
深度强化学习:Pongs from Pixels
这是有关“强化学习”(RL)的早就应该发表的博客文章。RL很热!您可能已经注意到,计算机现在可以自动学习玩ATARI游戏(从原始游戏像素开始!),它们在Go上击败了世界冠军,模拟的四足动物正在学习奔跑和跳跃,机器人正在学习如何执行复杂的操纵任务,违反显式编程。事实证明,所有这些进展都属于RL研究的范畴。在过去的一年中,我自己也对RL产生了兴趣:我研究了Richard Sutton的书,阅读了David Silver的课程,观看了John Schulmann的演讲,写了一篇夏季,用Javascript编写的RL库在 DeepDind小组的DeepMind实习,最近又通过设计/开发新的RL基准测试工具包OpenAI Gym进行了一些培训。因此,我肯定已经从事了至少一年,但直到现在我还没有写一篇关于RL为什么重要,它是什么意思,它是如何发展的以及它可能在哪里的简短文章。去。

反思RL近期进展的性质很有趣。我大致想考虑阻碍AI的四个独立因素:
计算(显而易见的一个:摩尔定律,GPU,ASIC),
数据(一种很好的形式,而不仅仅是Internet上的某个地方,例如ImageNet),
算法(研究和思路,例如backprop,CNN,LSTM)和
基础架构(您之下的软件-Linux,TCP / IP,Git,ROS,PR2,AWS,AMT,TensorFlow等)。
与“计算机视觉”中发生的情况类似,RL的进步并没有像您可能会被新的令人惊奇的想法合理地假设那样推动。在《计算机视觉》中,2012年的AlexNet主要是1990年代ConvNets的放大版本(更深更宽)。同样,2013年发布的ATARI深度Q学习论文是一种标准算法(带函数逼近的Q学习,您可以在Sutton 1998的标准RL书中找到)的实现,其中函数逼近器恰好是ConvNet。AlphaGo将策略梯度与蒙特卡洛树搜索(MCTS)结合使用-这些也是标准组件。当然,要使其运作,需要大量的技巧和耐心,并且在旧算法的基础上已经开发出了许多巧妙的调整,
现在回到RL。每当看起来神奇的东西和它的内幕多么简单之间存在脱节时,我都会感到非常恼火,并且真的想写一篇博客文章。在这种情况下,我见过很多人,他们不敢相信我们可以通过一种算法,像素和从头开始使用一种算法来自动学习玩人类级别的大多数ATARI游戏-太神奇了,我去过那里我!但从根本上讲,我们使用的方法实际上也非常愚蠢(尽管我知道回想起来很容易得出这样的主张)。无论如何,我想带您了解Policy Gradients(PG),这是我们目前最喜欢的解决RL问题的默认选择。如果您来自RL以外的地方,您可能会很好奇为什么我不介绍DQN,它是一种替代的且知名度更高的RL算法,已被RL广泛使用ATARI游戏纸。事实证明,Q学习不是一个很好的算法(您可以说DQN在2013年是如此(好吧,我在开玩笑的是50%))。实际上,大多数人都喜欢使用Policy Gradients,包括原始DQN论文的作者,他们在调优后显示 Policy Gradients比Q Learning更好地工作。首选PG,因为它是端到端的:有一个明确的政策和一种有原则的方法可以直接优化预期的回报。无论如何,作为一个正在运行的示例,我们将学习使用PG,从头开始,从像素开始,通过深度神经网络来玩ATARI游戏(Pong!),整个过程是仅使用numpy作为依赖项的130行Python(要点链接)。让我们开始吧。
像素球

Pong的游戏是简单的RL任务的一个很好的例子。在ATARI 2600版本中,我们将使用您作为球拍之一(另一个由不错的AI控制),并且您必须将球弹回另一位球员(我真的不必解释Pong,对吗? )。在低端,游戏的工作方式如下:我们收到一个图像帧(一个210x160x3字节数组(从0到255的整数,给出像素值)),然后我们决定是否要向上或向下移动操纵杆(即二进制选择) )。每次选择后,游戏模拟器都会执行动作并给予我们奖励:如果球超过了对手,则为+1奖励;如果我们错过球,则为-1奖励;否则为0。当然,我们的目标是移动球拍,以便获得很多回报。
在进行解决方案时,请记住,我们将对Pong做出很少的假设,因为我们暗中并不真正关心Pong。我们关心复杂的高维问题,例如机器人操纵,组装和导航。Pong只是一个有趣的玩具测试用例,我们在研究如何编写非常通用的AI系统(可以一天完成任意有用的任务)的过程中使用。
策略梯度:运行策略一段时间。看看哪些行为导致了高额回报。增加他们的可能性。
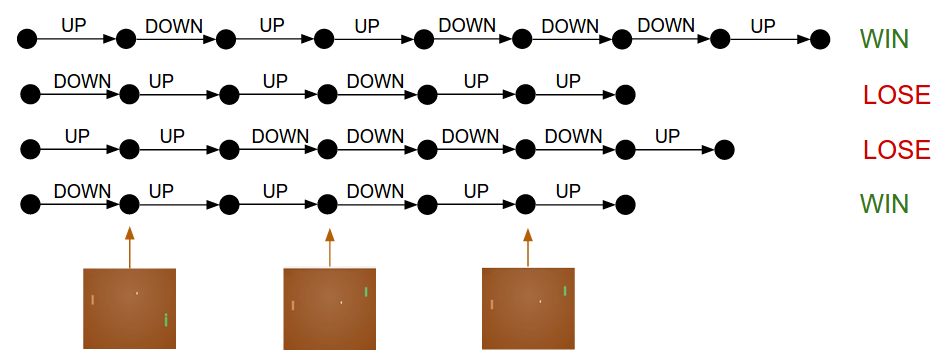
如果您认为通过此过程,您将开始发现一些有趣的属性。例如,如果我们在第50帧采取了良好的动作(正确地将球弹回),但随后在第150帧错过了球怎么办?如果现在将每个动作都标记为不良(因为我们输了),那会不会阻碍第50帧的正确弹跳?您是对的-的确如此。但是,当您考虑成千上万的游戏过程时,正确地进行第一次跳出会让您更有可能赢得胜利,因此平均而言,对于正确的跳出和策略,您会看到比消极更新更积极的信息最终会做正确的事。

我希望与RL的联系清楚。我们的政策网络为我们提供了行动样本,其中一些样本的效果比其他样本更好(根据优势函数判断)。这个小小的数学运算告诉我们,更改策略参数的方法是进行一些部署,采用采样操作的梯度,将其乘以分数并添加所有内容,这就是我们上面所做的。有关更详尽的推论和讨论,我建议约翰·舒尔曼(John Schulman)的演讲。
学习。好了,我们已经开发出了针对梯度变化的直觉,并看到了其推导的草图。我在130行Python脚本中实现了整个方法,该脚本使用OpenAI Gym的ATARI 2600 Pong。我使用RMSProp在10集的批次中训练了一个具有200个隐藏层单元的2层策略网络(每集是几十个游戏,因为每个玩家的游戏得分都达到21)。我没有对超参数进行过多的调整,而是在(慢速)的Macbook上进行了实验,但是经过3个晚上的培训,我最终制定了比AI播放器更好的策略。总集数约为8,000,因此该算法大约播放了200,000 Pong游戏(不是很多!),总共进行了约800次更新。朋友告诉我,如果您使用ConvNets在GPU上训练几天,则可以更频繁地击败AI播放器,并且如果您还仔细优化了超参数,那么您也可以始终称霸AI播放器(即,赢得每场比赛)。然而,
博学的特工(绿色,右)与硬编码的AI对手(左)对峙。
学到的重量。我们还可以看一下学习到的权重。由于进行了预处理,因此每个输入都是80x80的差异图像(当前帧减去最后一帧)。现在,我们可以将W1,将它们拉伸到80x80并可视化。以下是网格中40个(200个中的)神经元的集合。白色像素为正权重,黑色像素为负权重。请注意,几个神经元已调整到弹跳球的特定痕迹,并沿直线交替黑白编码。球只能位于单个位置,因此这些神经元是多任务处理的,将沿着该线“射击”球的多个位置。黑白交替很有趣,因为当球沿着轨迹移动时,神经元的活动将以正弦波的形式波动,并且由于ReLU,它将沿轨迹的离散位置分开“发射”。图像中有些噪点,我认为如果使用L2正则化可以消除这种噪点。

什么都没发生
这样就可以了-我们从使用Policy Gradients的原始像素开始学习Pong,并且效果很好。该方法是一种花哨的猜想检查形式,其中“猜测”是指从我们当前政策中推出的样本,而“检查”是指鼓励采取可导致良好结果的行动。取一些细节,这代表了我们当前如何处理强化学习问题的最新技术。我们可以学习这些行为,这给人留下了深刻的印象,但是如果您直观地理解了算法,并且知道它是如何工作的,那么您至少应该会有些失望。特别是它怎么不起作用?
将其与人类学习打乒乓球的方式进行比较。您向他们展示游戏并说出类似的话:“您控制着球拍,您可以上下移动球拍,而您的任务是将球反弹到AI所控制的另一位球员身上,”重新设置并准备出发。请注意其中的一些区别:
在实际环境中,我们通常以某种方式(例如上面的英语)传达任务,但是在标准的RL问题中,您假设必须通过环境交互来发现任意奖励函数。可以说,如果一个人参加了Pong游戏,但是不了解奖励函数(的确如此,特别是如果奖励函数是一些静态但随机的函数),那么该人将很难学习如何做,但是政策梯度将变得无关紧要,并且效果可能会更好。同样,如果我们拍摄帧并随机排列像素,那么人类可能会失败,但是我们的Policy Gradient解决方案甚至无法分辨出差异(如果它使用的是完全连接的网络,如此处所述)。
人类会带来大量的先验知识,例如直观的物理学(球反弹,不可能传送,不可能突然停止,保持恒定的速度等),以及直观的心理学(AI对手“想”,那么很可能会遵循明显的趋向球等策略)。您还了解了“控制”板的概念,并且它可以响应您的UP / DOWN键命令。相比之下,我们的算法从头开始,这同时令人印象深刻(因为它有效)和令人沮丧(因为我们缺乏如何避免这种现象的具体想法)。
策略梯度是一种蛮力解决方案,最终可以找到正确的操作并将其内化到策略中。人类建立一个丰富的抽象模型并在其中计划。在Pong中,我可以断定对手的速度非常慢,因此以较高的垂直速度弹跳球可能是一个不错的策略,这会使对手无法及时赶上球。但是,似乎我们最终还是将良好的解决方案“内在化”,使之看起来更像是一种反应性的肌肉记忆政策。例如,如果您正在学习一个新的汽车任务(例如,用变速杆驾驶汽车?),您通常会在一开始就觉得自己在想很多,但最终该任务变得自动而漫不经心。
策略梯度人员必须实际体验到积极的回报,并且要经常体验它,以便最终并缓慢地将政策参数转移到重复的获得高回报的举动上。利用我们的抽象模型,人们可以找出可能给出奖励的东西,而无需实际经历过奖励或不奖励的过渡。在我开始逐渐避免撞车之前,我没有必要经历几次撞车撞墙的经历。


相反,我还要强调一点,在许多游戏中,“策略梯度”很容易击败人类。尤其是,具有频繁奖励信号,需要精确游戏,快速反应且不需要太多长期计划的任何事物都是理想的,因为这种方法很容易“注意到”奖励和行动之间的这些短期关联。政策精心执行。您可以在我们的Pong代理中看到这种情况的提示:它制定了一种策略,先等待球,然后快速冲破以将其捕获在边缘,然后以很高的垂直速度将其快速发射。代理重复执行此策略可连续得分。在很多ATARI游戏中,深度Q学习都以这种方式破坏了人类的基线表现,例如弹球,突破,
总之,一旦您了解了这些算法的“技巧”,就可以通过它们的优缺点进行推理。特别是,我们在构建抽象的,丰富的游戏表示形式方面远非人类,我们可以在其中进行计划并用于快速学习。有一天,一台计算机将看到一组像素并注意到一把钥匙,一扇门,然后自己想到,拿起钥匙并到达门可能是一个好主意。到目前为止,没有什么比这更接近了,要到达那里是一个活跃的研究领域。
神经网络中的不可微计算
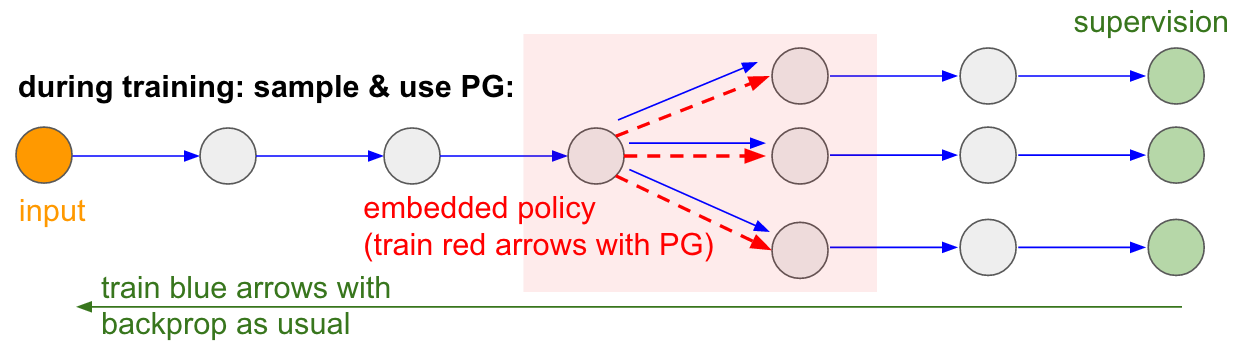
我想提到与游戏无关的策略梯度的另一个有趣应用:它允许我们设计和训练具有执行不可微计算(或与不可微计算进行交互)的组件的神经网络。这个想法最初是在Williams 1992年提出的,最近又被Recurrent Model of Visual Attention推广。以“强烈关注”的名称命名,该模型以处理一系列具有低分辨率中央凹眼(由我们自己的人眼启发)的图像为背景。特别是,在每次迭代中,RNN都会接收一小幅图像并采样一个位置以供下一步查看。例如,RNN可能会查看位置(5,30),接收一小幅图像,然后决定查看(24,50),依此类推。这个想法的问题是,存在一个网络会产生一个分布下一个要看的地方,然后从中取样。不幸的是,该操作是不可微分的,因为从直观上讲,我们不知道如果采样其他位置会发生什么。更一般地,考虑从一些输入到输出的神经网络:

请注意,大多数箭头(蓝色)可以正常区分,但是某些表示转换也可以选择包括不可微分的采样操作(红色)。我们可以通过蓝色箭头反向传播,但红色箭头表示我们无法反向传播的依赖项。
应对政策倾斜!我们将网络中作为抽样的一部分作为嵌入到更广泛网络中的小型随机策略进行考虑。因此,在训练过程中,我们将产生几个样本(由下面的分支指示),然后我们鼓励最终导致良好结果的样本(在这种情况下,例如,根据最终的损失进行衡量)。换句话说,我们将像往常一样使用反向传播训练蓝色箭头所涉及的参数,但是红色箭头所涉及的参数现在将使用策略梯度独立于后向传递进行更新,从而鼓励了导致低损失的样本。最近在使用随机计算图进行梯度估计中也很好地形式化了此想法。
训练的内存I / O。您还会在其他许多论文中找到这个想法。例如,一台神经图灵机有一个存储磁带,供他们读取和写入。要执行写操作,您希望执行RNN控制器网络预测的m[i] = x,,i和这样的操作x。但是,此操作是不可微分的,因为没有信号告诉我们如果我们要写到另一个位置会对损失造成什么影响j != i。因此,NTM必须执行软读取和写入操作。它可以预测注意力分布a(元素在0到1之间,总和为1,并且在我们要写入的索引周围达到峰值),然后执行for all i: m[i] = a[i]*x。现在这是可区分的,但是我们必须付出沉重的计算代价,因为我们必须触摸每个存储单元才可以写入一个位置。想象一下,如果我们计算机中的每个作业都必须触及整个RAM!
但是,我们可以使用策略梯度来规避此问题(理论上),就像RL-NTM一样。我们仍然可以预测注意力分布a,但是我们不会进行软写,而是对要写入的位置进行采样i = sample(a); m[i] = x。在训练期间,我们会针对一小部分进行此操作,i最后使最有效的分支工作更有可能。最大的计算优势在于,我们现在只需要在测试时在单个位置进行读取/写入。但是,正如本文所指出的那样,这种策略很难实现,因为必须通过采样有效地运行算法,才能偶然发现这种策略。当前的共识是,PG仅在存在一些离散选择的环境中才能很好地工作,因此不会无可避免地通过巨大的搜索空间进行采样。
但是,有了Policy Gradients,并且在有大量数据/计算可用的情况下,我们原则上可以实现更大的梦想-例如,我们可以设计学习与大型不可区分的模块(例如Latex编译器)进行交互的神经网络(例如,如果您想要char-rnn生成可编译的乳胶),SLAM系统或LQR求解器等。或者,例如,超级智能可能想要学习通过TCP / IP与Internet进行交互(这是不可区分的),以访问控制整个世界所需的重要信息。这是一个很好的例子。
结论
我们看到“策略梯度”是一种功能强大的通用算法,例如,我们使用原始的像素(从头开始)在130行Python中训练了ATARI Pong代理。更普遍地讲,相同的算法可用于训练任意游戏的代理,并希望有一天能够解决许多有价值的现实世界控制问题。我想在结束时再添加一些注意事项:
关于推进AI。我们看到,该算法通过蛮力搜索工作,您首先会在周围随机晃动,并且必须偶然偶然发现至少一次(理想情况下是反复多次),在策略分配改变其参数以重复执行负责任的操作之前,会反复出现有益的情况。我们还发现,人类在处理这些问题上的方式大不相同,在感觉上更像是快速建立抽象模型-尽管我们几乎没有涉足研究领域(尽管许多人正在尝试)。由于这些抽象模型很难(如果不是不可能)进行显式注释,因此这也是为什么最近对(无监督的)生成模型和程序归纳感兴趣的原因。
在复杂的机器人设置中使用。该算法不能天真地扩展到难以获得大量勘探的设置。例如,在机器人环境中,一个人可能只有一个(或几个)机器人,可以实时与世界互动。正如我在本文中介绍的那样,这禁止了该算法的朴素应用。确定性策略梯度是旨在缓解此问题的一项相关工作- 确定性策略梯度是使用确定性策略并直接从第二个网络直接获取梯度信息(称为“随机性”策略,而不是要求随机策略样本并鼓励获得更高分数的样本)。一个评论家)来模拟得分函数。从原理上讲,这种方法可以在具有高维度动作的环境中更加高效,在这种情况下,采样动作提供的覆盖率很差,但是到目前为止,从经验上讲,它有点难以适应。另一个相关的方法是扩大机器人技术,就像我们开始在Google的机械臂农场甚至是Tesla的Model S + Autopilot中看到的那样。
还有一条工作线试图通过增加额外的监督来使搜索过程变得更没有希望。例如,在许多实际情况下,人们可以从人类那里获得专家的轨迹。例如,AlphaGo首先使用监督学习来预测专家Go游戏中的人为举动,然后根据策略上的获胜的“真实”目标对最终的模仿人策略进行微调。在某些情况下,专家轨迹可能较少(例如,来自机器人远程操作的专家轨迹),并且在学徒学习的保护下,有一些可以利用此数据的技术。最后,如果没有人提供监督数据,在某些情况下也可以使用昂贵的优化技术来计算,例如通过
论PG在实践中的应用。最后,我想做一些我希望在RNN博客文章中所做的事情。我想我可能给人的印象是RNN很神奇,可以自动处理任意顺序问题。事实是,要使这些模型正常工作可能会很棘手,需要谨慎和专业知识,而且在许多情况下也可能是一种矫kill过正,在这种情况下,更简单的方法可以使您获得90%以上的收益。“策略梯度”也是如此。它们不是自动的:您需要大量示例,并且需要永久训练,当不起作用时很难调试。在到达火箭筒之前,应始终尝试使用BB枪。例如,在强化学习的情况下,应始终首先尝试的一个强基准是交叉熵方法(CEM)一种简单的随机爬山“猜测”方法,受到进化的启发。并且,如果您坚持尝试解决问题的“策略梯度”,请确保您密切注意论文中的技巧部分,首先简单开始,然后使用一个称为TRPO的PG变体,该变体在性能上总是比香草PG更好,更一致。练习。核心思想是避免参数更新过多地改变您的策略,这是由于对一批数据的旧策略和新策略所预测的分布之间的KL差异进行了约束而导致的(而不是共轭梯度,这是最简单的实例化)可以通过进行线路搜索并沿途检查KL来实现此想法)。
就是这样!希望我能使您了解强化学习的现状,面临的挑战,并且如果您急于帮助推进RL,我邀请您在我们的OpenAI体育馆内进行:)直到下一次!


评论专区