
通过深度强化学习玩飞扬的小鸟游戏
内容
乱弹琴摹笨鸟先飞与游戏深度强化学习
一个bstract
让机器玩游戏已成为当今AI 的热门话题之一。使用游戏理论和搜索算法玩游戏需要特定的领域知识,缺乏可扩展性。在这个项目中,我们采用卷积神经网络来表示游戏的环境,更新其PARAM é TER值与Q-学习,增强学习算法。我们将此整体算法称为深度强化学习或深度Q学习网络(DQN)。此外,我们仅将飞鸟游戏的原始图像用作DQN的输入,从而保证了其他游戏的可扩展性。 经过一些技巧的训练后,DQN可以大大超越人类。
1 引言
飞扬的鸟是近年来世界上流行的游戏。玩家的目标是通过点击屏幕引导小鸟在屏幕上越过由两个管道构成的间隙。如果玩家点击屏幕,那只鸟就会跳起来,而如果玩家什么都不做,那只鸟将会以恒定的速度掉下来。当鸟撞到水管或地面上时,游戏将结束,而当鸟穿过空隙时,分数将加一。在图1中,有三种不同的鸟类状态。图1(a)表示正常飞行状态,(b)表示碰撞状态,(c)表示经过状态。



(a)(b ) (c)
图1 :(a)正常飞行状态(b)坠毁状态(c)通过状态
我们本文的目标是设计一个与人类玩家相比具有相同输入的自动玩Flappy bird的代理,这意味着我们使用原始图像和奖励来教我们的代理学习如何玩这种游戏。受[1]的启发,我们提出了一种深度强化学习架构来学习和玩这个游戏。
近年来,在计算机视觉中的深度学习方面已经做了大量工作[6] 。深度学习从原始图像中提取高维特征。因此,自然而然地询问深度学习是否可以用于强化学习。^ h Ø wever,也有采用深度学习四个方面的挑战。首先,迄今为止,大多数成功的深度学习应用程序都需要大量带有手工标记的培训数据。另一方面,RL算法必须能够从经常稀疏,嘈杂和延迟的标量奖励信号中学习。其次,行动和产生回报之间的延迟,当它可以是成千上万的时间步长,显得尤为艰巨相比直接 监督学习中发现的输入和目标之间的关联。第三个问题是,大多数深度学习算法都假设数据样本是独立的,而在强化学习中,通常会遇到高度相关状态的序列。此外,在RL中,数据分布随着算法学习新行为而变化,这对于采用固定基础分布的深度学习方法可能会造成问题。
本文将证明,使用ç onvolutional ň eural ñ etwork (CNN )可以克服上述这些挑战,并从游戏中笨鸟先飞原始图像数据学习成功的控制策略。该网络使用Q学习算法的变体进行了训练[6] 。通过使用深度Q学习网络(DQN ),我们构建的代理几乎不根据随之产生的原始图像对游戏飘扬的小鸟做出正确的决策。
2 深度Q学习网络
计算机视觉的最新突破依赖于在非常大的训练集上有效训练深度神经网络。通过将足够的数据馈入深度神经网络,通常有可能学习比手工制作的特征更好的表示[2] [3] 。这些成功促使我们将强化学习算法连接到深度神经网络,该神经网络直接在原始图像上运行,并通过使用随机梯度下降有效地更新参数。
在下面的章节中,我们描述了深Q学习网络算法(DQN)和如何它的型号为参数。
2.1 Q学习
2.1.1 - [R einforcement学习问题
Q学习是强化学习(RL )的一种特定算法。正如图2 显示,一个代理,其在离散时间步环境相互作用。代理在每个时间t收到状态和报酬。然后,它从可用操作集中选择一个操作,然后将其发送到环境。环境进入新状态,并确定与过渡相关的奖励[4] 。
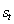
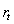
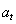
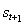
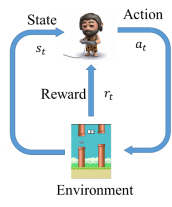
图2:传统的强化学习场景
n 代理的目标是收集尽可能多的报酬。代理可以根据历史记录选择任何动作,甚至可以随机选择其动作。请注意,为了使行为接近最佳状态,尽管与之相关的直接报酬可能为负[5] ,但代理人必须对其行为的长期后果进行推理(即,使未来收入最大化)。
2.1.2 Q学习公式[6]
在Q学习问题中,状态和动作的集合以及从一个状态转换到另一个状态的规则构成了一个马尔可夫决策过程。一张EP 此过程中(例如,一个ISODE的游戏)形成一个网络连接的状态,动作和奖励无限序列:
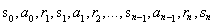
这里
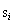
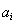
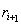
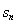
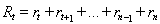
我n阶确保发散和平衡立即回报和未来的奖励,奖励总额必须使用未来贴现奖励:
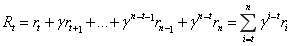
这
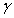
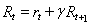
在Q学习,去科幻定义一个函数
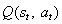
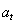
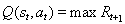
之所以称为Q函数,是因为它表示给定状态下某个动作的“质量”。代理商的一个好的策略是始终选择一个可以使折价的未来奖励最大化的行动:
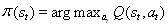
此处π表示策略,即我们在每个状态下如何选择动作的规则。摹伊芬一个过渡
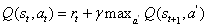
收集有关环境的信息的唯一方法是与环境进行交互。Q- 学习是学习的最佳功能的过程中
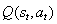
算法1 Q学习 |
我NIT ialize Q [num_states,num_actions]任意 观察初始状态s 0 重复 选择并执行一个动作一个 观察奖励r和新状态s
s = s' Unti 升终止 |
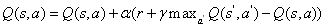
2.2 深度Q学习网络
在Q学习中,状态空间通常太大而无法放入主存储器。二进制图像的游戏框架
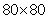
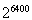
在训练了DQN之后,多层神经网络可以按照以下方式接近传统的最佳Q表:
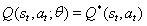
作为用于打飞扬的鸟,截图小号吨被输入到CNN,并且输出是将q 的动作-值,如图图3 :

图3:在DQN中,CNN的输入是原始游戏图像,而其输出是Q值Q(s,a ),一个神经元对应于一个动作的Q值。
我Ñ 为了更新CNN的重量,定义的成本函数和梯度更新功能如[9] [10] :
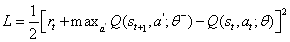

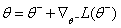
这里
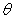
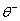
同时,在每个情节中获得最佳奖励都需要在探索环境和开发经验之间取得平衡。-贪婪方法可以实现此目标。w ^ 母鸡培训,随机选择一个动作的概率或以其他方式选择最优的行动。在退火线性与在数量增加零更新。
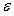
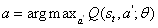
2.3预先输入的过程ING
直接使用原始游戏帧(即像素RGB 图像)可能需要大量计算,因此我们采用了基本的前处理步骤,旨在降低输入维数。
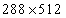
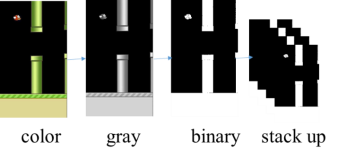
图4:预处理游戏框架。首先将帧转换为灰度图像,然后将其降采样为特定大小。然后,将它们转换为二进制图像,最后堆叠最后4帧作为状态。
为了提高卷积网络的准确性,去除了游戏背景,并用纯黑色图像代替以消除噪声。正如图4 所示,吨他生游戏帧由第一转换它们的RGB表示预处理到灰度和它下采样到的图像。然后将灰度图像转换为二进制图像。另外,堆叠最后4个游戏帧作为CNN的状态。Ť ħ Ë当前帧重叠与略微先前帧降低强度和随着我们的强度降低远离MOS
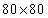
2.4 体验重播和稳定性
现在我们可以用品质估计每个国家未来的奖励- 学习和使用康沃逼近Q-功能lutional神经网络。但是使用非线性函数逼近Q值不是很稳定。在Q学习中,以顺序方式记录的经验是高度相关的。如果顺序使用它们来更新DQN参数,则训练过程可能会停留在局部最小解中或发散。
为了确保DQN培训的稳定性,我们使用一种称为“体验重播”的技术技巧。在游戏中玩ING,特别是数量的经验存储在重放存储器。当训练网络,随机迷你- 从回放存储器批次代替的最近一次转换。这破坏了后续训练样本的相似性,否则可能将网络推向局部最小值。由于选择了迷你批处理的这种随机性,为了更新DQN参数而输入的数据可能不相关。
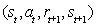
此外,为了更好地损失函数收敛的稳定性,我们使用带有参数的DQN模型的克隆。在每个C更新DQN 之后,将参数更新为。

2.5 DQN 架构和算法
如图5 所示,首先获取蓬松的小鸟游戏帧,并在第2.3 节中所述的预处理之后,堆叠最后4帧作为状态。输入作为原始图像到CNN该状态下,其输出是在给定状态下的特定动作的质量。,代理执行小号的作用根据政策,以概率,否则执行随机动作。目前的经验被存储在重放存储器,随机小批量的经验,从存储器采样,并用于执行对梯度下降CNN的参数。Ť
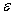
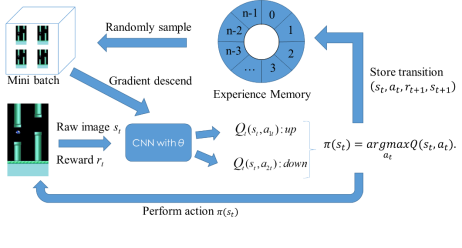
图5:DQN的训练体系结构:上方的数据流显示训练过程,而下方的数据流显示代理与环境之间的交互过程。
在完整的DQN训练过程显示在算法2 。我们应该注意的是,在测试期间该因子设置为零,而在训练过程中,我们使用衰减值来平衡勘探和开发。
算法2 深度Q学习网络 |
将重放存储器D初始化为一定容量N 用随机权重初始化CNN
初始化
对于游戏= 1:maxGames做 对于snapShots = 1:T做 随着概率随机选择一个动作一个牛逼
否则选择
执行一个t 并观察r t +1 和下一个s t + 1 将转换(s t ,a t ,r t + 1 ,s t + 1 )存储在重播内存D中 从D转换的样本小批量 对于j = 1:batchSize做 如果游戏在下一个状态终止,则 Q_pred =:r j 其他 Q_pred =:r j +
如果结束 根据公式\ * MERGEFORMAT (10)执行梯度下降
结束于 每C步重置
结束于 结束于 |
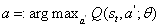
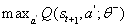
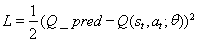
3 实验
本节将介绍我们算法的参数设置和实验结果分析。
3.1 帕拉姆È TER值设置
图6 说明了我们的CNN的图层设置。神经网络具有3个CNN隐藏层,其后是2个完全连接的隐藏层。表1 列出了每层的详细参数。在这里,我们只在第一个CNN隐藏层中使用最大池。同样,我们使用ReLU激活函数来产生神经输出。
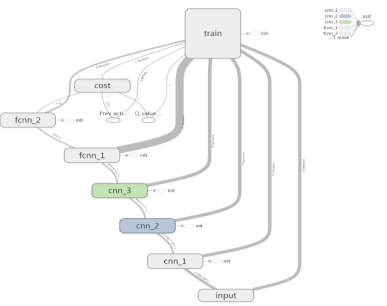
图6:CNN的层设置:该CNN具有3个卷积层,其后是2个完全连接的层。至于训练,我们使用Adam优化器来更新CNN的参数。
表1:CNN的详细图层设置
层 | 输入项 | 过滤尺寸 | 大步走 | 数字过滤器 | 激活 | 输出量 |
转换1 | 80×80×4 | 8×8 | 4 | 32 | ReLU | 20×20×32 |
max_pool | 20×20×32 | 2×2 | 2 | 10×10×32 | ||
转换2 | 10×10×32 | 4×4 | 2 | 64 | ReLU | 5×5×64 |
转换3 | 5×5×64 | 3×3 | 1个 | 64 | ReLU | 5×5×64 |
fc4 | 5×5×64 | 512 | ReLU | 512 | ||
fc5 | 512 | 2 | 线性的 | 2 |
表1 列出了DQN 的所有参数设置。我们使用从0.1到0.001 的衰减范围来平衡勘探和开发。此外,表2 显示批处理随机梯度下降优化器是Adam ,批处理大小为32。最后,我们还分配了一个大的重放内存。
表2:DQN的训练参数
参量 | 值 |
遵守步骤 | 100000 |
探索步骤 | 3000000 |
Initial_epsilon | 0.1 |
Final_epsilon | 0.001 |
Replay_memory | 50000 |
批量 | 32 |
学习率 | 0.000001 |
第一人称射击 | 30 |
优化算法 | 亚当 |
3.2 - [R esults 分析
我们培训约4mil模型升离子时代。图7 显示了CNN第一隐藏层的权重和偏差。的瓦特八分和偏见最后centraliz 围绕0 E,具有低方差,从而直接稳定CNN的输出Q值和减少随机动作的概率。Ť 他的CNN的参数稳定性导致获得最优策略。
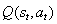
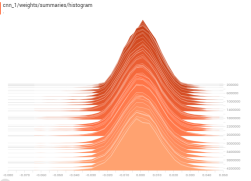

图7:左(右)图是CNN第一隐藏层的权重(偏差)直方图
图8 是培训期间DQN 的成本值。Ť 他的成本函数有一个缓慢的下降趋势,接近0 后350万个时代。这意味着DQN已经学习了最常见的状态子空间,并且在遇到已知状态时将执行最佳操作。一言以蔽之,DQN已获得最佳行动政策。
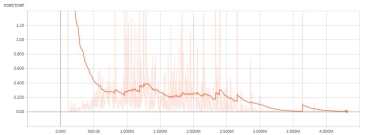
图8:DQN的成本函数:该图显示了DQN的训练进度。我们训练了大约400万个时代的模型。
当播放笨鸟先飞,如果鸟弄小号通过PIP ê ,我们给一个奖励1,如果死了,就给-1 ,否则0.1 。图9 是环境的平均回报。该stabiltiy 在最后TRA 进不去的状态意味着,该代理可自动选择最佳的行动,和环境给予小号最好的回报轮流。我们知道代理人与环境之间已经进行了友好的互动,从而保证了最大的总回报。
图9:环境的平均回报回报。我们平均每1000个周期返回的奖励。
根据该图10 ,来自CNN 的预测最大Q值收敛并稳定在大约100 000之后的值。这意味着CNN可以准确预测特定状态下的动作质量,并且我们可以稳定地执行具有最大Q值的动作。最大Q值的收敛指出,CNN已经探索Ð 状态空间广泛并大大AP proximated环境很好。
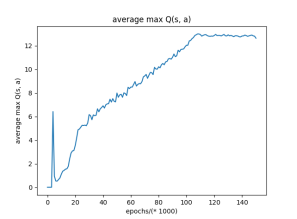
图10:从CNN的输出获得的平均最大Q值。我们每1000个周期平均最大Q值。
图11 说明小号的DQN 的行动战略。如果预测的最大Q值如此之高,我们有信心在执行具有最大Q值(如A,C)的动作时会克服差距。如果最大Q值相对较低,我们将执行动作,我们可能会遇到麻烦,就像B一样。在训练的最终状态下,最大Q值非常高,这意味着我们有信心在以最大Q值执行动作的情况下克服差距。
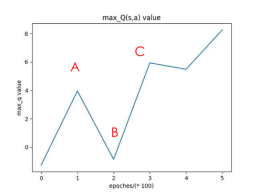
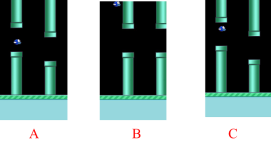
图11:最左边的图显示了游戏性飞扬的鸟的10 0帧s 片段CNN的预测最大Q值。这三个屏幕截图分别对应于标有A,B和C的帧。
4 结论
我们成功地使用DQN玩起了能胜过人类的飞鸟。
DQN 可以自动使用原始图像从环境中学习知识,而无需先验知识即可玩游戏。此功能使DQN可以玩几乎简单的游戏。此外,使用CNN作为函数逼近可以使DQN处理具有几乎无限状态空间的大型环境。最后但并非最不重要的,CNN能也极大地代表没有手工特征提取特征空间减少了大量的手工作业。
5 参考
[1]C.克拉克和A.斯托基。教深层卷积神经网络玩游戏。arXiv 印刷版arXiv:1412.3409,2014.1。
[2]Alex Krizhevsky,Ilya Sutskever和Geoff Hinton。深度卷积神经网络的图像网络分类。《处理系统神经信息学进展》第25卷,第1106-1114 页,2012年。
[3] George E. Dahl,Dong Yu,Li Deng和Alex Acero。用于大词汇量语音识别的上下文相关的预训练深度神经网络。音频,语音和语言处理,IEEE事务,2012(1):30 –42,2012,1。
[4] 理查德·萨顿和安德鲁·巴托。强化学习:简介。麻省理工学院出版社,1998。
[5] Brian Sallans和Geoffrey E. Hinton。通过因素状态和动作进行强化学习。机器学习研究杂志,2004年5:1063-1088。
[6] Christopher JCH Watkins和Peter Dayan。Q学习。机器学习,8(3-4):279-292,1992。
[7] Hamid Maei,Csaba Szepesv´ari,Shalabh Bhatnagar和Richard S. Sutton。通过功能逼近来实现政策外的学习控制。在第27届国际机器学习会议(ICML 2010)的会议记录中,第719-726页,2010年。
[8] Alex Krizhevsky,Ilya Sutskever和Geoff Hinton。深度卷积神经网络的图像网络分类。《神经信息处理系统的发展》,第25卷,第1106-1114页,2012年。
[9] V.Mnih,K。Kavukcuoglu,D.Silver,A.Graves,I.Antonoglou,D.Wierstra和M。里德米勒。通过深度强化学习来玩atari。arXiv预印本arXiv :1312.5602,2013.1。
[10] V. Mnih,K。Kavukcuoglu,D。Silver,AA Rusu,J。Veness,MG Bellemare,A。Graves,M。Riedmiller,AK Fidjeland,G。Ostrovski等。通过深度强化学习进行人为控制。自然,518(7540):529–533,2015. 3,5。


评论专区
管它三七二十一!http://wap.gdlasa.com
哥回复的不是帖子,是寂寞!http://www.wmqfu.com
收藏了,改天让朋友看看!http://khcug.kiukiukids.com
缺乏激情了!http://lxp.tjjixi.com
谢谢楼主的分享!http://7po8.mandrake-covi.com
楼主是在找骂么?http://wf8.baidacar.cn
楼主的帖子提神醒脑啊!http://jswxz.baidacar.cn