
常见的采样方法 - 数据结构 - 机器学习
常见的采样方法
2887 人参与 2019年01月16日 11:20 分类 : 机器学习精品文章 评论
场景描述
对于一个随机变量,通常用概率密度函数来刻画该变量的概率分布特性。具体来说,给定随机变量的一个取值,可以根据概率密度函数来计算该值对应的概率(密度)。反过来,也可以根据概率密度函数提供的概率分布信息来生成随机变量的一个取值,这就是采样。因此,从某种意义上来说,采样是概率密度函数的逆向应用。与根据概率密度函数计算样本点对应的概率值不同,采样过程往往没有那么直接,通常需要根据待采样分布的具体特点来选择合适的采样策略。
知识点
逆变换采样,拒绝采样,重要性采样
问题 抛开那些针对特定分布而精心设计的采样方法,说一些你所知道的通用采样方法或采样策略,简单描述它们的主要思想以及具体操作步骤。
难度:★★★☆☆
分析与解答
几乎所有的采样方法都是以均匀分布随机数作为基本操作。均匀分布随机数一般用线性同余法来产生,上一小节有具体介绍,这里不再赘述。
首先假设已经可以生成[0,1]上的均匀分布随机数。对于一些简单的分布,可以直接用均匀采样的一些扩展方法来产生样本点,比如有限离散分布可以用轮盘赌算法来采样。然而,很多分布一般不好直接进行采样,可以考虑函数变换法。一般地,如果随机变量x和u存在变换关
系 则它们的概率密度函数有如下关系:
则它们的概率密度函数有如下关系:

因此,如果从目标分布p(x)中不好采样x,可以构造一个变换
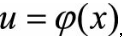
使得从变换后的分布p(u)中采样u比较容易,这样可以通过先对u进行采样然后通过反函数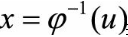
来间接得到x。如果是高维空间的随机向量,则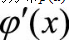
对应Jacobian行列式。
特别地,在函数变换法中,如果变换关系φ(·)是x的累积分布函数的话,则得到所谓的逆变换采样(Inverse Transform Sampling)。假设待采样的目标分布的概率密度函数为p(x),它的累积分布函数为

则逆变换采样法按如下过程进行采样:
(1)从均匀分布U(0,1)产生一个随机数ui;
(2)计算
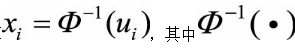
是累积分布函数的逆函数。
根据式(8.2)和式(8.3),上述采样过程得到的xi服从p(x)分布。图8.2是逆变换采样法的示意图。
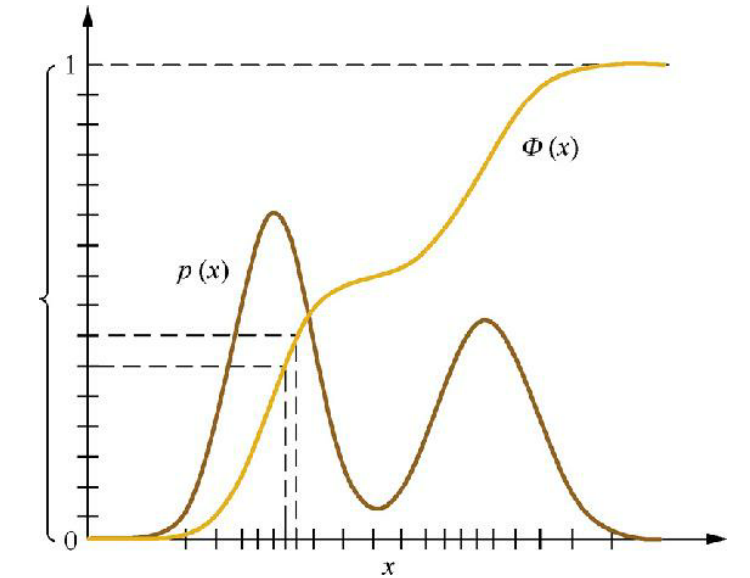
图8.2 逆变换采样示意图
如果待采样的目标分布的累积分布函数的逆函数无法求解或者不容易计算,则不适用于逆变换采样法。此时可以构造一个容易采样的参考分布,先对参考分布进行采样,然后对得到的样本进行一定的后处理操作,使得最终的样本服从目标分布。常见的拒绝采样(Rejection Sampling)、重要性采样(Importance Sampling),就属于这类采样算法,下面分别简单介绍它们的采样过程。
拒绝采样,又叫接受/拒绝采样(Accept-Reject Sampling)。对于目标分布p(x),选取一个容易采样的参考分布q(x),使得对于任意x都有
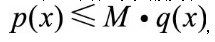
则可以按如下过程进行采样:
(1)从参考分布q(x)中随机抽取一个样本xi。
(2)从均匀分布U(0,1)产生一个随机数ui。
(3)如果
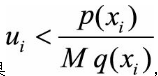
则接受样本xi ;否则拒绝,重新进行步骤(1)~(3),直到新产生的样本xi被接受。
通过简单的推导,可以知道最终得到的xi服从目标分布p(x)。如图8.3(a)所示,拒绝采样的关键是为目标分布p(x)选取一个合适的包络函数M·q(x):包络函数越紧,每次采样时样本被接受的概率越大,采样效率越高。在实际应用中,为了维持采样效率,有时很难寻找一个解析形式的q(x),因此延伸出了自适应拒绝采样(Adaptive Rejection Sampling),在目标分布是对数凹函数时,用分段线性函数来覆盖目标分布的对数ln p(x),如图8.3(b)所示,这里不再细述。
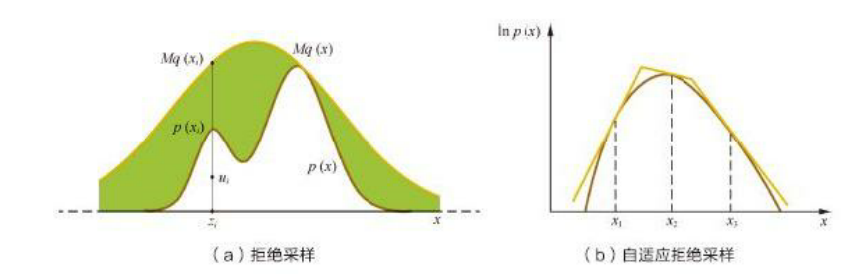
图8.3 拒绝采样示意图
很多时候,采样的最终目的并不是为了得到样本,而是为了进行一些后续任务,如预测变量取值,这通常表现为一个求函数期望的形式。重要性采样就是用于计算函数f(x)在目标分布p(x)上的积分(函数期望),即
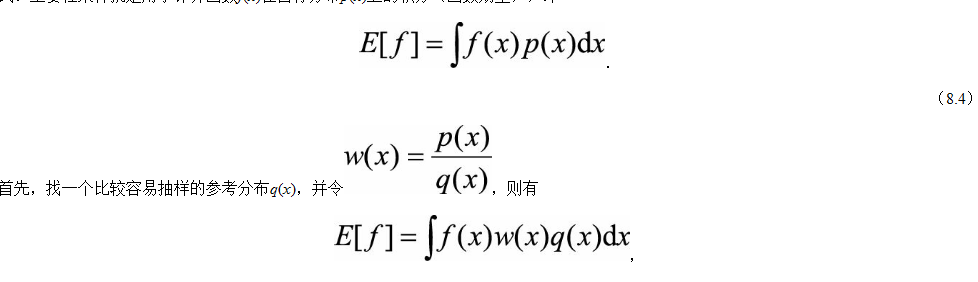
(8.5)
这里w(x)可以看成是样本x的重要性权重。由此,可以先从参考分布q(x)中抽取N个样本{xi},然后利用如下公式来估计E[f]:
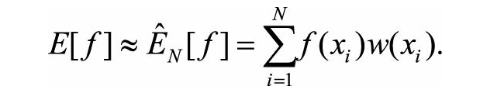
(8.6)
图8.4是重要性采样的示意图。如果不需要计算函数积分,只想从目标分布p(x) 中采样出若干样本,则可以用重要性重采样(Sampling-Importance Re-sampling,SIR),先在从参考分布q(x)中抽取N个样本 {xi },然后按照它们对应的重要性权重{w(xi)}对这些样本进行重新采样(这是一个简单的针对有限离散分布的采样),最终得到的样本服从目标分布p(x)。
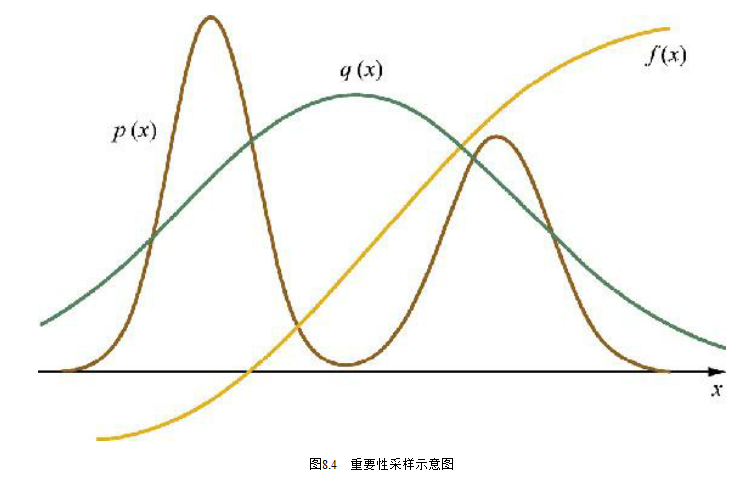
在实际应用中,如果是高维空间的随机向量,拒绝采样和重要性重采样经常难以寻找合适的参考分布,采样效率低下(样本的接受概率小或重要性权重低),此时可以考虑马尔可夫蒙特卡洛采样法,常见的有Metropolis-Hastings采样法和吉布斯采样法。后续会专门介绍马尔可夫蒙特卡洛采样法,这里不再赘述。
·总结与扩展·
上述解答中我们只是列举了几个最常用的采样算法,简单介绍了它们的具体操作。在实际面试时,面试官可能会让面试者选择其最熟悉的某个采样算法来回答,然后较深入地问一下该算法的理论证明、优缺点、相关扩展和应用等。例如,为何拒绝采样或重要性采样在高维空间中会效率低下而无法使用?如何从一个不规则多边形中随机取一个点?
来源:我是码农,转载请保留出处和链接!


评论专区