
【强化学习】Q-Learning详解
案例学习
在本教程中,您将逐步了解座席如何在未知环境中在没有老师(无监督)的情况下通过培训学习。您会发现称为Q-learning 的强化学习算法的一部分。强化学习算法已被广泛用于许多应用程序,例如机器人技术,多智能体系统,游戏等。
您无需学习可以从许多书籍和其他网站上阅读的增强理论(请参阅参考资料中的更多参考资料),本教程将通过简单但全面的数值示例来介绍该概念。您也可以免费下载Matlab代码或MS Excel电子表格。
假设一栋建筑物中有5个房间,通过某些门相连,如下图所示。我们给从A到E的每个房间命名。我们可以将建筑物外部视为覆盖建筑物的一个大房间,并将其命名为F。请注意,从F到建筑物有两扇门通向建筑物B。和房间E。
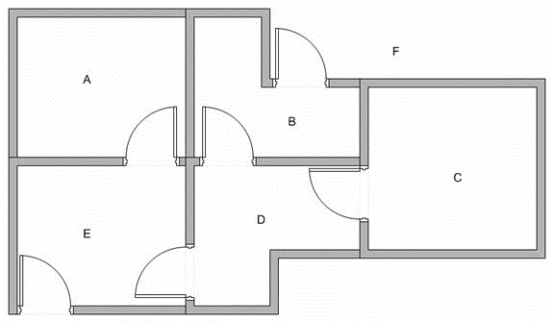
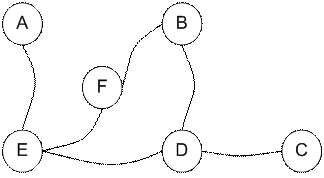
我们要设置目标房间。如果我们将代理商放置在任何房间中,我们希望代理商离开建筑物。换句话说,目标房间是节点F。为设置这种目标,我们为每个门(即图的边缘)引入一种奖励值。立即通往目标的门具有100点的即时奖励(见下图,它们带有红色箭头)。与目标房间没有直接连接的其他门的奖励为零。因为门是双向的(从A可以转到E,从E可以返回到A),所以我们为前一个图形的每个房间分配了两个箭头。每个箭头都包含一个即时奖励值。该图变为状态图,如下所示
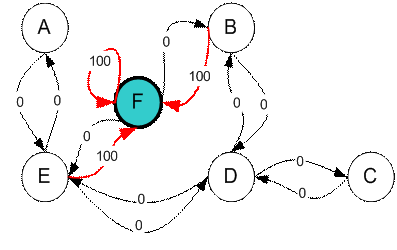
具有最高奖励(100)的附加循环被分配给目标房间(从F返回到F),以便如果业务代表到达目标,它将永远在那里。这种类型的目标称为吸收性目标,因为当达到目标状态时,它将保持在目标状态。
女士们,先生们,现在是时候介绍我们的超级明星经纪人…。
想象我们的代理人是一个可以通过经验学习的愚蠢的虚拟机器人。代理可以将一个房间传递到另一个房间,但不了解环境。它不知道代理商必须通过哪个门顺序才能走出建筑物。
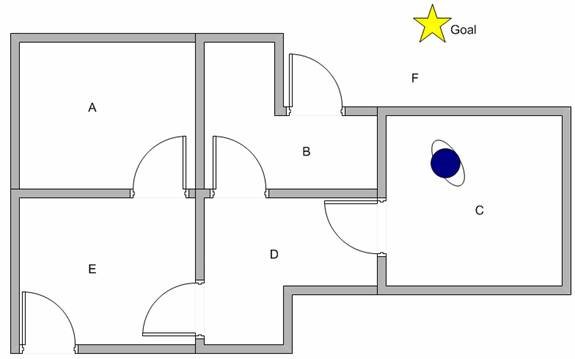
假设我们要对从建筑物中任何房间进行的某种简单的人员疏散建模。现在假设我们在C室有一个特工,我们希望该特工学会到达房屋(F)的外面。(参见下图)
如何使我们的经纪人从经验中学习?
在下一节讨论代理如何学习(使用Q学习)之前,让我们讨论状态和动作的一些术语。
我们称每个房间(包括建筑物外)为州。特工从一个房间到另一个房间的移动称为动作。让我们回顾一下状态图。在状态图中使用节点描述状态,而用箭头表示动作。
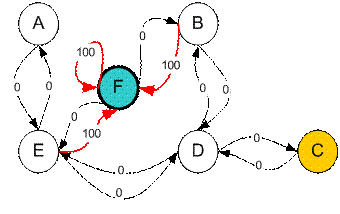
现在假设代理处于状态C。由于状态C连接到D,所以代理可以从状态C进入状态D。但是,由于没有直接的门连接,代理不能从状态C直接进入状态B。 B和C室(因此,没有箭头)。代理可以从状态D转到状态B或状态E,也可以返回状态C(请查看状态D之外的箭头)。如果代理处于状态E,那么三个可能的动作是进入状态A,状态F或状态D。如果代理处于状态B,则它可以进入状态F或状态D。从状态A开始,它只能回到状态E。
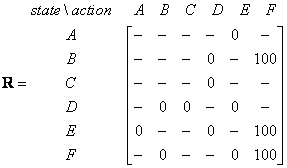
我们可以将状态图和即时奖励值放入下面的奖励表或矩阵R中。
行动状态 | ||||||
代理现处于状态 | 一种 | 乙 | C | d | Ë | F |
一种 | -- | -- | -- | -- | 0 | -- |
乙 | -- | -- | -- | 0 | -- | 100 |
C | -- | -- | -- | 0 | -- | -- |
d | -- | 0 | 0 | -- | 0 | -- |
Ë | 0 | -- | -- | 0 | -- | 100 |
F | -- | 0 | -- | -- | 0 | 100 |
表中的减号表示行状态没有任何动作可转到列状态。例如,状态A不能进入状态B(因为没有门连接房间A和B,还记得吗?)
在本教程的前面各节中,我们为代理商的环境和奖励系统建模。本节将介绍称为Q学习(简化学习)的学习算法。
我们已将环境奖励系统建模为矩阵R。
现在,我们需要在代理人的大脑中放入相似的矩阵名称Q ,以表示该代理人通过许多经验中学到的知识的记忆。矩阵Q的行表示代理的当前状态,矩阵Q的列指向要进入下一个状态的动作。
首先,我们说代理不知道任何东西,因此我们将Q 设为零矩阵。在此示例中,为了简化说明,我们假设状态数是已知的(六个)。在更一般的情况下,可以从单个单元格的零矩阵开始。如果找到新状态,则在Q 矩阵中添加更多列和行是一项简单的任务。
Q学习的过渡规则是一个非常简单的公式
![]()
上面的公式的含义是,矩阵Q 中的条目值(即行代表状态,列代表动作)等于矩阵R的相应条目,乘以学习参数
![]()
我们的虚拟代理将在没有老师的情况下通过经验进行学习(这称为无监督学习)。代理将探索状态,直到达到目标。我们称每次探索为一集。在一个情节中,特工将从初始状态移动到目标状态。代理到达目标状态后,程序将转到下一个情节。以下算法已被证明是收敛的(请参见参考证明)
Q学习
给定:具有目标状态的状态图(由矩阵R 表示)
查找:从任何初始状态到目标状态的最小路径(由矩阵Q 表示)
Q学习算法如下
结束做 结束于 |
代理使用以上算法从经验或培训中学习。每集相当于一个训练课。在每次培训课程中,代理都会探索环境(由Matrix R 表示),获得奖励(或无奖励),直到达到目标状态。培训的目的是增强以Q 矩阵表示的代理商的“大脑” 。更多的训练将提供更好的Q 矩阵,代理可以使用它以最佳方式移动。在这种情况下,如果Q 矩阵得到了增强,则座席将找到到达目标状态的最快路线,而不是四处探索并在同一房间中来回走动。
参数的
![]()
![]()
![]()
![]()
要使用Q 矩阵,代理会跟踪从初始状态到目标状态的状态序列。该算法与查找使当前状态的最大Q的动作一样简单:
利用Q矩阵的算法 输入:Q 矩阵,初始状态
|
上面的算法将返回从初始状态到目标状态的当前状态顺序。
为了理解Q 学习算法的工作原理,我们将通过几个步骤进行数值示例。可以使用该程序确认其余步骤(您可以免费下载本教程的MS Excel或Matlab代码伴侣)
让我们将学习参数和初始状态的值设置
![]()
首先,我们将矩阵Q 设置为零矩阵。

为了方便起见,我再次在此处放置表示环境的即时奖励矩阵R。
查看矩阵R 的第二行(状态B)。当前状态B有两种可能的动作,即进入状态D或进入状态F。通过随机选择,我们选择进入F作为我们的状态。行动。
现在我们假设我们处于状态F。看一下奖励矩阵R 的第六行(即状态F)。进入状态B,E或F有3种可能的动作。
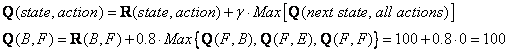
由于矩阵Q 仍为零,
![]()
![]()
下一个状态是F,现在成为当前状态。因为F是进球状态,所以我们完成了一集。我们的特工的大脑现在包含更新的矩阵Q 为

对于下一个情节,我们从初始随机状态开始。例如,这一次我们将状态D作为初始状态。
看矩阵R 的第四行;它有3种可能的动作,即进入状态B,C和E。通过随机选择,我们选择进入状态B作为我们的动作。
现在我们想象我们处于状态B。看一下奖励矩阵R 的第二行(即状态B)。它有2种可能的动作进入状态D或状态F。然后,我们计算Q 值
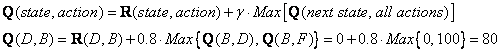
我们使用上一集的更新矩阵Q。和。由于奖励的计算结果为零。该Q 矩阵变
![]()
![]()
![]()

下一个状态是B,现在成为当前状态。我们重复Q学习算法中的内部循环,因为状态B不是目标状态。
对于新循环,当前状态为状态B。为方便起见,我再次复制表示即时奖励矩阵R 的状态图。
当前状态B有两种可能的动作,即进入状态D或进入状态F。通过幸运抽奖,我们选择的动作为状态F。
现在我们想到状态F有3种可能的动作进入状态B,E或F。我们使用这些可能动作的最大值来计算Q值。
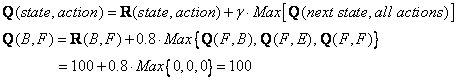
更新后的Q矩阵的条目
![]()
![]()
因为F是目标状态,所以我们完成了这一集。我们的特工的大脑现在包含更新的矩阵Q 为
如果我们的特工通过许多情节学习到越来越多的经验,它将最终达到Q矩阵的收敛值,即

然后,可以将该Q 矩阵归一化为一个百分比,方法是将所有有效条目除以最大数量(在这种情况下为500)除以
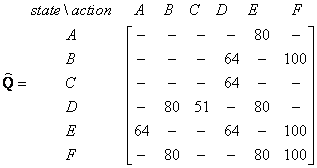
一旦Q矩阵几乎达到收敛值,我们的代理商便可以最佳方式达到目标。为了追踪状态序列,它可以通过找到使该状态达到最大Q的动作轻松地进行计算。
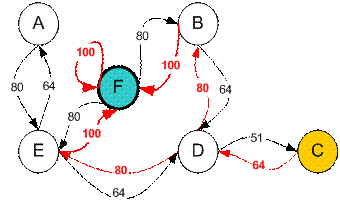
例如,从初始状态C开始,它可以使用Q矩阵,如下所示:
从状态C到最大Q产生动作进入状态D
从状态D,最大Q有两种选择可以进入状态B或E。假设我们选择任意进入状态B
从状态B最大值产生动作进入状态F
因此,顺序为C – D – B – F


评论专区
不错的帖子,值得收藏!http://7r8.pistpyh.cn
十分赞同楼主!http://164.siwangting.com
大神就是大神,这么经典!http://qivv.tjjixi.com
楼主你想太多了!http://q19.yipin112.com.cn
楼主内心很强大!http://0ea.baidacar.cn
感觉不错!http://19u5g.baidacar.cn
有内涵!http://www.idynsh.com
很有看点!http://6rvdmo.baidacar.cn
今天过得很不爽!http://cqyda.honda-taiwan.com/l/3.html