
14.1:软件磁盘阵列 (Software RAID)
阵列 (RAID) 的目的主要在'加大磁盘容量'、'具有磁盘容错'、'增加读写效能'等方面,而根据你着重的面向就得要使用不同的磁盘阵列等级了。
14.1.1:什么是 RAID
磁盘阵列全名是' Redundant Arrays of Independent Disks, RAID ',英翻中的意思为:独立容错式磁盘阵列,旧称为容错式廉价磁盘阵列, 反正就称为磁盘阵列即可! RAID 可以通过一个技术(软件或硬件),将多个较小的磁盘整合成为一个较大的磁盘设备; 而这个较大的磁盘功能可不止是储存而已,他还具有数据保护的功能。 整个 RAID 由于选择的等级 (level) 不同,而使得整合后的磁盘具有不同的功能,基本常见的 level 有这几种:
RAID-0 (等量模式, stripe, 性能最佳):两颗以上的磁盘组成RAID-0时,当有100MB的数据要写入,则会将该数据以固定的chunk 拆解后,分散写入到两颗磁盘,因此每颗磁盘只要负责50MB的容量读写而已。 如果有8颗组成时,则每颗仅须写入12.5MB,速度会更快。 此种磁盘阵列性能最佳, 容量为所有磁盘的总和,但是不具容错功能。
RAID-1 (映射模式, mirror, 完整备份):大多为 2 的倍数所组成的磁盘阵列等级。 若有两颗磁盘组成 RAID-1 时,当有 100MB 的数据要写入, 每颗均会写入 100MB,两颗写入的数据一模一样 (磁盘映射 mirror 功能),因此被称为最完整备份的磁盘阵列等级。 但因为每颗磁盘均须写入完整的资料, 因此写入效能不会有明显的提升,但读取的效能会有进步。 同时容错能力最佳,但总体容量会少一半。
RAID 1+0:此种模式至少需要 4 颗磁盘组成,先两两组成 RAID1,因此会有两组 RAID1,再将两组 RAID1 组成最后一组 RAID0,整体数据有点像底下的图标:
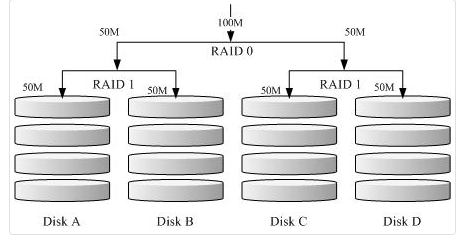
图 14.1.1-1、RAID-1+0 的磁盘写入示意图 因此效能会有提升,同时具备容错,虽然容量会少一半。
RAID 5, RAID 6 (效能与数据备份的均衡考量):RAID 5 至少需要 3 颗磁盘组成,在每一层的 chunk 当中,选择一个进行备份, 将备份的数据平均分散在每颗磁盘上,因此任何一颗磁盘损毁时,都能够重建出原本的磁盘资料,原理图标有点像底下这样:
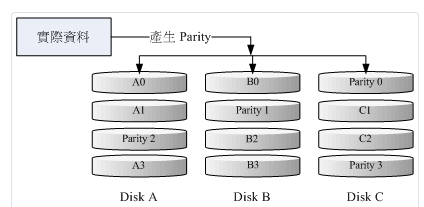
图 14.1.1-2、RAID-5 的磁盘写入示意图 因为有一颗容量会用在备份上,因此总体容量少一颗,而为了计算备份的同位检查码(partity),因此效能较难评估,原则上,效能比起单颗磁盘还是会稍微提升。 不过还是具备有容错功能,在越多颗磁盘组成时,比RAID-1要节省很多的容量。 不过为了担心单颗备份还是不太足够,因此有 RAID 6 可以使用两个 partity 来备份, 因此会占用两颗容量就是了。
| 项目 | RAID0 | RAID1 | RAID10 | RAID5 | RAID6 |
| 最少磁盘数 | 2 | ||||
| 最大故障磁盘数(1) | 无 | n-1 | |||
| 数据安全(1) | 完全没有 | ||||
| 理论写入性能(2) | n | 1 | n/2 | <n-1 | <n-2 |
| 理论读出性能(2) | n | n | n | <n-1 | <n-2 |
| 可用容量(3) | n | 1 | |||
| 一般应用 | 强调效能但数据不重要的环境 | 资料与备份 | 服务器、云系统常用 | 资料与备份 | 资料与备份 |
而实现磁盘阵列功能的,主要有硬件RAID与软件RAID。
硬件磁盘阵列:中高阶硬件RAID为独立的RAID芯片,内含CPU运算功能,可以运算类似RAID 5/6的parity数据,据以写入磁盘当中。 越高阶的 RAID 还具有更多的缓存 (cache memory),可以加速读/写的性能。 由于是硬件磁盘阵列组成的'大容量磁盘',因此 Linux 会将他视为一颗独立的物理磁盘,文件名通常就是 /dev/sd[abcd..]。
软体磁盘阵列:由操作系统提供模拟,通过 CPU 与 mdadm 软件模拟出中高阶磁盘阵列卡的功能,以达到磁盘阵列所需要的性能、容错、容量增大的功能。 因为是操作系统模拟的,因此文件名会是 /dev/md[0123..]。 这种作法很常见于 NAS 文件服务器环境中。
14.1.2:Software RAID 的使用
Software RAID 主要通过 mdadm 这个软件的协助,因此需要先确认 mdadm 是否安装妥当。 而 mdadm 的指令也相当简单,范例如下:
建立磁盘阵列
[root@localhost ~]# mdadm --create /dev/md[0-9] --auto=yes --level=[015] --chunk=NK \> --raid-devices=N --spare-devices=N /dev/sdx --create :為建立 RAID 的選項; --auto=yes :決定建立後面接的軟體磁碟陣列裝置,亦即 /dev/md0, /dev/md1... --level=[015] :設定這組磁碟陣列的等級。支援很多,不過建議只要用 0, 1, 5 即可 --chunk=Nk :決定這個裝置的 chunk 大小,也可以當成 stripe 大小,一般是 64K 或 512K。 --raid-devices=N :使用幾個磁碟 (partition) 作為磁碟陣列的裝置 --spare-devices=N :使用幾個磁碟作為備用 (spare) 裝置
先检查 mdadm 是否存在于你的系统内? 一般来说是存在的,若不存在,请自行安装。
进行磁盘分割,需要用到5个容量皆为300M的分割槽,注意partition ID喔!
使用下面的数据来创建好你的磁盘阵列 :
创建的磁盘阵列先使用 /dev/md0 作为设备的文件名 (此设备文件名系统可能会自己调整)
利用4个partition组成RAID 5;
利用 1 个 partition 设定为 spare disk
chunk 设定为 256K 这么大即可!
使用优化参数处理 XFS 文件系统格式化 :
su 为指定 stripe 宽度,所以可以指定为 256K
sw 为指定多少个 stripe,因为 4 个组成 RAID5,所以只有提供 (4-1)=3 个资料,因此 sw 为 3 才对。
格式化 mkfs.xfs 要带入上述参数才好
将此 RAID 5 设备挂载到 /srv/raid 目录下
观察磁盘阵列
磁盘阵列建置妥当后,应该观察一下运作的状况比较妥当。 主要的观察方式为:
[root@localhost ~]# mdadm --detail /dev/md[0-9][root@localhost ~]# cat /proc/mdstat
需要注意到是否有磁盘在损毁的状况才行。
磁盘阵列的救援功能
假设 (1)磁盘阵列有某颗磁盘损毁了,或 (2)磁盘使用寿命也差不多,预计要整批换掉时,使用抽换的方式一颗一颗替换,如此则不用重新建立磁盘阵列。
在此情况下,管理员应该要将磁盘阵列设定为损毁,然后将之抽离后,换插新的硬盘才可以。 基本的指令需求如下:
[root@localhost ~]# mdadm --manage /dev/md[0-9] [--add 裝置] [--remove 裝置] [--fail 裝置] --add :會將後面的裝置加入到這個 md 中! --remove :會將後面的裝置由這個 md 中移除 --fail :會將後面的裝置設定成為出錯的狀態
先观察刚刚建立的磁盘阵列是否正常运作,同时观察文件系统是否正常 (/srv/raid 是否可读写)
将某颗运作中的磁盘 (例如 /dev/vda7) 设置为错误 (--fail),再观察磁盘阵列与档案系统
将错误的磁盘抽离 (--remove) 之后,假设修理完毕,再加入该磁盘阵列 (--add),然后再次观察磁盘阵列与档案系统
14.2:逻辑卷轴管理器 (Logical Volume Manager)
虽然RAID可以将档案系统容量增加,也有效能增加与容错的机制,但是就是没有办法在既有的档案系统架构下,直接将容量放大的机制。 此时,可以弹性放大与缩小的LVM辅助,就很有帮助了。 不过LVM主要是在弹性的管理档案系统,不在于效能与容错上。 因此,若需要容错与效能,可以将LVM放置到RAID设备上即可。
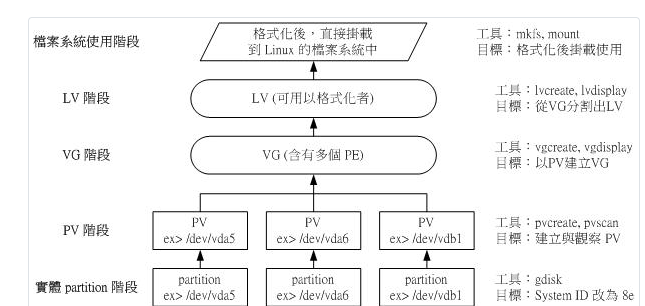
14.2.1:LVM 基础: PV, PE, VG, LV 的意义
LVM 的全名是 Logical Volume Manager,中文可以翻译作逻辑卷轴管理员。 之所以称为'卷轴'可能是因为可以将 filesystem 像卷轴一样伸长或缩短之故! LVM 的作法是将几个实体的 partitions (或 disk) 透过软体组合成为一块看起来是独立的大磁盘 (VG) , 然后将这块大磁盘再经过分割成为可使用分割槽 (LV), 最终就能够挂载使用了。
Physical Volume, PV, 实体卷轴:作为 LVM 最基础的物理卷轴,可以是 partition 也可以是整颗 disk。
Volume Group, VG, 卷轴群组:将许多的 PV 整合成为一个卷轴群组 (VG),这就是所谓的最大的主要大磁盘。 读者应该知道磁盘的最小储存单位为sector,目前主流sector为512bytes或4K。 而LVM也有最小储存单位,那就是Physical Extent(PE),所有的资料都是透过PE在VG当中进行交换的。
Physical Extent, PE, 实体范围区块:PE 是整个 LVM 最小的存储区块,系统的档案资料都是借由写入 PE 来处理的。 简单的说,这个 PE 就有点像文件系统里面的 block 。 PE 默认需要是 2 的次方量,且最小为 4M 才行。
Logical Volume, LV, 逻辑卷轴:最终将 VG 再切割出类似 partition 的 LV 即是可使用的设备了。 LV 是借由《分配数个 PE 所组成的装置》,因此 LV 的容量与 PE 的容量大小有关。
上述谈到的数据,可使用下图来解释彼此的关系:
14.2.2:LVM 实做流程
如前一小节所述,管理员若想要处理 LVM 的功能,应该从 partition --> PV --> VG --> LV --> filesystem 的角度来处理。 请使用下面的设置来实做出一组LVM来使用:
使用4个partition,每个partition的容量均为300MB左右,且system ID需要为8e;
全部的 partition 整合成为一个 VG,VG 名称设定为 myvg ;且 PE 的大小为 16MB;
建立一个名为 mylv 的 LV,容量大约设定为 500MB 左右
最终这个LV格式化为xfs的档案系统,且挂载在/srv/lvm中
先使用 gdisk 或 fdisk 分割出本案例所需要的 4 个分割,假设分割完成的磁盘档名为 /dev/vda{9,10,11,12} 四个。 接下来即可使用LVM提供的指令来处理后续工作。 一般来说, LVM 的三个阶段 (PV/VG/LV) 均可分为'建立'、'扫描'与'详细查阅'等步骤, 其相关指令可以汇整如下表:
| 任务 | PV阶段 | VG 阶段 | LV 阶段 | filesystem (XFS / EXT4) | |
| 搜索(scan) | pvscan | vgscan | lvscan | lsblk, blkid | |
| 创建(create) | pvcreate | vgcreate | lvcreate | mkfs.xfs | mkfs.ext4 |
| 列出(display) | pvdisplay | vgdisplay | lvdisplay | df, mount | |
| 增加(extend) | vgextend | lvextend (lvresize) | xfs_growfs | resize2fs | |
| 减少(reduce) | vgreduce | lvreduce (lvresize) | 不支持 | resize2fs | |
| 删除(remove) | pvremove | vgremove | lvremove | umount, 重新格式化 | |
| 改变容量(resize) | lvresize | xfs_growfs | resize2fs | ||
| 更改属性(attribute) | pvchange | vgchange | lvchange | /etc/fstab, remount | |
PV阶段
所有的 partition 或 disk 均需要做成 LVM 最底层的实体卷轴,直接使用 pvcreate /device/name 即可。 实做完成后,记得使用 pvscan 查阅是否成功。
[root@localhost ~]# pvcreate /dev/vda{9,10,11,12}[root@localhost ~]# pvscan
PV /dev/vda3 VG centos lvm2 [20.00 GiB / 5.00 GiB free]
PV /dev/vda12 lvm2 [300.00 MiB]
PV /dev/vda11 lvm2 [300.00 MiB]
PV /dev/vda10 lvm2 [300.00 MiB]
PV /dev/vda9 lvm2 [300.00 MiB]
Total: 5 [21.17 GiB] / in use: 1 [20.00 GiB] / in no VG: 4 [1.17 GiB]VG 阶段
VG 比较需要注意的有三个项目:
VG 内的PE数值需要是2的倍数,如果没有设定,预设会是4MB
VG 需要给名字
需要指定哪几个PV加入这个 VG 中。
根据上述的数据,使用 vgcreate --help 可以找到相对应的选项与参数,于是使用如下的指令来完成 VG 的任务:
[root@localhost ~]# vgcreate -s 16M myvg /dev/vda{9,10,11,12}[root@localhost ~]# vgdisplay myvg
--- Volume group ---
VG Name myvg
System ID
Format lvm2
Metadata Areas 4
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 4
Act PV 4 VG Size 1.12 GiB
PE Size 16.00 MiB
Total PE 72
Alloc PE / Size 0 / 0
Free PE / Size 72 / 1.12 GiB
VG UUID R8lCNk-H71V-g0XW-OtZe-pCFk-3H0d-OHZQ5pLV 阶段
LV 为实际被使用在档案系统内的装置,建置时需要考量的项目大概有:
使用哪一个 VG 来进行 LV 的建置
使用多大的容量或多少个PE来建置
亦需要有 LV 的名字
同样使用 lvcreate --help 查阅,之后可以得到如下的选项与参数之设定:
[root@localhost ~]# lvcreate -n mylv -L 500M myvg Rounding up size to full physical extent 512.00 MiB Logical volume "mylv" created. [root@localhost ~]# lvdisplay /dev/myvg/mylv --- Logical volume --- LV Path /dev/myvg/mylv LV Name mylv VG Name myvg LV UUID ySi50J-pLoN-fjAq-tJmI-hNts-cwkT-fGxuBe LV Write Access read/write LV Creation host, time station200.centos, 2020-06-08 16:57:44 +0800 LV Status available # open 0 LV Size 512.00 MiB Current LE 32 Segments 2 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:3
由于实际建立的LV大小是由PE的数量来决定,因为本案例中使用16MB的PE,因此不会刚好等于500MB,故LV自动选择接近500MB的数值来建立,因此上表中会得到使用512MB的容量。
另外,最终实际可用的LV装置名称为 /dev/myvg/mylv ,而因为LVM又是由 device mapper 的服务所管理的, 因此最终的名称也会指向到 /dev/mapper/myvg-mylv 当中。 无论如何,读者仅需要记忆 /dev/myvg/mylv 这种格式的设备文件名即可。
请将上述的 /dev/myvg/mylv 实际格式化为 xfs 文件系统,且此 fileysytem 可以开机后自动挂载于 /srv/lvm 目录下。
再建立一个名为 /dev/myvg/mylvm2 的 LV 装置,容量约为 300MB 左右,格式化为 ext4 档案系统,开机后自动挂载于 /srv/lvm2 目录下。
14.2.3:弹性化处理LVM档案系统
LVM 最重要的任务就是进行装置的容量放大与缩小,不过,前提是在该装置下的档案系统能够支持放大与缩小才行。 目前在CentOS 8上面主要的两款档案系统中,ext4可以放大与缩小,但是xfs档案系统则仅能放大而已。 因此使用上需要特别注意。
将 myvg 所有剩余容量分配给 /dev/myvg/mylvm2
从上面的案例中,读者可以知道 myvg 这个 VG 的总容量 1.1G 当中,有 500M 给 /dev/myvg/mylv 而 300M 给 /dev/myvg/mylvm2, 因此剩下大约 300MB 左右,读者可以使用' vgdisplay myvg '来查询剩余的容量。 如果需要将文件系统放大,则需要进行:
先将 mylvm2 放大
再将上面的档案系统放大
上述两个步骤的顺序不可错乱。 将 mylvm2 放大的方式为:
[root@localhost ~]# vgdisplay myvg --- Volume group --- VG Name myvg System ID Format lvm2 Metadata Areas 4 Metadata Sequence No 3 VG Access read/write VG Status resizable MAX LV 0 Cur LV 2 Open LV 2 Max PV 0 Cur PV 4 Act PV 4 VG Size 1.12 GiB PE Size 16.00 MiB Total PE 72 Alloc PE / Size 51 / 816.00 MiB Free PE / Size 21 / 336.00 MiB VG UUID R8lCNk-H71V-g0XW-OtZe-pCFk-3H0d-OHZQ5p [root@localhost ~]# lvscan ACTIVE '/dev/myvg/mylv' [512.00 MiB] inherit ACTIVE '/dev/myvg/mylvm2' [304.00 MiB] inherit ACTIVE '/dev/centos/root' [10.00 GiB] inherit ACTIVE '/dev/centos/home' [3.00 GiB] inherit ACTIVE '/dev/centos/swap' [2.00 GiB] inherit
如上所示,读者可以发现剩余 21 个 PE,而目前 mylvm2 拥有 304MB 的容量。 因此,我们可以使用:
不考虑原本的,额外加上 21 个 PE 在 mylvm2 上面,或;
原有的304MB+336MB最终给予640MB的容量。
这两种方式都可以! 主要都是透过lvresize这个指令来达成。 要额外增加时,使用『 lvresize -l +21 ... 』的方式, 若要给予固定的容量,则使用『 lvresize -L 640M ... 』的方式,底下为额外增加容量的范例。
[root@localhost ~]# lvresize -l +21 /dev/myvg/mylvm2 Size of logical volume myvg/mylvm2 changed from 304.00 MiB (19 extents) to 640.00 MiB (40 extents). Logical volume myvg/mylvm2 successfully resized. [root@localhost ~]# lvscan ACTIVE '/dev/myvg/mylv' [512.00 MiB] inherit ACTIVE '/dev/myvg/mylvm2' [640.00 MiB] inherit ACTIVE '/dev/centos/root' [10.00 GiB] inherit ACTIVE '/dev/centos/home' [3.00 GiB] inherit ACTIVE '/dev/centos/swap' [2.00 GiB] inherit
完成了LV容量的增加,再来将档案系统放大。 EXT 家族的文件系统通过 resize2fs 这个指令来完成档案系统的放大与缩小。
[root@localhost ~]# df -T /srv/lvm2檔案系統 類型 1K-區段 已用 可用 已用% 掛載點 /dev/mapper/myvg-mylvm2 ext4 293267 2062 271545 1% /srv/lvm2 [root@localhost ~]# resize2fs /dev/myvg/mylvm2resize2fs 1.44.6 (5-Mar-2019) Filesystem at /dev/myvg/mylvm2 is mounted on /srv/lvm2; on-line resizing required old_desc_blocks = 3, new_desc_blocks = 5 The filesystem on /dev/myvg/mylvm2 is now 655360 (1k) blocks long. [root@localhost ~]# df -T /srv/lvm2檔案系統 類型 1K-區段 已用 可用 已用% 掛載點 /dev/mapper/myvg-mylvm2 ext4 626473 2300 590753 1% /srv/lvm2
VG 的容量不足,可增加额外磁盘的方式
假设读者因为某些特殊需求,所以需要将 /dev/myvg/mylv 档案系统放大一倍,亦即再加 500MB 时,该如何处理? 此时 myvg 已经没有剩余容量了。 此时可以通过额外给予磁盘的方式来增加。 此案例也是最常见到的情况,亦即在原有的档案系统当中已无容量可用,所以管理员需要额外加入新购置的磁盘的手段。 假设管理员已经通过 gdisk /dev/vda 新增一个 /dev/vda13 的 500MB 分割槽,此时可以这样做:
[root@localhost ~]# gdisk /dev/vda......
Command (? for help): nPartition number (13-128, default 13):
First sector (34-62914526, default = 51681280) or {+-}size{KMGTP}:
Last sector (51681280-62914526, default = 62914526) or {+-}size{KMGTP}: +500MCurrent type is 'Linux filesystem'
Hex code or GUID (L to show codes, Enter = 8300): 8e00Changed type of partition to 'Linux LVM'
Command (? for help): wDo you want to proceed? (Y/N): y[root@localhost ~]# partprobe[root@localhost ~]# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 252:0 0 40G 0 disk
├─vda9 252:9 0 300M 0 part
│ └─myvg-mylv 253:2 0 512M 0 lvm /srv/lvm
├─vda10 252:10 0 300M 0 part
│ ├─myvg-mylv 253:2 0 512M 0 lvm /srv/lvm
│ └─myvg-mylvm2 253:4 0 640M 0 lvm /srv/lvm2
├─vda11 252:11 0 300M 0 part
│ └─myvg-mylvm2 253:4 0 640M 0 lvm /srv/lvm2
├─vda12 252:12 0 300M 0 part
│ └─myvg-mylvm2 253:4 0 640M 0 lvm /srv/lvm2
└─vda13 252:13 0 500M 0 part <==剛剛管理員新增的部份[root@localhost ~]# pvcreate /dev/vda13
Physical volume "/dev/vda13" successfully created
[root@localhost ~]# vgextend myvg /dev/vda13
Volume group "myvg" successfully extended
[root@localhost ~]# vgdisplay myvg
--- Volume group ---
VG Name myvg
System ID
Format lvm2
Metadata Areas 5
Metadata Sequence No 5
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 2
Open LV 2
Max PV 0
Cur PV 5
Act PV 5
VG Size <1.61 GiB
PE Size 16.00 MiB
Total PE 103
Alloc PE / Size 72 / 1.12 GiB Free PE / Size 31 / 496.00 MiB
VG UUID R8lCNk-H71V-g0XW-OtZe-pCFk-3H0d-OHZQ5p此时系统即可多出将近 500MB 的容量给 myvg。
请将 myvg 的所有剩余的容量分配给 /dev/myvg/mylv
通过 xfs_growfs 来放大 /dev/myvg/mylv 这个文件系统 (请自行 man xfs_growfs)
你目前的系统中,根目录所在 filesystem 能否放大加入额外的 2GB 容量? 若可以,请实做,若不行,请说明原因。
14.3:Software RAID 与 LVM 综合管理
RAID 主要的目的在效能与容错(容量只是附加的),而LVM 重点在弹性管理档案系统(最好不要考量LVM内置的容错机制)。 若需要两者的优点,则可以在RAID上面建置LVM。 但以目前管理员的测试机而言,建议先关闭原有的测试流程,然后再重新建立为宜。
14.3.1:关闭与取消 software RAID 与 LVM 的方式
在本练习册中,我们并没有给予 RAID 的配置文件,因此删除掉分割槽后,系统应该会自动舍弃 software RAID (/dev/md0)。 不过,如果没有将每个分割槽的文件头资料删除,那未来重新开机时, mdadm 还是会尝试抓取 /dev/md0,这将造成些许困扰。 因此,建议删除掉 software RAID 的手段如下:
先将 /etc/fstab 当中,关于 /dev/md0 的纪录删除或注解;
将 /dev/md0 完整的卸载
使用 mdadm --stop /dev/md0 将 md0 停止使用
使用 dd if=/dev/zero of=/dev/vda4 bs=1M count=10 强制删除掉每个 partition 前面的 software RAID 标记
重复前一个步骤,将其他的 /dev/vda{5,6,7,8} 通通删除标记
将 /dev/md0 卸载,并且停止使用
将 /dev/vda{4,5,6,7,8} 这几个设备的表头数据 (有点类似 superblock) 删除
将这 5 个 partition 删除
LVM 的管理是很严格的,因此管理员不可在 LVM 活动中的情况下删除掉任何一个属于 LVM 的 partition/disk 才对。 例如目前 /dev/vda{9,10,11,12,13} 属于 myvg 这个 VG,因此如果 myvg 没有停止,那么管理员不应该也尽量避免更动到上述的分割槽。 若需要停止与回收这个 VG 的分割槽,应该要这样处理。
先将 /etc/fstab 当中与 myvg 有关的项目删除或注解
将 myvg 有关的档案系统卸载 (本案例中为 /srv/lvm 与 /srv/lvm2)
使用 vgchange -a n myvg 将此 VG 停用
使用 lvscan 確認一下 myvg 所屬的所有 LV 是否已經停用 (inactive)
使用 vgremove myvg 移除掉 myvg 这个 VG 的所有内容
使用 pvremove /dev/vda{9,10,11,12,13} 移除这些 PV
最终使用pvscan侦测是否顺利移除
卸载所有与 /dev/myvg/mylv, /dev/myvg/mylvm2 的装置,并将 myvg 设定为停用
移除 myvg
移除 /dev/vda{9,10,11,12,13} 这几个 PV
将上述的 partition 删除
14.3.2:在 Software RAID 上面建置 LVM
我们现在的练习机上面,还没有分割的容量应该有 8G 才对。 现在,请以 1.5G (1500M) 为单位,切割出 5 个分割槽, 分割完毕之后,就假设有 5 颗磁盘的意思。 将这五颗磁盘汇整成为一个软体磁盘阵列,名称就为 /dev/md0,使用 raid 5,且没有 spare disk。 然后将整个 /dev/md0 制作成为一个 PV,然后建立名为 raidvg 的 VG 以及 raidlv 的 LV。 最终这个 LV 应该会有 6G 左右的容量才对喔 ( 1.5G * (5-1) = 6G )
完成基础分割以建立假想的 5 颗实际不同的磁盘后,再来组成磁盘阵列才会有意义! 然后开始处理软件磁盘阵列与 LVM 吧!
创建 RAID 5 的软件磁盘阵列,使用到全部的 5 颗分槽:
[root@localhost ~]# mdadm --create /dev/md0 --level=5 --raid-devices=5 --chunk=256K /dev/vda{4..8}mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started. [root@localhost ~]# cat /proc/mdstatPersonalities : [raid6] [raid5] [raid4] md0 : active raid5 vda8[5] vda7[3] vda6[2] vda5[1] vda4[0] 6135808 blocks super 1.2 level 5, 256k chunk, algorithm 2 [5/4] [UUUU_] [=================>...] recovery = 88.2% (1354368/1533952) finish=0.0min speed=52091K/sec [root@localhost ~]# mdadm --detail /dev/md0/dev/md0: Version : 1.2 Creation Time : Mon Jun 8 21:25:41 2020 Raid Level : raid5 Array Size : 6135808 (5.85 GiB 6.28 GB) Used Dev Size : 1533952 (1498.00 MiB 1570.77 MB) Raid Devices : 5 Total Devices : 5 Persistence : Superblock is persistent Update Time : Mon Jun 8 21:26:11 2020 State : clean Active Devices : 5 Working Devices : 5 Failed Devices : 0 Spare Devices : 0 Layout : left-symmetric Chunk Size : 256K Consistency Policy : resync Name : station200.centos:0 (local to host station200.centos) UUID : 7de522d6:77da5653:2dfe5d51:e0f345b8 Events : 18 Number Major Minor RaidDevice State 0 252 4 0 active sync /dev/vda4 1 252 5 1 active sync /dev/vda5 2 252 6 2 active sync /dev/vda6 3 252 7 3 active sync /dev/vda7 5 252 8 4 active sync /dev/vda8建立 PV 以及建立 raidvg 的流程:
[root@localhost ~]# pvcreate /dev/md0 Physical volume "/dev/md0" successfully created. [root@localhost ~]# vgcreate raidvg /dev/md0 Volume group "raidvg" successfully created [root@localhost ~]# vgdisplay raidvg --- Volume group --- VG Name raidvg System ID Format lvm2 Metadata Areas 1 Metadata Sequence No 1 VG Access read/write VG Status resizable MAX LV 0 Cur LV 0 Open LV 0 Max PV 0 Cur PV 1 Act PV 1 VG Size <5.85 GiB PE Size 4.00 MiB Total PE 1497 Alloc PE / Size 0 / 0 Free PE / Size 1497 / <5.85 GiB VG UUID 8Q3LIH-ids8-23FL-TyLq-8EYZ-FXoB-9xV3wd
最终建立需要的 /dev/raidvg/raidlv 装置
[root@localhost ~]# lvcreate -l 1497 -n raidlv raidvg[root@localhost ~]# lvscan ACTIVE '/dev/centos/root' [12.00 GiB] inherit ACTIVE '/dev/centos/home' [3.00 GiB] inherit ACTIVE '/dev/centos/swap' [2.00 GiB] inherit ACTIVE '/dev/raidvg/raidlv' [<5.85 GiB] inherit [root@localhost ~]# lvdisplay /dev/raidvg/raidlv --- Logical volume --- LV Path /dev/raidvg/raidlv LV Name raidlv VG Name raidvg LV UUID VvS80P-Gfuj-jJQo-5Kgg-oxUI-tVGL-RFStap LV Write Access read/write LV Creation host, time station200.centos, 2020-06-08 21:30:41 +0800 LV Status available # open 0 LV Size <5.85 GiB Current LE 1497 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 4096 Block device 253:3
这样就完成了在 RAID 上面建立 LVM 的功能了! 这个LVM暂时不要使用他,我们在下个小节来玩一些比较有趣的项目!
14.4:特殊的档案系统处理模式
近年来包括自动化布署、虚拟机的盛行等,传统的档案系统容量再大,也无法持续提供大量的本地端容量,即使已经使用了LVM。 因此,就有很多计划在处理磁盘与档案系统对应的机制,其中两个很有趣的计划,一个是 Stratis ,另一个则是 VDO 机制, 这两个东西都可以仔细瞧瞧,挺有趣的!
14.4.1:使用 stratis 卷轴管理文件系统 ( VMF)
目前的本地存储设备与档案系统的应用中,包括了 device mapper (dm), LVM, RAID, Multipath, XFS 等等机制, 这些机制各有各的好处。 不过,还是经常需要进行档案系统分割、格式化等行为。 为了方便用户的应用,于是有了 stratis 这个机制的产生。
Stratis 透过卷轴管理文件系统的概念 (volume managing filesystem, VMF) ,简单的将整个设备、文件系统分为几个小阶层,有点类似底下的图标:
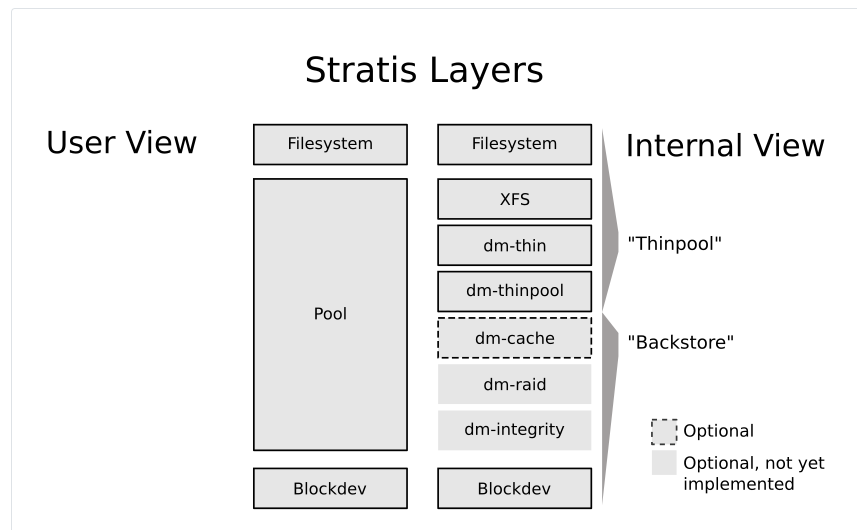
简单的来说,可以简化为底下的样式:

blockdev: 区块装置,除了磁盘之外,也可以是 LVM 喔!
pool: 储存池,可以自由配置装置与档案系统,是一个很抽象的管理层
filesystem: 文件系统,可以直接丢给系统使用于文件管理!
简单的来说,stratis 大致应用了目前的LVM 与XFS 机制,stratis 提供了一个名为存储池 (pool) 的概念,其实就有点类似LVM里面的 VG 的概念, 然后,你可以简单的将任何的区块装置 (传统磁盘、SSD、插卡式磁盘、iSCSI、LVM等) 加入这个储存池,然后在直接挂载到目录树底下, 就可以直接应用了。 此外,由于挂载时的档案系统是在用户层,因此,可以随便你设定容量为多少,即使该容量目前并不存在这么大。
stratis 的管理:通过 stratisd 服务
要达成 stratis 的功能,你的系统得要安装 stratisd 服务才行。 同时,如果想要管理 stratisd 的话,就得要安装 stratis-cli 软件才行! 先来安装软件后,启动该项目吧:
[root@localhost ~]# yum install stratisd stratis-cli[root@localhost ~]# systemctl start stratisd[root@localhost ~]# systemctl enable stratisd
简单的依据'安装'、'启动'、'开机启动'的口诀来处理即可! 不过因为 stratis 并不是网络服务,而是本机的存储系统, 因此不需要防火墙啰! 很快速的就处理好 stratisd 服务。
建立观察存储池: 通过 stratis 指令处理
服务启动之后,接下来就可以直接建立存储池 (pool) 与设备 (blockdev) 之间的关系! 我们在之前的练习里面, 建立过 /dev/raidvg/raidlv 与 /dev/vda9 这两个剩余的装置,现在,先将 raidlv 加入到名为 vbirdpool 的储存池去, 看看情况会如何。 记得,我们先使用 stratis [tab][tab] 看看有什么选项可以利用喔!
[root@localhost ~]# stratis [tab][tab]blockdev daemon filesystem --help pool --version
很明显的看到了 blockdev, filesystem, pool 这三个关键词! 所以,想要建立存储池的话,当然就使用 pool 这个指令即可!
[root@localhost ~]# stratis pool create vbirdpool /dev/raidvg/raidlv[root@localhost ~]# stratis pool listName Total Physical Size Total Physical Used vbirdpool 5.85 GiB 52 MiB# 所以有個 vbirdpool 的儲存池,裡面實際有 5.8G,用掉了 52M 容量了。[root@localhost ~]# stratis blockdev listPool Name Device Node Physical Size State Tier vbirdpool /dev/raidvg/raidlv 5.85 GiB InUse Data# 所有 vbirdpool 實際上用到 /dev/raidvg/raidlv 這個裝置,且用於資料儲存 (Data)
stratis 比较特别的地方是,我们可以持续加进 blockdev 装置,不过无法移出 blockdev! 希望未来可以提供移除blockdev的功能。 那加入的 block 设备有什么限制呢? 让我们将不到 1G 的 /dev/vda9 丢进去 vbirdpool 看看就知道了:
[root@localhost ~]# stratis pool add-data vbirdpool /dev/vda9Execution failure caused by: ERROR: /dev/vda9 too small, minimum 1073741824 bytes
因为我们的练习机档案容量较小,所以 /dev/vda9 不够大于 1G 以上,导致增加失败! 由错误讯息就能知道, stratis 的限制就是需要大于 1G 以上的区块设备, 才能够加入到我们的存储池喔! 那怎么练习加入额外的装置呢? 没关系,我们还有个centos的 VG 可以使用! 现在让我们建立 /dev/centos/lvm 这个 1.5G 的装置,然后再加入 vbirdpool 一下!
[root@localhost ~]# lvcreate -L 1.5G -n lvm centos[root@localhost ~]# lvscan ACTIVE '/dev/centos/root' [12.00 GiB] inherit ACTIVE '/dev/centos/home' [3.00 GiB] inherit ACTIVE '/dev/centos/swap' [2.00 GiB] inherit ACTIVE '/dev/centos/lvm' [1.50 GiB] inherit ACTIVE '/dev/raidvg/raidlv' [<5.85 GiB] inherit [root@localhost ~]# stratis pool add-data vbirdpool /dev/centos/lvm[root@localhost ~]# stratis pool listName Total Physical Size Total Physical Used vbirdpool 7.35 GiB 56 MiB [root@localhost ~]# stratis blockdev listPool Name Device Node Physical Size State Tier vbirdpool /dev/centos/lvm 1.50 GiB InUse Data vbirdpool /dev/raidvg/raidlv 5.85 GiB InUse Data
你会发现到 Tier 这个地方,这里很有趣喔! 基本上 Tier 大致上有两种情境,一个是用于传统资料存放,就是' Data '的效果, 如果你有比较快速、较小的 SSD / NVMe 等设备,可以将他设定为快取 (cache) 喔! 如此一来,你甚至可能会有好几个 T 的快取! 而且不用任何奇怪的设定,直接加入成为快取即可! 相当有趣吧! 底下为练习机不存在的指令,看看就好:
# 假設 /dev/vdc 為 SSD,可加入成為快取的功能為:[root@localhost ~]# stratis pool add-cache vbirdpool /dev/vdc# 因為系統不存在 /dev/vdc 啦!這裡單純給大家瞧瞧!
建立观察与挂载文件系统: 通过 stratis 指令处理
所有以 stratisd 创建的文件系统,其设备文件名默认都会以下面的方式存在:
说明:/stratis/存储池名称/文件系统名称
范例:/stratis/vbirdpool/fs1
如上,我们先配置一个 fs1 的文件系统来使用看看:
[root@localhost ~]# stratis filesystem create vbirdpool fs1[root@localhost ~]# stratis filesystem listPool Name Name Used Created Device UUID vbirdpool fs1 545 MiB Jun 09 2020 12:00 /stratis/vbirdpool/fs1 7430f67c671e4c5c9e98a77ccbbc8574
这时装置名称就建立起来了! 你可以很明显的看到该装置! 只是,建议不要使用设备来进行挂载,如果需要挂载, 就用 UUID 吧! 查询 UUID 的方法可以这样做:
[root@localhost ~]# blkid /stratis/vbirdpool/*/stratis/vbirdpool/fs1: UUID="7430f67c-671e-4c5c-9e98-a77ccbbc8574" TYPE="xfs" [root@localhost ~]# mkdir /srv/pool1[root@localhost ~]# mount UUID="7430f67c-671e-4c5c-9e98-a77ccbbc8574" /srv/pool1[root@localhost ~]# df -Th /srv/pool1檔案系統 .... 類型 容量 已用 可用 已用% 掛載點 /dev/mapper/stratis-1-6e6ad....bbc8574 xfs 1.0T 7.2G 1017G 1% /srv/pool1
这样就可以挂载使用了! 不过要注意的是,使用 df 去显示时,档案容量会显示为 1TB,那个是错误的显示容量! 略过不要理会! 要查阅时,请使用『 stratis filesystem list 』去查看才是对的!
开机就挂载的方式
虽然 stratis 的档案系统可以直接将挂载项目写入到 /etc/fstab 里面,不过要注意的是,这些档案系统毕竟是经由 stratisd 管理的, 但是本机档案系统的挂载其实是在启动 stratisd 之前,因此如果没有加上特别的注意,该挂载在开机过程当中是会失败的! 特别留意这个问题!
编辑 /etc/fstab,加入底下这一行:
UUID="7430f67c-671e-4c5c-9e98-a77ccbbc8574" /srv/pool1 xfs defaults,x-systemd.requires=stratisd.service 0 0
卸载既有的挂载后, mount -a 测试,测试成功之后,记得 reboot 看看有没有生效!
[root@localhost ~]# umount /srv/pool1[root@localhost ~]# mount -a[root@localhost ~]# reboot
移除 stratis 的方法
要移除 stratis 的话,就跟移除一般档案系统类似,从 /etc/fstab 的编辑以及卸载后,再以 stratis 删除掉档案系统与储存池即可。
将 /etc/fstab 新增那一行删除或注解:
将挂载于 /srv/pool1 的装置卸载
开始删除 fs1
开始删除 vbirdpool
停止 stratisd 服务
[root@localhost ~]# vim /etc/fstab#UUID="7430f67c-671e-4c5c-9e98-a77ccbbc8574" /srv/pool1 xfs defaults,x-systemd.requires=stratisd.service 0 0[root@localhost ~]# umount /srv/pool1[root@localhost ~]# stratis filesystem destroy vbirdpool fs1[root@localhost ~]# stratis pool destroy vbirdpool[root@localhost ~]# systemctl stop stratisd.service[root@localhost ~]# systemctl disable stratisd.service
14.4.2:使用于虚拟机磁盘应用的 VDO 机制
身为现代人,你应该、绝对听过所谓的虚拟化,我们现在上课使用的系统就是虚拟机啊! 使用到虚拟机的原因,当然是由于硬件资源大幅提升的缘故, 因此一部主机可以做成虚拟机的本地(host),然后再将资源如CPU、内存、磁盘、网络等分享给虚拟机(VM)使用,最后在VM上面安装好操作系统(guest)之后,就可以提供给客户进行操作了。
许多硬件资源都可以透过共享。 如4核8绪的主机,可以提供给8台2核心的虚拟机(VM),虚拟机的总CPU个数(16)超出实体CPU(4), 也是没问题的! 所有的虚拟机可以轮流共享实体CPU核心。 同理,内存也一样,甚至如果具有相同内容的VM群,其共有的记忆资源还能仅保留共有的一份。
不过虚拟机的磁盘怎么来? 一般来说,虚拟机的磁盘大多使用大型档案来提供,当然也能使用 LVM! 不过,当 VM 的量很大的时候, 使用大型档案并通过快照复制的效果,会比较好一些,不用透过持续的 device mapper (dm) 去管理,耗用的资源较少。 只是,你得要自己手动进行快照、自己进行压缩与各项系统处置,管理方面比较不方便。
虚拟数据优化系统 (Virtual Data Optimizer, VOD) 就是为了处理虚拟机的磁盘设备而设计的! VDO可以让你的资料直接在VDO的挂载点里面, 直接通过VDO系统的管理,自己进行资料同步、资料压缩。 此外,你的1TB实体磁盘,也能透过VDO的功能,假装成为5TB的容量, 因为VDO会进行压缩等行为,也就让你的系统可以进行更多档案的储存!

VDO 的元件与使用
VDO 的使用需要通过 vdo 服务以及 kmod-kvdo 模块的支持,因此得要安装这两个软件才行,同时得要启动 vdo 服务喔!
[root@localhost ~]# yum install vdo kmod-kvdo[root@localhost ~]# systemctl restart vdo[root@localhost ~]# systemctl enable vdo
接下来 vdo 的使用跟 LVM 真的很有点类似~透过 vdo 指令来建立起 vdo 的卷轴装置,这些设备都会以 /dev/mapper/XXX 的设备名称存在, 现在,我们将刚刚释出的 /dev/raidvg/raidlv 这个装置丢给 VDO 使用 (记得一下,VDO 使用的区块装置,其容量至少要大于 5G 才好! ), 并且创建名为 myvdo 的设备,同时该磁盘容量假设为原本两倍的 10G 容量,可以这样做:
[root@localhost ~]# vdo create --name=myvdo --vdoLogicalSize=10G \> --device=/dev/raidvg/raidlv --deduplication enabled --compression enabled[root@localhost ~]# vdo status --name myvdoVDO status: Date: '2020-06-09 14:07:06+08:00' Node: station200.centos Kernel module: Loaded: true Name: kvdo Version information: kvdo version: 6.2.1.138 Configuration: File: /etc/vdoconf.yml Last modified: '2020-06-09 14:05:38' VDOs: myvdo: Acknowledgement threads: 1 Activate: enabled Bio rotation interval: 64 Bio submission threads: 4 Block map cache size: 128M Block map period: 16380 Block size: 4096 CPU-work threads: 2 Compression: enabled Configured write policy: auto Deduplication: enabled Device mapper status: 0 20971520 vdo /dev/dm-4 normal - online online 1008994 1532928 ...... [root@localhost ~]# vdostats --human-readableDevice Size Used Available Use% Space saving% /dev/mapper/myvdo 5.8G 3.8G 2.0G 65% N/A
因为 VDO 会进行许多的动作,因此一开始就会花费 3.8G 的容量,剩余的容量可能只剩下 2G 而已! 因此,要使用 VDO 时, 设备的容量还是大一些比较妥当。 我们这里只进行测试啦! 接下来,请将这个装置挂载使用吧。
开始格式化:
[root@localhost ~]# mkfs.xfs /dev/mapper/myvdo[root@localhost ~]# vdostats --human-readableDevice Size Used Available Use% Space saving% /dev/mapper/myvdo 5.8G 3.8G 2.0G 65% 99%
开始测试挂载
[root@localhost ~]# vim /etc/fstab/dev/mapper/myvdo /srv/vdo xfs defaults,x-systemd.requires=vdo.service 0 0 [root@localhost ~]# mkdir /srv/vdo[root@localhost ~]# mount -a[root@localhost ~]# mount | grep vdo/dev/mapper/myvdo on /srv/vdo type xfs (rw,....x-systemd.requires=vdo.service) [root@localhost ~]# reboot
建置完毕之后,建议立刻 reboot 测试一下 /etc/fstab 里面的设定是否为正常喔!
VDO 文件运作的三个阶段
VDO 在进行文件的处理时,主要会有三个阶段 ( 3 phases ),流程如下:
暂存阶段(zero-block elimination):一开始进行类似复制的行为时,VDO会依据档案的内容,先占用一个不存在的容量,只是先处理中介资料(metadata)的写入,有点类似只写入superblock信息而已的概念。 让系统以为确实存在该档案,但事实上,该档案并没有完全写入,甚至可能不用写入! 资料是否写入到实际的档案系统中,得要看下个阶段的结果而定。
重复性数据测试阶段 (deduplication elimination):VDO 会分析要写入的这个文件的特性与内容,当 VDO 发现到这个档案已经存在系统中, 那么该数据就不会实际写入到档案系统,而是通过一个「指向 (point) 』的方式,以类似快照的模式来建立该档案,因此同一个档案复制多个备份时, 其实只有第一个建立的档案才会实际存在, 其他的备份都是透过链接到第一个档案去的方式来处理的。
压缩阶段(compression):最终 VDO 通过 LZ4 这个压缩机制以 4KB 区块大小的形式来进行压缩,让档案容量可以降低到更小。
大家要先有个概念,VDO 的重点在于使用于虚拟机中,虚拟机通常使用大型档案作为虚拟机里面的磁盘系统,所以,丢进 VDO 管理的文件系统内的数据, 不应该是一般的档案,而是作为虚拟磁盘的文件才对! 不要搞错使用的方向了。 所以,我们得要先来制作虚拟驱动器的文件才行! 如下所示, 我们先来建立一个大型的文件 (虽然不是专门用来进行磁盘系统的)。
[root@localhost ~]# df -Th /檔案系統 類型 容量 已用 可用 已用% 掛載點 /dev/mapper/centos-root xfs 12G 6.2G 5.9G 51% / [root@localhost ~]# tar -cf /vmdisk.img /etc /home /root[root@localhost ~]# ll -h /vmdisk.img-rw-r--r--. 1 root root 346M 6月 9 15:14 /vmdisk.img
这样就有一个没有压缩的,大约 346M 的大型档案! 开始复制的举动,将此文件复制到 /srv/vdo 目录去:
[root@localhost ~]# vdostats --human-readableDevice Size Used Available Use% Space saving% /dev/mapper/myvdo 5.8G 3.8G 2.0G 65% 98% [root@localhost ~]# cp /vmdisk.img /srv/vdo[root@localhost ~]# vdostats --human-readableDevice Size Used Available Use% Space saving% /dev/mapper/myvdo 5.8G 4.1G 1.7G 70% 71% [root@localhost ~]# cp /vmdisk.img /srv/vdo/vmdisk2.img[root@localhost ~]# vdostats --human-readableDevice Size Used Available Use% Space saving% /dev/mapper/myvdo 5.8G 4.1G 1.7G 70% 71% [root@localhost ~]# cp /vmdisk.img /srv/vdo/vmdisk3.img[root@localhost ~]# cp /vmdisk.img /srv/vdo/vmdisk4.img[root@localhost ~]# vdostats --human-readableDevice Size Used Available Use% Space saving% /dev/mapper/myvdo 5.8G 4.1G 1.7G 70% 78% [root@localhost ~]# df -Th /srv/vdo檔案系統 類型 容量 已用 可用 已用% 掛載點 /dev/mapper/myvdo xfs 10G 1.5G 8.6G 15% /srv/vdo
你可以发现,虽然单一档案有3xx MB的容量,但是整体VDO还是只有消耗(4.1G-3.8G = 0.3G)左右的容量,使用传统档案系统的 df 来看,却已经使用掉 1.5G 了! 这就可以节省非常多的容量喔!
14.5:简易磁盘配额 (Quota)
Filesystem Quota 可以使用于'公平的'使用文件系统。 虽然现今磁盘容量越来越大,但是在某些特别的情境中,为了管制使用者乱用档案系统,还是有必要管理一下 quota 用量的。
14.5.1:Quota 的管理与限制
基本上,要能使用 Quota ,你需要有底下的支援:
Linux 核心支持:除非你自己编译核心,又不小心取消,否则目前默认核心都有支持 Quota 的
启用文件系统支持:虽然EXT家族与XFS文件系统均支持Quota,但是你还是得要在挂载时启用支持才行。
而一般 Quota 针对的管理对象是:
可针对用户( 但不包含 root)
可针对群组
EXT家族仅可针对整个档案系统,XFS可以针对某个目录进行 Quota 管理
那可以限制的文件系统数据是:
可限制档案容量,其实就是针对 Filesystem 的 block 做限制
可限制文件数量,其实就是针对 Filesystem 的 inode 做限制 (一个文件会占用 1 个 inode 之故)
至于限制的数值与数据,又可以分为底下几个:
Soft 限制值:仅为软性限制,可以突破该限制值,但超过 soft 数值后,就会产生『宽限时间 (grace time)』
Hard 限制值:就是严格限制,一定无法超过此数值
Grace time:宽限时间,通常为 7 天或 14 天,只有在用量超过 soft 数值后才会产生,若用户无任何动作,则 grace time 倒数完毕后, soft 数值会成为 hard 数值,因此档案系统就会被锁死。
所谓的'档案系统锁死'的意思,指的是使用者将无法新增/删除档案系统的任何资料,所以就得要借由系统管理员来处理了!
由于 Quota 需要文件系统的支持,因此管理员请务必在 fstab 文件中增加下面的设置:
uquota/usrquota/quota:启动用户账号 quota 管理
gquota/grpquota:启动群组 quota 管理
pquota/prjquota:启用单一目录管理,但不可与 gquota 共用(本章不实做)
在 xfs 文件系统中,由于 quota 是'文件系统内部纪录管理'的,不像 EXT 家族是通过外部管理文件处理, 因此设定好参数后,一定要卸载再挂载 (umount --> mount),不可以使用 remount 来处理。
在测试机的系统中, /home 为 xfs 文件系统,请在配置文件中加入 usrquota, grpquota 的挂载参数;
能否直接卸载 /home 再挂载? 为什么? 如何进行卸载再挂载的动作?
如何观察已经挂载的档案系统参数?
14.5.2:xfs 档案系统的 quota 实做
一般来说,Quota 的实做大多就是观察、设定、报告等项目,底下依序说明:
XFS 文件系统的 Quota 状态检查
xfs 文件系统的 quota 实做都是通过 xfs_quota 此指令,这个指令在观察方面的语法如下:
[root@www ~]# xfs_quota -x -c "指令" [掛載點]選項與參數: -x :專家模式,後續才能夠加入 -c 的指令參數喔! -c :後面加的就是指令,這個小節我們先來談談數據回報的指令 指令: print :單純的列出目前主機內的檔案系統參數等資料 df :與原本的 df 一樣的功能,可以加上 -b (block) -i (inode) -h (加上單位) 等 report:列出目前的 quota 項目,有 -ugr (user/group/project) 及 -bi 等資料 state :說明目前支援 quota 的檔案系統的資訊,有沒有起動相關項目等
例如列出当前支持 quota 的文件系统观察可以使用:
[root@localhost ~]# xfs_quota -x -c "print"Filesystem Pathname / /dev/mapper/centos-root /srv/vdo /dev/mapper/myvdo /home /dev/mapper/centos-home (uquota, gquota)
如上表,系统就列出了有支持 quota 的载点,之后即可观察 quota 的启动状态:
[root@localhost ~]# xfs_quota -x -c "state"User quota state on /home (/dev/mapper/centos-home) Accounting: ON Enforcement: ON Inode: #1921 (4 blocks, 4 extents)Group quota state on /home (/dev/mapper/centos-home) Accounting: ON Enforcement: ON Inode: #1975 (4 blocks, 3 extents)Project quota state on /home (/dev/mapper/centos-home) Accounting: OFF Enforcement: OFF Inode: N/ABlocks grace time: [7 days]Inodes grace time: [7 days] Realtime Blocks grace time: [7 days]
上表显示的状况为:
针对用户的设定已经开启 quota
针对群组的设定已经开启 quota
针对 Project 的设定并没有开启
Block与Inode的宽限时间均为7天
XFS 文件系统的 Quota 帐号/组使用和设置报告
如果需要详细的列出在该载点底下的所有帐号的 quota 数据,可以使用 report 这个命令项目:
[root@localhost ~]# xfs_quota -x -c "report /home"User quota on /home (/dev/mapper/centos-home) Blocks User ID Used Soft Hard Warn/Grace ---------- -------------------------------------------------- root 0 0 0 00 [--------] student 311776 0 0 00 [--------] Group quota on /home (/dev/mapper/centos-home) Blocks Group ID Used Soft Hard Warn/Grace ---------- -------------------------------------------------- root 0 0 0 00 [--------] student 311776 0 0 00 [--------] [root@localhost ~]# xfs_quota -x -c "report -ubih /home"User quota on /home (/dev/mapper/centos-home) Blocks Inodes User ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace ---------- --------------------------------- --------------------------------- root 8K 0 0 00 [------] 5 0 0 00 [------] student 304.5M 0 0 00 [------] 1.1k 0 0 00 [------]
单纯输入 report 时,系统会列出 user/group 的 block 使用状态,亦即是帐号/群组的容量使用情况,但默认不会输出 inode 的使用状态。 若额外需要 inode 的状态,就可以在 report 后面加上 -i 之类的选项来处理。
XFS 文件系统的 Quota 帐号/组实际设置方式
主要针对用户和组的 Quota 设置方式如下:
[root@localhost ~]# xfs_quota -x -c "limit [-ug] b[soft|hard]=N i[soft|hard]=N name" mount_point[root@localhost ~]# xfs_quota -x -c "timer [-ug] [-bir] Ndays"選項與參數: limit :實際限制的項目,可以針對 user/group 來限制,限制的項目有 bsoft/bhard : block 的 soft/hard 限制值,可以加單位 isoft/ihard : inode 的 soft/hard 限制值 name : 就是用戶/群組的名稱啊! timer :用來設定 grace time 的項目喔,也是可以針對 user/group 以及 block/inode 設定
假设管理员要针对 student 这个帐号设定:可以使用的 /home 容量实际限制为 2G 但超过 1.8G 就予以警告, 简易的设定方式如下:
[root@localhost ~]# xfs_quota -x -c "limit -u bsoft=1800M bhard=2G student" /home[root@localhost ~]# xfs_quota -x -c "report -ubh" /homeUser quota on /home (/dev/mapper/centos-home) Blocks User ID Used Soft Hard Warn/Grace ---------- --------------------------------- root 8K 0 0 00 [------] sysuser1 20K 0 0 00 [------] student 304.5M 1.8G 2G 00 [------]
如果需要取消 student 设置,直接将数值设定为 0 即可!
[root@localhost ~]# xfs_quota -x -c "limit -u bsoft=0 bhard=0 student" /home
创建一个名为 "quotaman" 的用户,该用户的密码设定为 "myPassWord"
观察 quotaman 刚刚建立好账号后的 quota 数值
让 quotaman 的实际容量限制为 200M 而宽限容量限制为 150M 左右,设定完毕请观察是否正确
前往 tty5 终端机,并实际以 quotaman 的身份登入,同时执行『 dd if=/dev/zero of=test.img bs=1M count=160 '这个指令, 检查 quotaman 家目录是否有大型档案? 且该指令执行是否会出错?
回归 root 的身份,再次观察 quotaman 的 quota 报告,是否有出现 grace time 的数据? 为什么?
再次来到 quotaman 的 tty2 终端机,再次使用『 dd if=/dev/zero of=test.img bs=1M count=260 』这个指令, 检查 quotaman 家目录是否有大型档案? 且该指令执行是否会出错?
quotaman 需要如何处理数据后,才能够正常的继续操作系统?
14.6:课后练习操作
上课的课后练习,非作业:
关闭 VDO 这个虚拟机的磁盘优化模块,卸载 /srv/vdo
关闭 raidvg 这个 LVM 的 VG,也关闭 /dev/md0 这个软件磁盘阵列,同时恢复原本的磁盘分割,让系统只剩下 /dev/vda{1,2,3}
创建具有 cache 的 stratis 服务:
分割出 /dev/vda4, /dev/vda5 各 1G 与 1.5G 的容量
让 /dev/vda5 成为名为 mydata 的 stratis 储存池
让 /dev/vda4 成为 mydata 的快取 ( 模拟的,不具备加速功能)
最终建立 myfs1 文件系统
启动 quota 而挂载到 /srv/myfilesystem 目录内。
建立 VDO 设备
将所有其他容量分割给 /dev/vda6
让 /dev/vda6 加入成为名为 myvdo 且逻辑容量具有 10G。
让 myvdo 格式化为 ext4 文件系统,并且启动 quota 及挂载于 /srv/myvdo 目录中
student 在上述两个载点内,都具有 800M/1000M 的 quota 使用限制。
全部设定完毕后,重新开机,看看所有的资料能不能顺利运作!
作业 (不提供学生答案,仅提供教师参考答案)
作业硬盘操作帮助:
开启云端虚拟机前,请务必确认你开启的硬盘是'unit14',否则就会做错题目
若要使用图形界面,请务必使用 student 身份登入,若需要切换身份,再启用终端机处理。
若有简答题需要使用中文,请自行以第一堂课的动作自行处理输入法安装。
每部虚拟机均有独特的网卡地址,请勿使用他人硬盘上传,否则计分为 0 分。
每位同学均有自己的 IP 尾数,请先向老师询问您的 IP 尾数,才可以进行作业上传。
最终上传作业结果,请务必使用 root 身份上传。
进入操作硬盘后,先用 root 身份执行 vbird_book_setup_ip, 执行流程请参考:vbird_book_setup_ip
作业当中,某些部份可能为简答题~若为简答题时,请将答案写入 /home/student/ans.txt 当中,并写好正确题号,方便老师订正答案。 请注意,文件名写错将无法上传!
请使用 root 的身份进行如下实做的任务。 直接在系统上面操作,操作成功即可,上传结果的程序会主动找到你的实做结果。 并请注意,题目是有相依性的,因此请依序进行底下的题目为宜
(20%)请回答下列问题,并将答案写在 /root/ans14.txt 文件内:
RAID0, RAID1, RAID6, RAID10 中 (1)哪一个等级效能最佳 (2)哪些等级才会有容错
承上,若以 8 颗磁盘为例,且都没有 spare disk 的环境下,上述等级各有几颗磁盘容量可用?
承上,以具有容错的磁盘阵列而言,当有一颗磁盘损坏而需更换重建时, 哪些磁盘阵列的重建效能最佳 (资料可直接复制,无须透过重新计算而言)
软体磁盘阵列的 (1)操作指令为何? (2)磁盘阵列档名为何 (3)设定文件档名为何
LVM 的管理中,主要的组成有 PV, VG, LV 等,请问在 LVM 中,资料储存、搬移的最小单位是甚么 (写下英文缩写与全名)
进行分割 (partition) 时,在 (1)GPT 与 (2)MSDOS 的分割表情静下,(a)Linux LVM 与 (b)Linux software RAID 的 system ID 各为何? (注:可以使用 fdisk /dev/vda 去查询 system ID 列表,不要写入分割表即可测试)
进行磁盘配额 (filesystem quota) 时,挂载参数要加上哪两个文件系统参数 (以 XFS 文件系统为例) 才能够支持 quota
承上,磁盘配额限制【磁盘使用容量】与【可用档案数量】时,分别是限制什么项目?
若需要可以弹性的且不用配置容量的方式来管理档案系统,可以使用 stratisd 或 vdo 服务呢? 写下服务名称。
VDO 可针对虚拟机的虚拟磁盘机进行优化,VDO 对写入的数据会进行三个阶段的运作,分别是那三个阶段?
(20%)弹性化管理文件系统 :
且在这个LV(1)会用完VG的所有剩余容量,也就是说,该LV所在的VG不要有剩下的容量在,若容量不足,也请自行设法处理(自己想办法再切出需要的容量,且容量范围误差不要超过10%即可,亦即900M~1100M之间均可接受! )
在这个LV上面的档案系统须同步处理容量。
(15%)在目前的系统中,找到一个名为 hehe 的 LV ,将此 LV 的容量设定改成 1GB,且:
(5%)请让 /home 目录所在的文件系统具有 quota 的 user/group 磁盘容量配额限制的功能。 请注意,这一个项目与最后一题脚本建立有关,处理前,最好先注销图形界面,在tty2使用root直接登录,否则/home可能无法卸载。
(15%)综合管理档案系统
VG 名称请取为 govg 容量请自定义,但是 PE 需要具有 8MB 的大小 (参考底下的说明来指定喔)
LV 名称请取为 golv,将全部的容量都给这个 LV。
请建立 7 个 1GB 的分割槽,且 system ID 请设定为 RAID 的样式
将上列磁盘分割槽用来建立 /dev/md0 为名的磁盘阵列,等级为 RAID6,无须 spare disk,chunk size 请指定为 1M
以 /dev/md0 为磁盘来源,并依据底下的说明,重新建立一个 LVM 的设备 ( 无须进行格式化与挂载)
(15%)建立 stratis 的 thin pool 管理机制:
找到名为centos的 VG,将其所有剩余容量建立一个名为 stratis 的 LV,亦即最终会有 /dev/centos/stratis 的设备文件名存在。
将上述的LV装置,加入 stratis 的名为 mypool 的储存池
建立名为 myfilesystem 的文件系统名称,然后开机后自动挂载到 /data/goodfile/ 目录下。
(15%)创建 VDO 管理虚拟化磁盘系统的机制:
将 /dev/govg/golv 加入 VDO 的管理机制下,且建立名为 myvm 的 vdo volume name,同时给予 15G 的逻辑容量。 (由于涉及核心模块,所以可能需要全系统更新一次,或者安装了 vdo 相关软件后,必需要重新开机使用新核心才可以继续。
格式化成为 xfs 文件系统,并且开机后会自动挂载到 /data/goodvm/ 目录下
(15%)建立一个名为 /root/myaccount.sh 的大量建立帐号的脚本,这个脚本执行后,可以完成底下的事件
会建立一个名为 mygroup 的群组
会依据默认环境建立 30 个帐号,账号名称为 myuser01 ~ myuser30 共 30 个账号,且这些帐号会支持 mygroup 为次要群组
每个人的密码会使用【 openssl rand -base64 6 】随机取得一个 8 个字元的密码, 并且这个密码会被记录到 /root/account.password 档案中,每一行一个,且每一行的格式有点像【myuser01:AABBCCDD】
每个账号默认都会有 200MB/250MB 的 soft/hard 磁盘配额限制。
作业结果传输:请以 root 的身份执行 vbird_book_check_unit 指令上传操作结果。 正常执行完毕的结果应会出现【XXXXXX_aa:bb:cc:dd:ee:ff_unitNN】字样。 若需要查阅自己上传资料的时间, 请在操作系统上面使用浏览器查询: http://192.168.251.254 检查相对应的课程档案。 相关流程请参考: vbird_book_check_unit


评论专区