像对用户站点进行的Google搜索这样的链接从网站流量中区分出来,等等。如果链入的链接是空的或者值为null,那么我们将其标记为直接链入的那组。
从现在开始,我们将假定所有的URL网址都已经解析到主机名或域名了,而无论用户目标具体到什么级别的粒度。就我个人而言,我喜欢使用域,因为它更简单。据说,Hive只有一个主机名函数,但不是域名函数。
如果你只有原始URL,则有几个选项可供选择。通过HOST选项,正如下面例子所展示的,可以是个给出的链接中完整的主机名,如news.google.com或www.google.com,而其中的域名将缩短到最低的逻辑层次,像google.com或google.com.uk。
Host = PARSE_URL(my_url, ‘HOST’’)
也许用户正在使用一个UDF来处理这种情况。不管怎样,我并不在乎。重要的是我们要使用这些来进行匹配,所以用户需要根据自己的使用场景来做出最合适的选择。
2.Determining referrer type
因此,回到这个例子。比方说,我们有3个网站:mysite1.com、mysite2.com和mysite3.com。现在,我们可以把每个页面的URL转换成适当的类别。我们假设有一个表,表名为referrer_identification,其字段如下:
ri_page_url STRING
ri_referrer_url STRING
现在,我们可以很容易地通过如下查询来添加链接类型:
SELECT ri_page_url, ri_referrer_url,
CASE
WHEN ri_referrer_url is NULL or ri_referrer_url = ‘’ THEN ‘DIRECT’
WHEN ri_referrer_url is in (‘mysite1.com’,’mysite2.com’,’mysite3.com’) THEN ‘INSITE’
ELSE ri_referrer_url
END as ri_referrer_url_classed
FROM
referrer_identification;
3.Multiple URL
这都是非常简单的。但是如果我们使用的是一个广告网络呢?如果我们有成百上千的网站呢?如果每个站点可以有任意数量的URL结构呢?
如果是这样的话,我们可能也有一个包含每个URL的表,以及它属于什么类型的网站。让我们将这张表命名为site_url,其有如下2个字段:
su_site_id INT
su_url STRING
让我们为之前的那张表referrer_identification添加一个新的字段:
ri_site_id INT
现在我们开始讨论这个问题。我们要做的是通过每个链入网址,看它是否与任何相同的站点ID匹配。如果是匹配的话,那么这是一个站内链接,否则不是站内链接。所以,让我们通过如下查询进行确认:
SELECT
c.c_page_url as ri_page_url,
c.c_site_id as ri_site_id,
CASE
WHEN c.c_referrer_url is NULL or c.c_referrer_url = ‘’ THEN ‘DIRECT’
WHEN c.c_insite_referrer_flags > 0 THEN ‘INSITE’
ELSE c.c_referrer_url
END as ri_referrer_url_classed
FROM
(SELECT
a.a_page_url as c_page_url,
a.a_referrer_url as c_referrer_url,
a.a_site_id as c_site_id,
SUM(IF(b.b_url <> ‘’, 1, 0)) as c_insite_referrer_flags
FROM
(SELECT
ri_page_url as a_page_url,
ri_referrer_url as a_referrer_url,
ri_site_id as a_site_id
FROM
referrer_identification
) a
LEFT OUTER JOIN
(SELECT
su_site_id as b_site_id,
su_url as b_url
FROM
site_url
) b
ON
a.a_site_id = b.b_site_id and
a.a_referrer_url = b.b_url
) c
对于这个查询语句有几点需要说明。在本例中,我们使用的是外连接,因为我们希望有一些外部链入链接不与其匹配,这将让它们通过。因此,我们只会抓住确实匹配的条目,如果有任何这样的链接,我们知道它们来自网站内的某处。
23.2.2 计算复杂度
假设用户要计算用户网站、网络或其他什么东西的独立访客数量的话。我们将使用一个非常简单的假想表daily_users来表示:
du_user_id STRING
du_date STRING
不过,如果有非常多的用户而且集群中又没有足够的机器的话,那么在集群中计算一个月的用户数据都会变得非常困难:
SELECT
COUNT(DISTINCT du_user_id)
FROM
daily_users
WHERE
du_date >= ‘2012-03-01’ and
du_date <= ‘2012-03-31’
在所有的可能性中,如果用户集群没有太多问题,则可以使其通过map阶段,但是在reduce阶段就会出现问题。问题就是,它能够访问所有的记录,但却不能同时对其进行计数。当然,用户也不能每天都对其进行计算,因为这样做可能会有些多余。
1.为什么这是个问题
计数复杂度是O(n),其中n是记录的数量,但它有一个比较高的常数因子。我们可能会想出一些聪明的切割方式,来稍微降低一点计算复杂度,但更容易的方式就是减小n的值。虽然有一个高O(n)并不好,但大多数真正的问题出现在后面。如果用户处理某个问题需要运行的时间是n1.1 ,那么谁在乎如果n = 2还是n = 1呢。这样确实会较之前慢,但远远没有n=1和n=100之间的区别那么大。
所以,如果假设每天都有m条数目,而平均冗余是x的话,那么我们的第1个查询将是n=31*m条记录。我们通过创建一个用来保存每天重复版本的临时表将查询记录减少到n=31*(m-x)。
2.加载一个临时表
首先,创建临时表:
CREATE TABLE daily_users_deduped (dud_user_id STRING)
PARTITIONED BY (dud_date STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’;
然后我们写一个每天都可以执行一次的查询模板版本,然后使用它来更新我们的临时表。我一般将这些操作称为“metajobs”,所以我们可以称为mj_01.sql:
INSERT OVERWRITE TABLE daily_users_deduped
PARTITION (dud_date = ‘:date:’)
SELECT DISTINCT
du_user_id
FROM
daily_users
WHERE
du_date = ‘:date:’
接下来,我们写一个脚本,来替换组装这个文件,然后再在指定的日期范围内运行这个脚本。为此,我们需要涉及到3个函数,分别为:modify_temp_file函数,其用于替换一个变量;fire_query函数,其实质上就是对指定文件执行hive - f命令;最后一个函数是delete,用于删除文件。
start_date = ‘2012-03-01’
end_date = ‘2012-03-31’
for date in date_range(start_date, end_date):
femp_file = modify_temp_file(‘mj_01.sql’,{‘:date:’:my_date})
fire_query(temp_file)
delete(temp_file)
3.查询临时表
运行这个脚本,然后就可以得到一个n=31*(m-x)大小的表。现在,就无需一个大的reduce执行过程就可以查询这个表了。
SELECT
COUNT(DISTINCT (dud_uuid)
FROM
daily_users_deduped
如果这还不够的话,那么还可以按照日期来去重,也许可以每次两个日期,而不管时间间隔是多少。如果仍然有困难,那么还可以根据用户ID将记录散列到不同类,也许可以基于用户ID的第1个字符,进一步缩小n的值。
基本思路是,如果可以将n缩小的话,那么高O(n)也没有什么大不了的。
23.2.3 会话化
为了分析网络流量,我们常常希望能够基于各种各样的标准来测量热度。一种方法就是将用户行为分解到会话中,一次会话代表单一的一次“使用”所包含的一系列操作。一个用户在一天内或者一月中的某几天可以多次访问某个网站,但每一次访问肯定是不一样的。
那么,什么是一个会话呢?一种定义是指相隔不超过30分钟的一连串的活动就是一个会话。也就是说,如果你去你的第1个页面,等待5分钟,然后去第2个页面,那么这是相同的会话。等待30分钟后再到第3页,仍然是相同的会话。等待31分钟跳转到第4页,这次会话将被打破了,这将不是第4个访问页面了,而是第2个会话中的第1个页面。
一旦我们获得这些中断信息,我们就可以查看会话的属性信息,来看看发生了什么事而导致中断的。常规的方式就是通过会话长度来对链入的页面进行比较。所以,我们可能需要查清楚谷歌或Facebook是否给予这个网站更好的热点,这也许可以通过会话长度来进行测量。
乍一看,这似乎是一个完美的迭代过程。对于每个页面,保持倒计数,直到你找到第1个页面。但Hive是不支持迭代的。
不过,还是可以解决这个问题的。我想将这个处理过程分为4个阶段。
① 识别哪些页面浏览量是会话初始者,或“起源”页面。
② 对于每个页面,将其划分到正确的来源页面。
③ 将所有的页面浏览量聚合到每个来源页面。
④ 对每个来源页面进行标记,然后计算每个会话的热度。
这种方式将产生一个表,其中每一行都表示一个完整的会话,然后用户就可以查询任何想知道的信息了。
1.设置
首先定义表session_test的字段如下:
st_user_id STRING
st_pageview_id STRING
st_page_url STRING
st_referrer_url STRING
st_timestamp DOUBLE
这些内容都很简单,不过我需要提一下st_pageview_id表示的每个事物(在这种情况下就是一个页面)的唯一ID。否则,多次查看完全相同的页面可能会令人比较困惑。本示例中,时间戳以秒为单位。
2.找到来源页面浏览量
好的,下面让我们开始第一步(令人震惊吧!)。首先看看我们是如何找到这页面浏览会话的起始页面的。好吧,如果我们假定任何超过30分钟的停留就意味着一个新会话的话,那么任意的会话起始页都不可能停留超过30分钟或更少的时间。这是一个典型的案例总结条件。我们要做的就是,计算每个访问页面的次数。然后,任何计数为零的页面就一定是一个起始页面。
为了能做到这一点,我们需要比较所有可能在这个页面之前的页面。这是一个代价非常大的操作,因为它需要执行一个笛卡尔交叉乘积。为了防止数据膨胀到不可收拾的大小,我们应该使用尽可能多的约束条件来限制数据量。在当前情况下,限制条件只有用户ID,但是如果用户有一个包含众多独立站点的大型网络的话,那么还可以按照每个源进行分组:
CREATE TABLE sessionization_step_one_origins AS
SELECT
c.c_user_id as ssoo_user_id,
c.c_pageview_id as ssoo_pageview_id,
c.c_timestamp as ssoo_timestamp
FROM
(SELECT
a.a_user_id as c_user_id,
a.a_pageview_id as c_pageview_id,
a.a_timestamp as c.c_timestamp,
SUM(IF(a.a_timestamp + 1800 >= b.b_timestamp AND
a.a_timestamp < b.b_timestamp,1,0)) AS c_nonorigin_flags
FROM
(SELECT
st_user_id as a_user_id,
st_pageview_id as a_pageview_id,
st_timestamp as a_timestamp
FROM
session_test
) a
JOIN
(SELECT
st_user_id as b_user_id,
st_timestamp as b_timestamp
FROM
session_test
) b
ON
a.a_user_id = b.b_user_id
GROUP BY
a.a_user_id,
a.a_pageview_id,
a.a_timestamp
) c
WHERE
c.c_nonorigin_flags
这个SQL可能有点长。不过其中重要的部分是计算是否是起始页码的计数器,也就是我们定义的define c_nonorigin_flags。基本上,计算过程如下行所示:
SUM(IF(a.a_timestamp + 1800 >= b.b_timestamp AND
a.a_timestamp < b.b_timestamp,1,0)) as c_nonorigin_flags
我们将其进行分解,一部分一部分进行介绍。首先,从子查询a开始。我们使用别名b表示那些候选数据。因此,第一部分,其中的a.a_timestamp+1800 >=b.b_timestamp,表示候选数据时间戳不能比限定的时间戳早30分钟;第二部分,a.a_timestamp < b.b_timestamp这段SQL片段表示候选时间戳比限定时间戳值要大,这是一个检查过程,如果不通过则返回FALSE。同时,因为这是个交叉运算,因为不能使用候选时间戳作为自己的限定时间戳,否则返回FALSE。
现在,产生表sessionization_step_one_origins,其字段信息如下:
ssoo_user_id STRING
ssoo_pageview_id STRING
ssoo_timestamp DOUBLE
3.将PV分桶到起始页面中
开始第2步的一个好的理由就是,我们需要找到某个页面所属的起始页面。做法很简单,每个页面的起始页面必定是其之前的最近的页面。为此,我们进行另外一个大的表连接操作来检查页面时间戳和所有潜在的起始页面间的最小差值:
CREATE TABLE sessionization_step_two_origin_identification AS
SELECT
c.c_user_id as sstoi_user_id,
c.c_pageview_id as sstoi_pageview_id,
d.d_pageview_id as sstoi_origin_pageview_id
FROM
(SELECT
a.a_user_id as c_user_id,
a.a_pageview_id as c_pageview_id,
MAX(IF(a.a_timestamp >= b.b_timestamp, b.b_timestamp, NULL)) as c_origin_timestamp
FROM
(SELECT
st_user_id as a_user_id,
st_pageview_id as a_pageview_id,
st_timestamp as a_timestamp
FROM
session_test
) a
JOIN
(SELECT
ssoo_user_id as b_user_id,
ssoo_timestamp as b_timestamp
FROM
sessionization_step_one_origins
) b
ON
a.a_user_id = b.b_user_id
GROUP BY
a.a_user_id,
a.a_pageview_id
) c
JOIN
(SELECT
ssoo_usr_id as d_user_id,
ssoo_pageview_id as d_pageview_id,
ssoo_timestamp as d_timestamp
FROM
sessionization_step_one_origins
) d
ON
c.c_user_id = d.d_user_id and
c.c_origin_timestamp = d.d_timestamp
这里还有很多内容要讲。首先,让我们看看如下这行语句:
MAX(IF(a.a_timestamp >= b.b_timestamp, b.b_timestamp, NULL)) as c_origin_timestamp
我们再次使用约束值和候选值的思路进行计算。在这种情况下,b是每一个约束值a的候选值。一个起始候选值是不会比页面访问的时间晚的,所以对于这类情况,我们期望找到符合标准的最新起始页。其中null值是无关紧要的,因为我们要保证获取一个最低值,总是有至少一个可能的起始页面的(即使是这个页面本身)。这不会得到我们期望的起始页面,但是可以给我们时间戳,这样我们就可以根据时间戳来判断是否是起始页面。
在这里,我们仅仅是将这个时间戳与所有其他潜在的起始页面时间戳进行匹配,然后我们就可以知道哪些页面属于哪些起始页面。最终产生表sessionization_step_two_origin_identification,其字段信息如下:
sstoi_user_id STRING
sstoi_pageview_id STRING
sstoi_origin_pageview_id STRING
值得一提的是,这不是识别起始页面的唯一方法。用户可以基于引入,标记出所有外部链接、主页URL或空白链入页面(表示是直接流量)作为一个起始会话。用户还可以基于动作,只测量鼠标点击后的动作。还是有很多选择方案的,但最重要的是确定什么样的会话是起始会话。
4.对起始页面进行聚合
对于这一点,处理起来非常容易。第3步,我们将会对起始页面进行聚合,这个过程真的,真的简单。对于每个起始页面,计算其对应的页面浏览量:
CREATE TABLE sessionization_step_three_origin_aggregation AS
SELECT
a.a_user_id as sstoa_user_id,
a.a_origin_pageview_id as sstoa_origin_pageview_id,
COUNT(1) as sstoa_pageview_count
FROM
(SELECT
ssoo_user_id as a_user_id
ssoo_pageview_id as a_origin_pageview_id
FROM
sessionization_step_one_origins
) a
JOIN
(SELECT
sstoi_user_id as b_user_id,
sstoi_origin_pageview_id as b_origin_pageview_id
FROM
sessionization_step_two_origin_identification
) b
ON
a.a_user_id = b.b_user_id and
a.a_origin_pageview_id = b.b_origin_pageview_id
GROUP BY
a.a_user_id,
a.a_origin_pageview_id
5.按照起始页面类型进行聚合
现在是最后一步了,我们可以不必保留页面的所有的属性信息,尤其对于在前面的处理步骤之一的起始页面来说。然而,如果用户需要注意很多细节的话,那么在最后的处理阶段也是可以很容易将需要的信息添加进来的。下面是第4步:
CREATE TABLE sessionization_step_four_qualitative_labeling
SELECT
a.a_user_id as ssfql_user_id,
a.a_origin_pageview_id as ssfql_origin_pageview_id,
b.b_timestamp as ssfql_timestamp,
b.b_page_url as ssfql_page_url,
b.b_referrer_url as ssfql_referrer_url,
a.a_pageview_count as ssqfl_pageview_count
(SELECT
sstoa_user_id as a_user_id,
sstoa_origin_pageview_id as a_origin_pageview_id,
sstoa_pageview_count as a_pageview_count
FROM
sessionization_step_three_origin_aggregation
) a
JOIN
(SELECT
st_user_id as b_user_id,
st_pageview_id as b_pageview_id,
st_page_url as b_page_url,
st_referrer_url as b_referrer_url,
st_timestamp as b_timestamp
FROM
session_test
) b
ON
a.a_user_id = b.b_user_id and
a.a_origin_pageview_id = b.b_pageview_id
6.衡量热度
现在,使用我们的最终表,我们可以做任何我们想要做的事情。假设我们想知道会话数量、平均每个会话页面浏览量、每次会话的加权平均综合浏览量以及最大或最小浏览量。那么我们可以选择任何我们想要的标准,或根本没有任何标准。但是在这种情况下,我们通过链接URL能找到答案,其流量来源具有最好的热度。只是为了好玩,让我们也看看谁给了我们最独特的用户:
SELECT
PARSE_URL(ssfql_referrer_url, ‘HOST’) as referrer_host,
COUNT(1) as session_count,
AVG(ssfql_pageview_count) as avg_pvs_per_session,
SUM(ssfq_pageview_count)/COUNT(1) as weighted_avg_pvs_per_session,
MAX(ssfql_pageview_count) as max_pvs_per_session,
MIN(ssfql_pageview_count) as min_pvs_per_session,
COUNT(DISTINCT ssfql_usr_id) as unique_users
FROM
sessionization_step_three_origin_aggregation
GROUP BY
PARSE_URL(ssfql_referrer_url, ‘HOST’) as referrer_host
然后我们就可以得到结果了。我们可以查看到哪个URL页面热度最大,以及确定忠实用户是哪些,等等。一旦我们拥有一个包含有这一切信息的临时表,尤其是具有一个更完整的定性属性信息的表,我们就可以回答各种各样的用户热度问题。
23.3 NASA喷气推进实验室
23.3.1 区域气候模型评价系统
——Chris A. Mattmann、Paul Zimdars、Cameron Goodale、Andrew F. Hart、
Jinwon Kim、Duane Waliser、Peter Lean共同编写
自2009年以来,我们在美国宇航局(NASA)喷气推进实验室(JPL)的团队就已经积极发展引出了一个区域气候模型评价系统(RCMES)。这个系统起先是在美国复苏和再投资法案(ARRA)资助下展开的,此系统有以下几个目标。
① 便于评价和分析区域气候模式模拟输出,其可以通过对质量受控的参考数据集的可用性的观察和对各种传感器的分析理解进行评价和分析。 这是一个有效的数据库结构,是一组用于计算度量模型评价指标和诊断的计算工具集合,而且其具有可伸缩的和友好的用户界面。
② 方便汇集大量的复杂和异构软件工具和数据访问的功能,用于展示、重组、重新格式化和可视化,这样便于将如偏差图这样的最终产品很容易地传递给最终用户。
③ 支持区域气候变化的评估,并进行影响分析,而且还需要通知决策者(如地方政府、农业部门、国家政府、水文学家等),这样他们可以做出对于大金融和社会具有重大影响的重要的决策。
④ 可以克服数据格式和元数据的异构性的问题(例如NetCDF3/4,CF元数据规范,HDF4/5,HDF-EOS元数据规范)。
⑤ 处理时空差异(如将数据进行180/80的经纬度分析,例如数据可以是一个360/360度的经纬度网格),并确保可能最初是日数据的数据,是可以和月数据进行对比的。
⑥ 支持弹性扩展,在进行区域研究时,需要特别的遥感数据和气候模型输出数据,并需要进行一系列的分析,然后就会摧毁特定的系统实例。换句话说,支持瞬态分析以及快速构建/解构RCMES实例。图23-2显示了区域气候模型评价系统的体系结构和数据流。
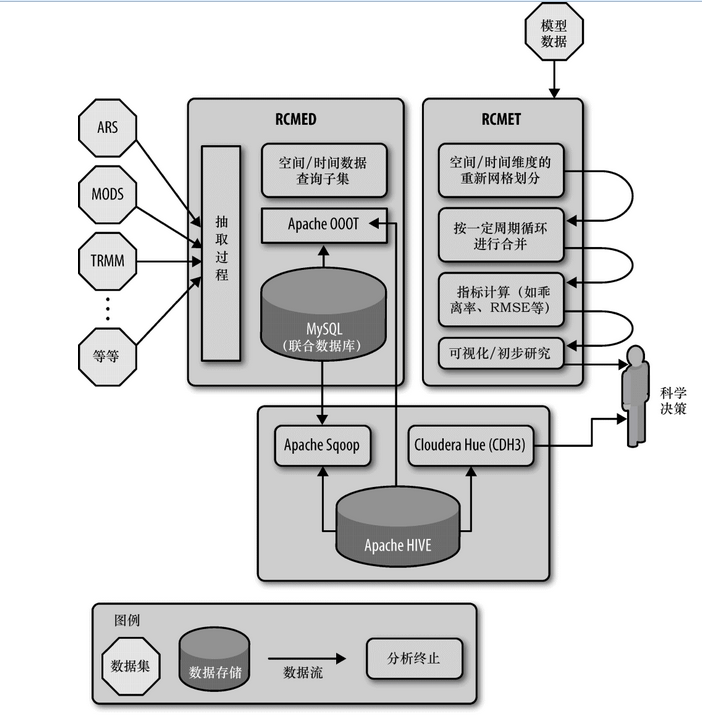
图23-2 JPL架构图
为实现这些目标,我们已经构建了一个多层面的系统,如图23-2所示。从左到右看下这个图,从观测采集的可用的参考数据集,特别是从卫星遥感采集的数据集,根据用于评价的气候模型所需的气候参数进入到系统。这些参数都存储在各种任务的数据集中,这些数据集被安置在一些外部存储库中,最终送入到RCMES系统的数据库组件(RCMED:区域气候模型评价数据库)中。
举一个例子,AIRS是NASA的大气红外探测器,其可以提供很多参数,包括表面空气温度、温度和重力势;MODIS是NASA的热感成像光谱仪,其可以的提供参数包括云分数;而TRMM是NASA的热带降雨测量任务,其提供参数包括每月的降雨量。这些信息是在我们RCMES系统网站上都进行了总结,网址是http://rcmes.jpl.nasa.gov/rcmed/param,如图23-3所示。
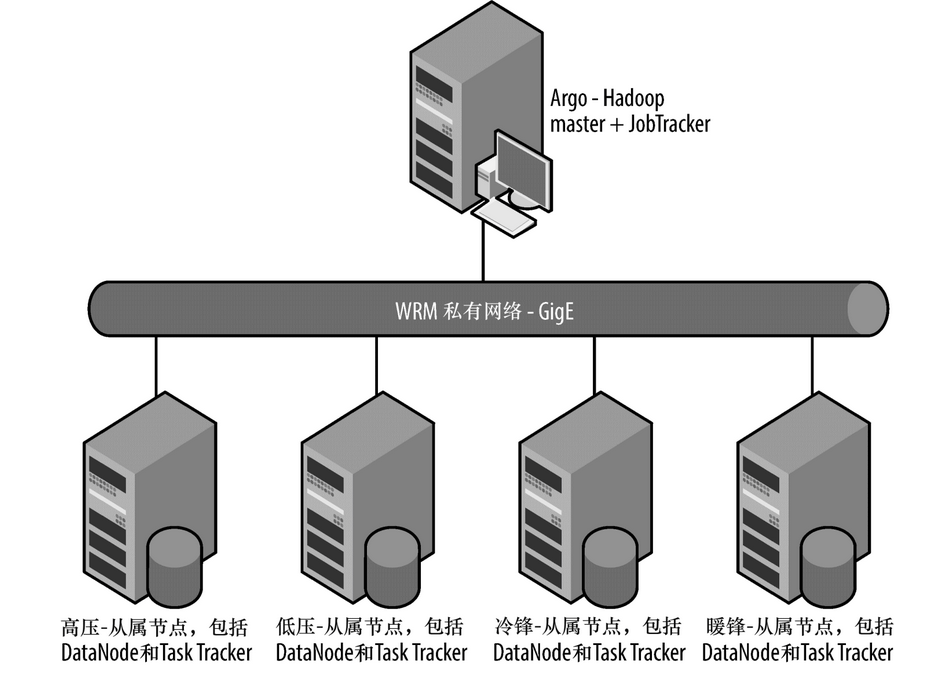
图23-3 JPL物理架构图
数据集是使用Apache OODT抽取器框架加载到RCMED中的,其所需的参数,以及参数值、空间和时间约束(以及可选的高度约束)都被装载进去了,而且还可以进行潜在的更改(如规范化,使用相同的坐标系统,从不同单位值进行换算),最终装载到一个MySQL数据库中。加载到MySQL数据库中的数据、RCMED,通过空间/时间查询和构造子集web服务公开给外部客户,具体内容就是另一个话题了。对于所有的意图和目的,其提供了和OPeNDAP同样的功能。
右边的图显示的是区域气候模型评估工具包(RCMET)。其为用户提供了能够从RCMED和在其他地方产生的气候模型输出数据进行引用的能力,并可以重组这些数据,用于在时间和空间上进行匹配,并将模型数据评估的模型输出与用户选择的参考数据进行比较参考。此时,系统允许按照季节性周期合成(例如,N年的所有一月份,或所有夏季),并为最终指标计算准备数据,也就是说,比较了模型输出值与遥感数据观测参数及其值。系统支持多种指标,如偏差计算、均方根误差(RMSE),并生成相关的可视化图形,包括传统的饼图和为科学使用/决策支持的泰勒图。
23.3.2 我们的经验:为什么使用Hive
那么,在哪里使用Hive呢?在载入了60亿行(经度、维度、时间、数据值、高度)数据集到MySQL后,系统崩溃了,并经历过数据丢失。这可能部分是因为我们最初的策略是将所有的数据都存储到单一的一张表中了。后来,我们调整了策略通过数据集和参数进行分表,这有所帮助但也因此引入了额外的消耗,而这并非是我们愿意接受的。
相反,我们决定尝试使用Apache Hive技术。我们安装了Hive 0.5 + 20,使用CDHv3和Apache Hadoop(0 20 2 + 320)。CDHv3还包含有许多其他相关工具,包括Sqoop和Hue这些在我们的架构中都标识出来了,如图23-3底部所示。
我们使用Apache Sqoop转储数据到Hive中,然后通过写一个Apache OODT包装器,来使Hive按照空间/时间约束查询数据,然后将结果提供给RCMET和其他用户(图23-2中间部分显示)。RCMES集群的完整的架构如图23-3所示。我们有5台机器,包括图中所示的一个主/从配置,通过一个运行GigE的私人网进行连接。
23.3.3 解决这些问题我们所面临的挑战
在将数据从MySQL迁移到Hive的过程中,我们经历了在做一些简单的任务时,响应时间缓慢的问题,例如一个简单的计数DB查询(例如:hive> select count(datapoint_id) from dataPoint;)。初始化时,我们向单个表中载入了25亿条数据,并在机器配置信息中记录下来,Hive对这25亿条记录执行计数查询用了大约5~6分钟, (查询完整的68亿条记录大约需要15~17分钟)。Reduce过程也比较快(因为我们使用的是一个对于*的count操作,所以我们会经历一个reduce阶段),但是map阶段需要消耗大部分的时间(大于占总执行时间的95%)。那个时候我们的系统由6个系统(4 x四核)组成,每台系统大约有24 GB的RAM (所有的机器如图23-3所示,再加上一个从另一个集群借来的同类型的机器)。
我们试图添加更多的节点,增加map tasktrackers(许多不同的#s),改变DFS块大小(32MB、64MB、128 MB、256MB),利用LZO压缩,并改变许多其他配置变量(例如io、sort.factor、io.sort.mb),都没有有效地降低完成全局计数所需要的时间。但我们却发现一直存在一个高I / O等待节点,而无论我们执行多少任务。数据库的大小大约是200GB,而使用MySQL对25亿和67亿行数据执行计数只需要花几秒钟时间。
Hive社区成员加入到了我们公司,为我们提供了新的视角,期间HDFS读取速度提高到大约60 MB / 秒,对比本地磁盘读取速度是1 GB /秒,这当然还取决于网络速度和namenode的负荷情况。社区成员提出的建议是,我们在Hadoop任务中大约需要16个Mapper才能和一个本地非Hadoop任务的I / O性能相当。此外,Hive社区成员建议我们通过减少每个Mapper处理的分割大小(输入大小)来增加总体Mapper的数量 (也就是增加并发量),并指出我们应该检查以下参数: mapred.min.split.size、mapred.max.split.size、mapred.min.split.size.per.rack和mapred.min.split.size.per.node,并建议这些参数值应设置为64 MB。最后,社区建议我们查看一个基准计算过程,也就是通过使用count(1)而不是count (datapoint_id)来计算行数,因为没有列引用意味着没有序列化和反序列化的过程,所以因为前者更快,例如,如果用户的表是RCFile格式存储的。(译者注:原文是后者更快,实际上后者是需要序列化和反序列化过程的。)
基于上述反馈,我们可以为RCMES的Hive集群基于一个计数基准查询进行调优,并在规定的响应时间内返回一个计数查询,最终利用上述资源,可以在15秒内从RCMET中对数十亿行数据进行空间/时间查询,这使Hive对于我们的系统架构而言,成为一个可行的和绝佳的选择。
我们已经描述了在JPL RCMES系统中使用Apache Hive的情况。我们在一个案例研究中描述了我们想要通过Hive探索云计算技术并替代MySQL,并从配置需求上使它的规模水平可以存储数百亿行数据,并有弹性地摧毁和重建存储于其中的数据。
Hive很好地满足了我们的系统需求,而我们正积极寻找更多的方法将其集成到RCMES系统中。
23.4 Photobucket
Photobucket是当前因特网上最大的专业网上相簿服务公司。其在2003年由Alex Welch 和 Darren Crystal创立,随后Photobucket很快成为互联网上最流行的网站之一,并吸引了超过一亿名用户和数十亿的存储和共享媒体。用户和系统数据分布在成百上千个MySQL实例上、成千上万个Web服务器上和PB级别的文件系统上。
23.4.1 Photobucket 公司的大数据应用情况
在2008年之前,Photobucket还没有专门的内部分析系统。业务用户提出的问题横跨数百台MySQL实例并最终在Excel中手动聚合。
在2008年,Photobucket首次开始着手实施数据仓库建设,致力于解决由一个快速增长的公司所带来的日益复杂的数据处理问题。
第一次迭代的数据仓库是一个开源的系统,包括一个Java SQL优化器和一组底层的PostGreSQL数据库。这个系统直到2009年都工作完好,但是其架构上的缺陷很快明显凸现。工作数据集迅速变得比实际可提供的内存大,再加上在PostgreSQL节点上重新对数据进行划分非常之困难,导致我们不得不对集群进行扩大。
在2009年,我们开始调查系统,使我们能够随着数据量的不断增长不断地向外扩展,使之仍然能够满足我们与业务用户签订的服务等级协议(SLA)。Hadoop迅速成为消费和分析每日由系统生成的TB级别的数据最受欢迎的工具,但是阻碍全面使用的一个负面因素就是对于简单的ad-hoc查询都要编写复杂的MapReduce程序。值得庆幸的是,Facebook几周后开源的Hive很好地破解了这个ad-hoc查询复杂的问题。
Hive相对于以前的数据仓库实现具有很多优势。
关于为什么我们选择Hadoop和Hive,这里列举了几个例子。
① 能够处理结构化和非结构化数据。
② 从Flume、Scribe或MountableHDFS中实时导数据到HDFS中。
③ 可以通过UDF进行功能扩展,。
④ 一个专门为构建OLAP与OLTP的文档充分的、类SQL的接口。
23.4.2 Hive所使用的硬件资源信息
对于数据节点使用Dell R410,4×2TB硬盘,24GB RAM; 对于管理节点使用Dell R610,2×146GB(RAID 10)硬盘和24GB RAM。
23.4.3 Hive提供了什么
Photobucket公司使用Hive的主要目标是为业务功能、系统性能和用户行为提供答案。为了满足这些需求,我们每晚都要通过Flume从数百台服务器上的MySQL数据库中转储来自Web服务器和自定义格式日志TB级别的数据。这些数据有助于支持整个公司许多组织,比如行政管理、广告、客户支持、产品开发和操作,等等。对于历史数据,我们保持所有MySQL在每月的第一天创建的所有的数据作为分区数据并保留30天以上的日志文件。Photobucket使用一个定制的ETL框架来将MySQL数据库中数据迁移到Hive中。使用Flume将日志文件数据写入到HDFS中并按照预定的Hive流程进行处理。
23.4.4 Hive支持的用户有哪些
行政管理依赖于使用Hadoop提供一般业务健康状况的报告。Hive允许我们解析结构化数据库数据和非结构化的点击流数据,以及业务所涉及的数据格式进行读取。
广告业务使用Hive筛选历史数据来对广告目标进行预测和定义配额。产品开发无疑是该组织中产生最大数量的特定的查询的用户了。对于任何用户群,时间间隔变化或随时间而变化。Hive是很重要的,因为它允许我们通过对在当前和历史数据中运行A / B测试来判断在一个快速变化的用户环境中新产品的相关特性。
在Photobucket公司中,为我们的用户提供一流的系统是最重要的目标。从操作的角度来看,Hive被用来汇总生成跨多个维度的数据。在公司里知道最流行的媒体、用户、参考域是非常重要的。控制费用对于任何组织都是重要的。一个用户可以快速消耗大量的系统资源,并显著增加每月的支出。Hive可以用于识别和分析出这样的恶意用户,以确定哪些是符合我们的服务条款,而哪些是不符合的。也可以使用Hive对一些操作运行A / B测试来定义新的硬件需求和生成ROI计算。Hive将用户从底层MapReduce代码解放出来的能力意味着可以在几个小时或几天内就可以获得答案,而不是之前的数周。
23.5 SimpleReach
——Eric Lubow
在SimpleReach中,我们使用Cassandra来存储我们所有的社交网络产生的原始数据。行的键的格式是一个账号ID(其也是MongoDB的ObjectId)和一个内容元素ID(被跟踪的内容元素的URL链接的MD5哈希值),这两者间使用下划线进行分割,结果集中的数据也是按照这个分隔符进行划分的。这行中的列是类似于如下展示的混合在一起的一组列:
4e87f81ca782f3404200000a_8c825814de0ac34bb9103e2193a5b824
=> (column=meta:published-at, value=1330979750000, timestamp= 1338919372934628)
=> (column=hour:1338876000000_digg-diggs, value=84, timestamp= 1338879756209142)
=> (column=hour:1338865200000_googleplus-total, value=12, timestamp= 1338869007737888)
为了能够访问这些组合列,我们需要知道列名对应的十六进制键的值。在我们的例子中,也就是我们需要执行列名(meta:'published-at')的十六进制的键值。这个十六进制键和值的形式如下:
00046D65746100000C7075626C69736865642D617400 =meta:published-at
一旦将列名转换成十六进制格式,Hive查询就可以对之进行处理了。查询语句的第一部分是LEFT SEMI JOIN,其用于模拟一个子查询SQL。后面所有的使用SUBSTR和INSTR的引用都是来处理不同情况的组合列的。因为我们已经知道“hour:*”列(例如,SUBSTR(r.column_name,10,13))的第10~第23个字符是时间戳,所以我们可以将其截取出来并作为返回值返回,或者用作其他对比。INSTR用于对比列名并保证返回的结果集在输出中总是位于相同位置的相同列。作为Ruby函数的一部分的SUBSTR也用于对比。SUBSTR返回值是一个以毫秒表示的时间戳(long型的),start_date和end_date同样是这样的以毫秒表示的时间戳。这意味着传入的值可以作为列名的一部分进行匹配。
这个查询的目的是将数据从Cassandra中导出成CVS文件,最终为我们的出版商提供聚合后的数据。其是通过我们Rails栈中的一个离线处理任务完成的。具有一个完整的CSV文件意味着Hive查询中必须要包含有所有的使用到的列的列名(这意味着我们需要在没有数据的地方补上数据)。我们可以通过使用CASE语句将我们的宽行转换成固定列的表。
如下是处理CSV文件的HiveQL语句:
SELECT CAST(SUBSTR(r.column_name, 10, 13) AS BIGINT) AS epoch,
SPLIT(r.row_key, '_')[0] AS account_id,
SPLIT(r.row_key, '_')[1] AS id,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'pageviews-total') > 0
THEN r.value ELSE '0' END AS INT)) AS pageviews,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'digg-digg') > 0
THEN r.value ELSE '0' END AS INT)) AS digg,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'digg-referrer') > 0
THEN r.value ELSE '0' END AS INT)) AS digg_ref,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'delicious-total') > 0
THEN r.value ELSE '0' END AS INT)) AS delicious,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'delicious-referrer') > 0
THEN r.value ELSE '0' END AS INT)) AS delicious_ref,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'googleplus-total') > 0
THEN r.value ELSE '0' END AS INT)) AS google_plus,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'googleplus-referrer') > 0
THEN r.value ELSE '0' END AS INT)) AS google_plus_ref,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'facebook-total') > 0
THEN r.value ELSE '0' END AS INT)) AS fb_total,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'facebook-referrer') > 0
THEN r.value ELSE '0' END AS INT)) AS fb_ref,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'twitter-tweet') > 0
THEN r.value ELSE '0' END AS INT)) AS tweets,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'twitter-referrer') > 0
THEN r.value ELSE '0' END AS INT)) AS twitter_ref,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'linkedin-share') > 0
THEN r.value ELSE '0' END AS INT)) AS linkedin,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'linkedin-referrer') > 0
THEN r.value ELSE '0' END AS INT)) AS linkedin_ref,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'stumbleupon-total') > 0
THEN r.value ELSE '0' END AS INT)) AS stumble_total,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'stumbleupon-referrer') > 0
THEN r.value ELSE '0' END AS INT)) AS stumble_ref,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'social-actions') > 0
THEN r.value ELSE '0' END AS INT)) AS social_actions,
SUM(CAST(CASE WHEN INSTR(r.column_name, 'referrer-social') > 0
THEN r.value ELSE '0' END AS INT)) AS social_ref,
MAX(CAST(CASE WHEN INSTR(r.column_name, 'score-realtime') > 0
THEN r.value ELSE '0.0' END AS DOUBLE)) AS score_rt
FROM content_social_delta r
LEFT SEMI JOIN (SELECT row_key
FROM content
WHERE HEX(column_name) = '00046D65746100000C7075626C69736865642D617400'
AND CAST(value AS BIGINT) >= #{start_date}
AND CAST(value AS BIGINT) <= #{end_date}
) c ON c.row_key = SPLIT(r.row_key, '_')[1]
WHERE INSTR(r.column_name, 'hour') > 0
AND CAST(SUBSTR(r.column_name, 10, 13) AS BIGINT) >= #{start_date}
AND CAST(SUBSTR(r.column_name, 10, 13) AS BIGINT) <= #{end_date}
GROUP BY CAST(SUBSTR(r.column_name, 10, 13) AS BIGINT),
SPLIT(r.row_key, '_')[0],
SPLIT(r.row_key, '_')[1]
这个查询的输出是以逗号分隔的文件(CSV文件),内容如下面例子所示(为清晰展示对输出中一些行进行了转行并增加了空行进行分隔):
epoch,account_id,id,pageviews,digg,digg_ref,delicious,delicious_ref,
google_plus,google_plus_ref,fb_total,fb_ref,tweets,twitter_ref,
linkedin,linkedin_ref,stumble_total,stumble_ref,social_actions,social_ref,score_rt
1337212800000,4eb331eea782f32acc000002,eaff81bd10a527f589f45c186662230e,
39,0,0,0,0,0,0,0,2,0,20,0,0,0,0,0,22,0
1337212800000,4f63ae61a782f327ce000007,940fd3e9d794b80012d3c7913b837dff,
101,0,0,0,0,0,0,44,63,11,16,0,0,0,0,55,79,69.64308064
1337212800000,4f6baedda782f325f4000010,e70f7d432ad252be439bc9cf1925ad7c,
260,0,0,0,0,0,0,8,25,15,34,0,0,0,0,23,59,57.23718477
1337216400000,4eb331eea782f32acc000002,eaff81bd10a527f589f45c186662230e,
280,0,0,0,0,0,0,37,162,23,15,0,0,0,2,56,179,72.45877173
1337216400000,4ebd76f7a782f30c9b000014,fb8935034e7d365e88dd5be1ed44b6dd,
11,0,0,0,0,0,0,0,1,1,4,0,0,0,0,0,5,29.74849901
23.6 Experiences and Needs from the Customer Trenches
标题:来自Karmasphere的视角
——Nanda Vijaydev
23.6.1 介绍
在超过18个月的时间里,Karmasphere一直忙于越来越多的使用Hadoop的公司,这些公司都转向使用Hive作为分析师团队和业务团队提供服务的最优方式。本章的第一部分说明了我们在客户环境中不断反复使用Hive进行分析的一些实际场景的使用技术。
我们所涵盖的使用场景例子如下。
① 为Hive提供最优数据格式化类型。
② 分区和性能。
③ 使用Hive函数(包括正则、Explode函数和连词)进行文本分析。
随着我们一直合作的公司计划并生产中使用Hive,他们一直在寻找一些增强功能, 使基于Hive获取Hadoop更容易使用、更富有成效、更强大,而且可以让他们的组织中更多的人进行使用。
当他们将Hadoop和Hive加入到他们现有的数据架构中后,他们还想让从Hive查询的结果系统化、可以进行共享并可以集成到其他数据存储、电子表格、BI工具和报告系统中。
特别地,这些公司有如下要求。
① 获取数据,检测原始格式,并创建元数据的便捷方法。
② 在一个集成的、多用户环境下协同工作。
③ 探索和迭代分析数据。
④ 可保存和重用路径。
⑤ 对数据、表和列的安全的细粒度控制,并区分访问不同的业务线数据。
⑥ 业务用户不需要SQL技能就可访问并进行分析。
⑦ 调度查询,并将生成的结果自动导出到非Hadoop的数据存储中。
⑧ 与Microsoft Excel、Tableau、Spotfire以及其他电子表格、报告系统、仪表板、BI工具进行集成。
⑨ 可以管理基于Hive的功能,包括进行查询、结果输出、可视化以及Hive的标准组件,如UDF和SerDe。
23.6.2 Customer Trenches的用例
1.Customer trenches #1: 为Hive优化存储格式
许多Hive用户反复反馈的一个问题就是Hive中的数据使用什么存储格式进行存储以及如何使用这些数据。
Hive本身内置可以支持许多种数据格式,但有一些自定义的专有格式就不支持了。有一些数据格式支持为用户解决如何从一个行数据中提取出独立的部份。有时候,写一个标准的HiveSerDe来支持一个自定义的数据格式是最优方法。而在其他情况下,使用现有的Hive分隔符和Hive UDF可能是最方便的解决方案。我们合作地使用Hadoop来提供个性化服务,并使用Hive对多个输入数据流进行分析。公司的一个有代表性的案例就是:他们收到的是来自他们的一个日志数据提供者的格式,而这种格式不能轻易地分裂成列。他们试图想出一个办法使得无需编写一个自定义SerDe就可以解析数据并运行查询。
数据包含顶层的头信息和底层的多个详细信息。详细信息部分是一个嵌套在顶级对象中的JSON对象,类似于如下这样的数据集:
{ "top" : [
{"table":"user",
"data":{
"name":"John Doe","userid":"2036586","age":"74","code":"297994", "status":1}},
{"table":"user",
"data":{
"name":"Mary Ann","userid":"14294734","age":"64","code":"142798", "status":1}},
{"table":"user",
"data":{
"name":"Carl Smith","userid":"13998600","age":"36","code":"32866", "status":1}},
{"table":"user",
"data":{
"name":"Anil Kumar":"2614012","age":"69","code":"208672", "status":1}},
{"table":"user",
"data":{
"name":"Kim Lee","userid":"10471190","age":"53","code":"79365", "status":1}}
]}
与客户交谈后,我们意识到他们感兴趣的是上面的示例中“data”标签下的详细字段信息。
为帮助他们解决这个问题,我们使用Hive中自带的函数get_json_object,使用方法如下。
第一步是创建一个表,其使用的是样本数据:
CREATE TABLE user (line string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION ‘hdfs://hostname/user/uname/tablefolder/’
然后使用Hive等功能得到JSON对象,我们可以得到的嵌套JSON元素并使用UDF对其进行解析:
SELECT get_json_object(col0, '$.name') as name, get_json_object(col0, '$.userid') as uid,
get_json_object(col0, '$.age') as age, get_json_object(col0, '$.code') as code,
get_json_object(col0, '$.status') as status
FROM
(SELECT get_json_object(user.line, '$.data') as col0
FROM user
WHERE get_json_object(user.line, '$.data') is not null) temp;
查询详细信息如下。
a.在内部查询中提取以‘data’作为标识嵌套的JSON对象,并将其取别名为col0。
b.然后将JSON对象分成适当的列并使用它们的标记名作为对应的列别名。
查询结果如下,这是一个CSV文件,其中第一行是字段名称:
"name","uid","age","code","status"
"John Doe","2036586","74","297994","1"
"Mary Ann","14294734","64","142798","1"
"Carl Smith","13998600","36","32866","1"
"Kim Lee","10471190","53","79365","1"
2.Customer trenches #2: 分区和性能
使用分区来保存通过数据流或定期添加到Hadoop的数据是一个最近我们看到多次的用例,而这是一个利用Hadoop和Hive来分析各种快速添加进来的数据集强大而非常有价值的方式。Web、应用、产品和传感器日志这些数据,只是Hive用户经常需要ad-hoc、重复执行和预定查询的数据。
Hive分区在正确设置后,可以允许用户查询仅在特定的分区下的数据,从而将极大地提高性能。当为表建立分区时,文件应该位于类似如下例子中给出的目录下:
hdfs://user/uname/folder/"yr"=2012/"mon"=01/"day"=01/file1, file2, file3
/"yr"=2012/"mon"=01/"day"=02/file4, file5
…......
/"yr"=2012/"mon"=05/"day"=30/file100, file101
通过上述目录结构,我们可以看到表可以设置年、月和日来设置分区。查询的时候可以使用yr、mon、和day作为过滤字段,同时也可以限制在特定的查询时间访问特定的值下面的数据。我们可以观察下路径中文件夹的名称,分区的文件夹名称都是如yr=、mon=和day=这样的标识的。
在和一个高科技公司合作时,我们发现他们的文件夹没有这个明确的分区命名,而且他们不能改变他们现有的目录结构。但他们仍然希望受益于分区。他们的样品目录结构如下所示:
hdfs://user/uname/folder/2012/01/01/file1, file2, file3
/2012/01/02/file4, file5
…….
/2012/05/30/file100, file101
在这种情况下,我们仍然可以通过使用ALTER table语句显式地添加分区并为表添加绝对路径位置。一个简单的外部脚本可以读取目录并为ALTER TABLE语句中添加yr=、mon=、day=这样的信息并提供对应的有效的具体的文件夹名称(如yr=2012, mon=01,...)。脚本的输出是一组使用具体的目录结构的Hive SQL语句,而且保存在一个简单的文本文件中。
ALTER TABLE tablename
ADD PARTITION (yr=2012, mon=01, day=01) location '/user/uname/folder/ 2012/01/01/';
ALTER TABLE tablename
ADD PARTITION (yr=2012, mon=01, day=02) location '/user/uname/folder/ 2012/01/02/';
...
ALTER TABLE tablename
ADD PARTITION (yr=2012, mon=05, day=30) location '/user/uname/folder/ 2012/05/30/';
当在Hive中执行这些语句时,指定的目录下的数据就会出现在使用ALTER TABLE语句创建并定义的逻辑分区中。
提示
用户应该确保表是通过PARTITIONED BY语句为年、月和日创建分区字段的。
3.Customer trenches #3: 使用 Regex、Lateral View Explode、Ngram和其他一些 UDF 进行文本分析
许多与我们合作的公司都有文本分析的场景, 包括简单到复杂的情况。理解和使用Hive regex函数、范式和其他字符串处理函数可以解决大量的此类使用场景。
一个与我们合作的大型制造业客户有很多机器生成压缩文本数据存储到了Hadoop中。这个数据的格式如下。
① 每个文件中具有多行数据,而一个按照时间分区的数据桶内包含有许多这样的文件。
② 每一行数据都有许多按照/ r / n(回车和换行)进行划分的列。
③ 每列数据的形式是一个“名称:值”对。
用例的要求如下。
① 读取每一行数据并将每列转换成“名称-值”对。
② 在特定的列中,进行词频统计和单词模式分析来分析关键词和特定的消息内容。
下面的示例展示了这个客户的样本数据资料(其中省略了一些文本内容):
name:Mercury\r\ndescription:Mercury is the god of commerce, ...\r\ntype: Rocky planet
name:Venus\r\ndescription:Venus is the goddess of love...\r\ntype:Rocky planet
name:Earch\r\ndescription:Earth is the only planet ...\r\ntype:Rocky planet
name:Mars\r\ndescription: Mars is the god of War...\r\ntype:Rocky planet
name:Jupiter\r\ndescription:Jupiter is the King of the Gods...\r\ntype: Gas planet
name:Saturn\r\ndescription:Saturn is the god of agriculture...\r\ntype: Gas planet
name:Uranus\r\ndescription:Uranus is the God of the Heavens...\r\ntype: Gas planet
name:Neptune\r\ndescription:Neptune was the god of the Sea...\r\ntype:Gas planet
数据具有如下几方面特点。
① 行星的名字和他们的包含类型的描述信息。
② 每一行的数据是由一个分隔符分隔。
③ 在每一行有3个部分,包括“名称”、“描述”和“类型”,按照/ r / n进行字段划分。
④ 其中“描述”是一个大的文本内容。
第一步是使用此示例数据创建初始表:
CREATE TABLE planets (col0 string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION 'hdfs://hostname/user/uname/planets/'
接下来,我们运行一系列的查询,从一个使用了函数的简单的查询开始。需要注意的是用几种不同的方式编写的查询来满足相同的需求。如下查询语句的目的是演示Hive对文本解析一些关键功能。
首先,我们使用一个split函数来将数据划分的不同列保存到数组中:
SELECT split(col0, '(\\\\r\\\\n)') AS splits FROM planets;
接下来,我们LATERAL VIEW EXPLODE 函数来将划分(也就是这个数组)进行展开。这个查询的结果将是每行都是一个“名称-值”对。我们只选择那些以‘desc’开头的行。LTRIM这个函数是用来去除左端的空白字符的。
SELECT ltrim(splits) AS pairs FROM planets
LATERAL VIEW EXPLODE(split(col0, '(\\\\r\\\\n)')) col0 AS splits
WHERE ltrim(splits) LIKE 'desc%'
现在我们描述的信息转换成了“名称-值”对,并选择有值的数据。这可以以不同的方式完成的。我们使用根据“:”进行分割并选择“值”那部分数据:
SELECT (split(pairs, ':'))[1] AS txtval FROM (
SELECT ltrim(splits) AS pairs FROM planets
LATERAL VIEW EXPLODE(split(col0, '(\\\\r\\\\n)')) col0 AS splits
WHERE ltrim(splits) LIKE 'desc%')tmp1;
需要注意的是对于内部查询我们使用了临时标识符tmp1。当用户使用子查询的输出作为外层查询的输入时,使用别名是必须的。步骤3处理后,我们获取到“描述”中每一行的“值”部分的数据。
在接下来的步骤中,我们使用ngrams函数来显示行星描述名称前10双字母组名单词。用户也可以使用如context_ngram、find_in_set、regex_replace和其他各种各样的基于文本分析的函数:
SELECT ngrams(sentences(lower(txtval)), 2, 10) AS bigrams FROM (
SELECT (split(pairs, ':'))[1] AS txtval FROM (
SELECT ltrim(splits) AS pairs FROM planets
LATERAL VIEW EXPLODE(split(col0, '(\\\\r\\\\n)')) col0 AS splits
WHERE ltrim(splits) LIKE 'desc%') tmp1) tmp2;
需要注意的是,我们已经使用了像lower这样的函数来将大写字母全部转换成小写,以及使用sentences函数将文本中内容分割成单词。
关于Hive中文本分析函数的更多信息,可以参考第3章中列举的函数。
生产环境下的Apache Hive:快速增长的需求和能力。
Hive会保持继续成长,正如前面所定义的使用场景所展示的。在不同行业和不同规模的公司都将在Hadoop环境中使用Hive而受益无穷。一个强大和积极的贡献者社区,以及由Hadoop领先供应商提供的重大的研发投资,都将确保Hive已经是Hadoop之上的基于SQL的标准了,它将会成为利用Hadoop为大数据分析的标准组织中基于SQL处理的标准。
随着公司投入大量资源和时间来理解和构建Hive资源,在很多情况下,我们发现他们寻找额外的能力,使他们能够建立在他们的初始使用Hive的基础之上,并达到更快的扩展、在他们的组织内更广泛的应用。从处理这些客户希望Hive进化到到下一个级别的需求中,有一套共同的需求已经出现了。这些需求包括如下几方面。
① 多用户环境协作。Hadoop提供了相对于传统的RDBMS的新的分析类别,在计算能力和成本上都具有优势。使用Hadoop,组织机构可以将数据和人进行分离,可以在他们可获取的每个字节的数据上执行分析,这些都通过一种方式,可以使他们能够与其他个体、团队、组织和系统分享他们的查询结果和见解。这个模型意味着为用户提供深入理解需要合作发现这些不同的数据集,再分享见解和整个组织中基于Hive分析的可用性。
② 增强生产力。Hive的当前的实现提供了一个在Hadoop之上的系列批处理环境。这意味着,一旦用户向Hadoop集群中提交一个查询作业,他们必须等待查询完成之后才能向集群提交并执行另一个查询。这可以限制用户的生产力。企业采用Hive的一个主要原因是,它使他们的SQL技术数据专业人员可以更快和更容易使用Hadoop。这些用户通常熟悉SQL编辑工具和BI产品。他们正在寻找类似的生产力环境例如增强语法高亮、代码自动完成。
③ Hive资产管理。麦肯锡近期的一份报告通过他们的数据预测了缺乏熟练的工人,可以显著降低使组织牟利。像Hive这样的技术通过允许人们在Hadoop可以用SQL技能进行分析来解决技能短缺问题。然而,组织意识到仅仅让他们的用户使用Hive是不够的。他们需要能够管理Hive资产,如查询语句(包含历史操作和版本信息)、众多的UDF、SerDe等,可以在以后进行分享和重用。组织想要构建这个Hive资产的知识存储库,而且用户可以很容易搜索到。
④ 为先进的分析技术对Hive进行扩展。许多公司正在寻找在Hadoop中重建他们在传统的RDBMS中分析的系统。虽然并不是SQL环境的所有功能都很容易转化为Hive函数,其中一些是因为数据存储的固有局限性,有一些高级分析功能(像RANK,等等),这些Hadoop是可以进行处理的。此外,组织使用传统工具如SAS和SPSS花了巨大的资源和时间在构建分析模型上,并希望能够在Hadoop通过Hive查询更好地使用这些模型。
⑤ SQL技能外扩展Hive。因为Hadoop在组织中积蓄了大量优势,并成为一个IT基础设施之上的关键的数据处理和分析架构,这在具有不同的技能和能力的用户当中很流行。尽管Hive很容易适应具有SQL技能的用户,其他的懂得SQL并不多的用户也在寻求可以在基于Hadoop的Hive上像在传统的BI工具中通过拖拖拽拽就可以执行分析的功能。能够在Hive之上支持交互式表单,能够通过简单的基于Web的形式提示用户提供的列值是一种常见的功能。
⑥ 数据探索能力。传统的数据库技术提供数据浏览功能。例如,一个用户可以查看一个整数列的最小值,最大值。此外,用户还可以通过可视化的方式查看这些列,在他们执行分析数据之前理解数据分布。因为Hadoop存储了数百TB的数据,并且通常是PB级别的,对于特定的使用场景,顾客需要类似的功能。
⑦ 调度和操作Hive查询。当公司使用具有Hadoop的Hive发现了一些深刻见解时,他们也在寻求实施这些见解和安排在一个正则区间运行这些查询。虽然目前已经有了可用的开源替代方案,但当公司也想管理Hive查询的输出时就会功亏一篑。例如,将结果集转移到一个传统的RDBMS系统或BI堆栈。管理特定的用例,公司通常必须手工串起各种不同的开源工具或依靠可怜的JDBC连接器进行执行。
⑧ 关于Karmasphere。Karmasphere是一家软件公司,位于加州硅谷,专注于帮助分析师团队和业务用户使用Hadoop的大数据分析能力。他们的旗舰产品,Karmasphere 2.0,是基于Apahce Hive的,并扩展实现了多用户图形化工作空间。
a.重用标准的Hive表、SerDe和UDF。
b.为分析师团队和业务用户提供社交化的、基于项目的大数据分析服务。
c.可以方便和其他集群进行数据整合。
d.基于启发式的识别和提供多种流行的数据存储格式来创建表。
e.可视化的和迭代式的数据探索和分析。
f.图形化的对基于Hive的数据集进行分析探索。
g.可以共享和调度查询以及结果,并提供可视化操作和展示。
h.和传统表格、报表、仪表盘、BI工具很容易进行集成整合。
图23-4展示了Karmasphere 2.0的基于Hive的大数据分析环境的操作界面截图。
图23-4 Karmasphere 2.0的屏幕截图
⑨ Hive特性调查。对于这些需求我们期望能得到反馈并最终能在快速发展的Hive社区中进行分享。
来源:我是码农,转载请保留出处和链接!
本文链接:http://www.54manong.com/?id=1201
微信号:qq444848023 QQ号:444848023
加入【我是码农】QQ群:864689844(加群验证:我是码农)
- 赤裸裸的统计学:除去大数据的枯燥外衣,呈现真实的数字之美 - 电子书下载 -(百度网盘 高清版PDF格式)2018-12-31 21:09
- Redis入门指南 - 电子书下载 -(百度网盘 高清版PDF格式)2018-12-31 21:34
- Spark大数据处理:技术、应用与性能优化 (大数据技术丛书) - 电子书下载 -(百度网盘 高清版PDF格式)2018-12-31 21:15
- 大规模分布式存储系统:原理解析与架构实战 (大数据技术丛书) - 电子书下载 -(百度网盘 高清版PDF格式)2018-12-31 21:04
网站分类
- 数据结构
- 数据结构视频教程
- 数据结构练习题
- 数据结构试卷
- 数据结构习题解析
- 数据结构电子书
- 数据结构精品文章
- 区块链
- 区块链精品文章
- 区块链电子书
- 大数据
- 大数据精品文章
- 大数据电子书
- 机器学习
- 机器学习精品文章
- 机器学习电子书
- 面试笔试
- 物联网/云计算
标签列表
- 数据结构 (39)
- 数据结构电子书 (20)
- 数据结构习题解析 (8)
- 数据结构试卷 (10)
- 区块链是什么 (261)
- 数据结构视频教程 (31)
- 大数据技术与应用 (12)
- 百面机器学习 (14)
- 机器学电子书 (29)
- 大数据电子书 (37)
- 程序员面试 (10)
- RFID (21)
最近发表
- 找出数组中有3个出现一次的数字
- 《百面机器学习》电子书下载
- 区块链精品电子书《深度探索区块链:Hyperledger技术与应用_区块链技术丛书》张增骏
- 区块链精品电子书《比特币:一个虚幻而真实的金融世界》
- 区块链精品电子书《图说区块链》-徐明星 & 田颖 & 李霁月
- 区块链精品电子书《是非区块链:技术、投机与泡沫》-英国《金融时报》
- 区块链精品电子书《商业区块链:开启加密经济新时代》-威廉·穆贾雅
- 区块链精品电子书《人工智能时代,一本书读懂区块链金融 (互联网_时代企业管理实战系列)》-马兆林
-
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https'){
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else{
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
全站首页 | 数据结构 | 区块链| 大数据 | 机器学习 | 物联网和云计算 | 面试笔试
var cnzz_protocol = (("https:" == document.location.protocol) ? "https://" : "http://");document.write(unescape("%3Cspan id='cnzz_stat_icon_1276413723'%3E%3C/span%3E%3Cscript src='" + cnzz_protocol + "s23.cnzz.com/z_stat.php%3Fid%3D1276413723%26show%3Dpic1' type='text/javascript'%3E%3C/script%3E"));本站资源大部分来自互联网,版权归原作者所有!






评论专区