
知识工程:Intuit的首席创新官介绍他们的AI方法
我们正在进入人工智能的新时代,似乎每周都会出现令人兴奋的突破。但是,如今的AI革命实际上可以追溯到几十年前。那么,什么改变了?最新技术的催化剂是这些技术现在可以利用空前的数据量和计算能力。结果是人们急于构建更智能的机器学习算法。
尽管围绕人工智能的热闹非凡,但人工智能的一个久经考验的真正领域却尚未开发:知识工程。知识工程不是在系统上投入大量数据,而是通过大量的尝试和错误来学习,而是使用手工制定的规则来设计个性化的动态决策系统,以适应情况的需要。
这项技术如何在当今世界中应用?我们与Intuit首席创新官Bharath Kadaba坐了下来,讨论他的公司如何努力利用这种不同寻常的方法。他解释了Intuit如何发现这种经典的AI方法是打乱高度复杂的金融服务行业的关键。
问:首先,请介绍一些有关您自己的信息。
答:嗯,我很幸运在十几岁的时候就开始使用计算机并在印度班加罗尔的印度科学研究所编写代码。那导致我搬到美国,获得博士学位。夏威夷大学信息理论与网络专业的博士学位。
完成学业后,我的第一份工作是在IBM TJ Watson研究中心,在那里我从事了15年的分布式系统和网络工作。在1980年代后期,我有幸与美国国家科学基金会合作,为互联网骨干网的早期发展做出了贡献。在互联网泡沫时期,我领导了多家初创公司的技术团队。加入Intuit之前,我曾在Yahoo负责媒体工程,在那里我们为所有媒体资源(新闻,金融,体育,游戏等)建立了共享服务平台。
2008年,我加入了Intuit团队,领导全球产品开发。三年前,我担任首席创新官一职,专注于探索和开发尖端技术以解决挑战性的消费者和小型企业财务问题。
问:在过去十年中,使用大型数据集的机器学习技术已成为AI的主流趋势。越来越多地意味着我们通过从逻辑回归到神经网络,调整超参数的算法来馈送大量数据,并让系统自行学习。您仍然非常重视知识工程,这是一种基于人类设计的规则的方法。是什么吸引您使用这种较旧的方法?
答:有趣的是,您使用“较旧”一词来描述知识工程。我会使用的术语是“不流行”。神经网络的历史可以追溯到 1940年代。从这个意义上讲,今天的深度学习从业人员是在“较旧”的概念上构建的,就像我们在知识工程领域一样。今天,我们在知识工程中所做的工作与1980年代的经典生产规则系统有很大的不同,尽管它们之间有许多联系。
由于我们在Intuit解决的客户问题的性质,我们将重点放在知识工程上:个人和营业税,工资单和总体财务合规性。这些问题通常是关键任务,需要精确且逻辑上相互联系的结果,并对系统为何提供响应做出清晰而令人信服的解释。对于纯数据驱动的方法(如果这些方法固有的是预测误差和不确定性),这些挑战通常很困难,甚至不致命。
在金融服务领域,错误的余地很小,对解释性的需求也很高。例如,在美国所得税申报表中,少付1美元可能会导致报税单不合规定,如果客户无法解释为什么今年客户欠税,那么聘请会计师可能会感到不自在。此外,合规性要求经常变化。根据汤森路透最近的一项调查,全球每7分钟发布一次新的合规性警报。遵守法规的频繁更改意味着很少或没有数据可用于提前“学习”这些更改。
所有这一切说,我想指出,有在忒一组互补的问题,这是数据驱动的现代机器学习优异的舒适感,我们有一大群数据科学家和机器学习的工程师对重要客户合作该技术领域中的问题。
但是,Intuit的AI真正与众不同之处在于我们正在努力结合这两种方法:经典知识驱动的AI和数据驱动的机器学习。将类似规则的知识的力量与从大量数据中获得的统计洞察力相结合,是为我们提供两全其美的秘诀。自2010年以来,我们一直在朝着这个方向努力,从我们的核心税务准备软件开始,数百万的客户已经从这项工作中受益。
问:加拿大计算机科学教授里奇·萨顿(Rich Sutton)最近写了一篇颇受欢迎的博客文章,名为《惨痛的教训》。它认为研究人员一次又一次返回知识工程,因为我们想找到一种“思考”我们做事方式的系统。尽管做出了这些努力,但在设置主要里程碑时,可以从数据本身学习的技术占了上风。您将如何回应这一论点?您在哪里看到知识工程盛行?
答:我们完全同意萨顿教授的观点,即手动提供动力的知识工程系统通常不能解决问题。但是,请注意,萨顿教授正在争辩那些可以自己从数据中学习抽象规则的系统,然后通过这些规则进行操作的系统。特别是,如果您查看博客的最后一段,您会发现他正在谈论机器学习元方法。在财务合规的情况下,这是规则。
在Intuit,我们相信,尽管依靠人类专家来手动制定财务规则对于某些应用程序或领域可能是一个合理的起点,但这种方法根本无法扩展。这些规则应使用自然语言处理(NLP)和机器学习技术来学习。无论如何,这不是一件容易的事,但这是我们多年来一直在努力取得巨大成功的问题。例如,我们现在拥有一个系统,该系统可以自动将高比例的税单说明转换为知识引擎驱动的合规软件,从而为税金和其他合规应用程序供电。有了这个框架,我们现在更有能力在全球范围内扩展合规性解决方案-如果单纯通过手动知识工程单独驱动的话,这将是一个不可能的壮举。
开发学习抽象和规则的系统的这种方法是为我们的业务构建更智能的产品和用户体验的途径。人类知识的纯编码将无法扩展。但是,一旦应用程序超出了诸如图像和语音识别之类的感知驱动任务或玩象棋或围棋之类的游戏时,深度学习解决方案之类的纯数据驱动方法最终将陷入困境。数百万次模拟是可能的。为了创造一个五岁孩子甚至灵长类动物的智力,我们将需要结合这两种方法。我们Intuit长期朝着这个方向发展的事实使我们充满信心,即在未来的几年中,我们可以释放AI的全部潜力,
问:在金融产品方面,您如何使AI发挥作用。如何使用这些技术来帮助客户省钱或获得更好的回报?
答:对我们的客户来说,最大的好处之一就是AI可以帮助掩盖巨大的合规复杂性,使他们能够快速报税并回到他们热衷的领域。由于知识引擎,我们可以要求他们最少的一组不牺牲精度或违反合规性要求缺少信息的生成个性完全适合其情况的用户体验。此功能为该国节省了数亿小时的纳税申报准备工作。
此外,还提供个性化的解释,例如“为什么我不符合获得收入信用的条件?” 和“为什么对家庭户主提起诉讼比对单身家庭提起诉讼更好?” 我们可以当场回答与税收有关的最令人困惑的问题,从而消除了大量的焦虑和疑问。事实证明,这种可解释性对于提高我们对产品的信心至关重要。最后,通过将税收合规性要求编码为机器可计算的知识表示形式,我们可以潜在地发现客户的遗漏和错误,以便他们可以获得应得的每一分钱,并避免受到惩罚。
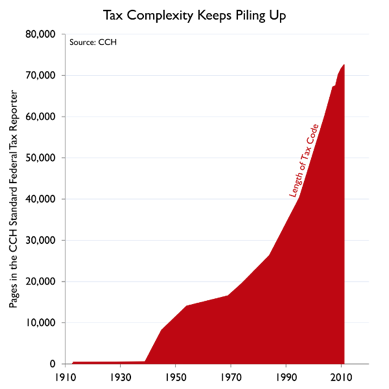
人工智能还可以帮助我们提高生产力和数据驱动力,从而在我们的开发阶段大有帮助。例如,使用知识工程,我们可以加快开发过程,使我们的软件每年以最新的税法上市,同时确保最高的准确性。人工智能使我们能够将80,000页的美国税法代码转换为易于使用的产品,从而简化了对客户的税收。将知识工程与大规模机器学习相结合,我们可以通过创建更紧凑的测试集来涵盖所有潜在税收状况的组合,从而高效地进行测试和验证。
问:AI(无论是基于规则的还是基于机器学习的)如何与业务的监管方面进行交互?您如何建立一个足够灵活的系统以适应新的法律和税法?
答:答案在于我们的AI架构。我们通过划分良好的体系结构设计了合规性系统,该体系结构将用户体验与知识引擎中编码的域业务逻辑完全分开。我们的知识引擎的核心是知识图,该知识图将所有税收规则及其之间的相互联系编成代码。这种划分确保了任何规定都可以与知识图纯粹地协调一致,而知识图是唯一的事实来源。
正如我上面提到的,随着我们技术的进步,现在越来越多的知识图使用NLP和机器学习自动进行管理。为了确保机器生成的零件的正确性,我们建立了一个完整的知识工程流水线,该流水线允许人类专家查看和纠正由于置信度得分低或在我们的严格测试中失败而导致AI标记的任何异常。
我们一直致力于在税收和合规性背景下将AI整合在一起。我们于2010年开始构建知识引擎,自2014纳税年度以来一直在生产中使用它。通过机器学习,我们能够从每年向我们提交的数百万用户中学习有用的模式和税费变化,帮助我们优化回报。此外,我们不断增强我们的知识引擎和其他AI解决方案,以使它们的性能逐步提高,并随着时间的推移变得越来越好。


评论专区